Spring Boot - DynamoDB!
DynamoDB
Intro DynamoDB
https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/Introduction.html
DynamoDB는 AWS 에서 제공하는 완전관리형 NoSQL 데이터베이스
AWS 관리 하에 다운타임 또는 성능 저하 없이 테이블의 처리 능력을 확장 또는 축소할 수 있음
핵심 구성 요소
DynamoDB 구성요소로 테이블, 항목, 속성이 있다.
항목과 속성을 RDB 로 아래와 같이 표현할 수 있다.
- 항목은 레코드 혹은 튜플
- 속성은 필드 혹은 열
또한 속성이 가질수 있는 타입으로는 스칼라(숫자, 문자열, 이진수, 부울 및 Null)와 중첩된 속성(객채형식) 이 있으며 최대 32 개 깊이까지 중첩 가능하다.
DynamoDB Standard 테이블과 DynamoDB Standard-IA(Infrequent Access) 테이블이 존재하는데
DynamoDB Standard 이 기본값이며 일반적인 데이터를 처리하는데 사용되며 IA 의 경우 로그 및 과거 성과 데이터 등 자주 엑세스 하지 않는 데이터를 저장하는데 사용된다.
DynamoDB 의 특이한점은 보통의 데이터베이스처럼 사용하는 포트가 따로 있는것이 아닌 HTTP 프로토콜을 사용한다는 것
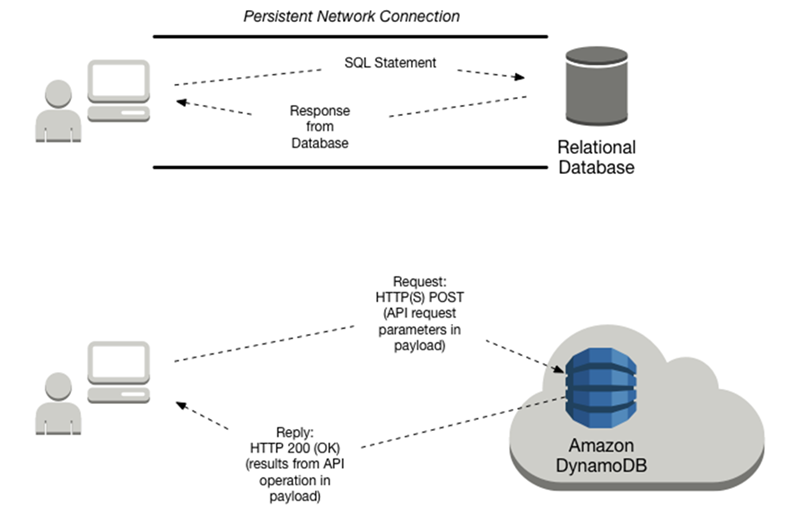
HTTP 에서 사용하는 인증방식, HTTP Status 에 결과 수신 등을 그대로 DynamoDB 에서 사용한다.
기본 키
NoSQL 인만큼 기본키 외에는 별도의 스키마가 존재하지 않는다.
테이블 생성시 고유 식별자 를 가져야 하는데 2종류로 나뉜다.
1. 파티션 키
DB에서 일반적으로 생각하는 단순 기본 키 를 가리키며 해시 함수 출력에 따라 항목을 저장할 물리적 파티션(SSD 스토리지)이 결정된다.
2. 복합 키
복합키로 부르는 이 형식은 파티션 키와 정렬 키로 구성된다.
해시 함수에 대한 입력으로 파티션 키 값을 기준으로 파티션을 나누고, 파티션 키 값이 동일한 모든 항목은 정렬 키 값을 기준으로 정렬되어 함께 저장된다.
여러 항목이 중복된 파티션 키 값을 가질수 있지만 동일한 파티션 내에서 다양한 정렬 키값을 가져야 한다.
파티션키를 해시속성 혹은 해시키, 정렬키를 범위속성 이라고 부르기도 함
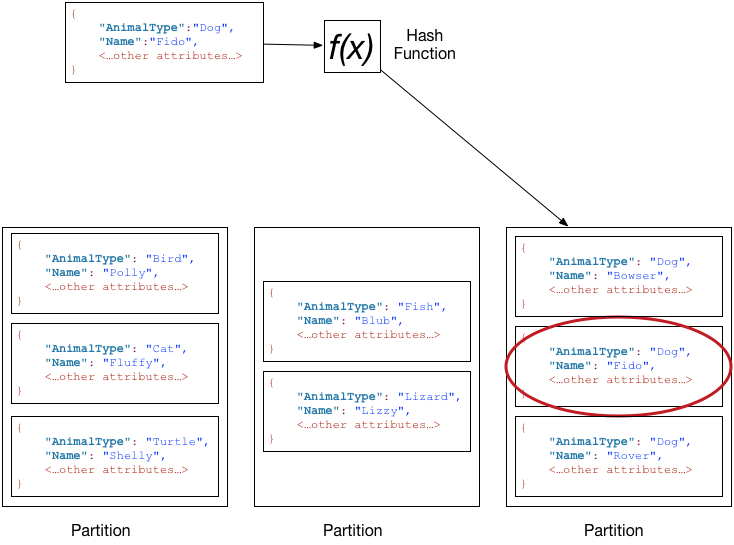
위 그림처럼 기본키를 AnimalType(파티션 키)와 Name(정렬 키)으로 구성된 복합 키로 가질 경우
파티션 키로 파티션을 찾고 정렬 키로 데이터 위치를 찾는다.
각 기본 키 속성은 스칼라여야 하며 문자열, 숫자 또는 이진수 가 포함된다.
보조 인덱스 (Secondary Index)
RDB 의 경우 인덱스를 생성해놓으며 쿼리 옵티마이저가 인덱스를 사용하여 최적의 방식으로 데이터를 조회하지만
DynamoDB의 경우 아예 인덱스를 사용하여 저장공간을 차별화 한다.
이때문에 인덱스 생성시 반드시 파티션 키 를 정의해야한다.
테이블당 하나 이상의 보조 인덱스(Secondary Index) 생성 가능하다.
보조 인덱스를 생성게 되면 데이터 access 방면에서 편리하다.
만약 보조 인덱스를 사용하지 않은 필드를 기준으로 조회쿼리를 사용하게 되면 Scan 작업(RDB 의 Full Scan) 이 일어나기에 좋지 않다.

예로 위 Music 테이블은 복합 키를 사용하는 테이블로, Aritst 를 파티션 키, SongTitle 을 정렬 키로 사용하는 테이블이다.
Music 테이블로부터 오른쪽의 GenreAlbumTitle 라는 보조 인덱스를 생성하였는데 생성되는 형식을 보면
Genre 는 파티션 키, AlbumTitle 은 정렬 키로 사용했고 원본 Music 의 복합 키를 가져왔다(프로젝션).
모든
보조 인덱스는 원본 테이블로부터 생성되며, 이 원본 테이블을 기본테이블 이라 한다.
이제 Genre 와 AlbumTitle 속성을 가지고도 Music 테이블 데이터를 쿼리할 수 있게 되었다.
AlbumTitle이 알파벳 H로 시작하는 모든 Country 앨범을 검색하는 조건을 지정할 수 도 있다.
물론 보조 인덱스를 사용하면 별도의 저장공간에 데이터를 저장하기에 실제 쓰는 데이터 용량보다 높은 비용이 발생할 수 있다.
인덱스의 생성 방식을 토대로 2종류로 나누는데 아래와 같다.
1. Global Secondary Index(GSI)
기본테이블에서 사용하는 파티션 키 및 정렬 키가 다른 인덱스 생성시 사용.
2. Local Secondary Index(LSI)
기본테이블의 파티션 키는 인데스의 파티션 키와 동일하지만 정렬 키가 다른 경우
테이블을 생성할 때에만 설정가능하며 생성 이후에는 추가, 삭제할 수 없음.
DynamoDB의 각 테이블에는 기본 할당량으로 GSI 20개, LSI 5개의 최대 할당량이 있으며 인덱스를 자동으로 유지 관리한다.
기본테이블에 항목을 추가, 변경하면 DynamoDB는 테이블의 모든 인덱스에서 해당 항목을 추가, 업데이트 또는 삭제된다.
아래는 PartiQL 를 사용하여 인덱스와 함께 테이블을 조회하는 쿼리이다.
# GSI 생성
CREATE INDEX GenreAndPriceIndex
ON Music (genre, price);
# 인덱스 사용 조회
SELECT *
FROM Music.GenreAndPriceIndex
WHERE Genre = 'Rock'
PartiQL
DynamoDB 에 저장된 데이터, 그중 테이블의 데이터 영역을 조회하기 위해 여러가지 방법이 있는데
클래식 CRUD API 를 호출하거나 PartiQL 언어를 사용해 데이터 영역을 CRUD 한다.
클래식 CRUD API 의 경우 REST API 형식과 유사하고
PartiQL 의 경우 RDBMS 에서 사용하면 SQL 언어와 유사하다.
또한 DynamoDB 는 트랜잭션 기능을 지원하는데 이때문에 아래 2가지 읽기 방식이 존재한다.
최종적 일관된 읽기(Eventually Consistent Read)
최근 완료된 쓰기 작업의 결과가 반영되지 않을 수 있다. 특히 GSI 의 경우 Async 로 운영되기에 데이터가 정확히 동기화 되지 않을 수 있다.
강력한 일관된 읽기(Strongly Consistent Read)
모든 쓰기 작업이 완료된 가장 최신 데이터를 포함하여 응답한다.
단 네트워크 지연 또는 중단이 발생할 경우 HTTP 500 에러가 반환되거나 속도가 지연될 수 있다.
또한 GSI 에서는 강력히 일관된 읽기가 지원되지 않는다.
PartiQL - Amazon DynamoDB용 SQL 호환 쿼리 언어 https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/ql-reference.html
RDB 에서 Music 테이블에 데이터를 넣으려면 아래 같은 SQL 문을 사용한다.
INSERT INTO Music
(Artist, SongTitle, AlbumTitle,
Year, Price, Genre,
Tags)
VALUES(
'No One You Know', 'Call Me Today', 'Somewhat Famous',
2015, 2.14, 'Country',
'{"Composers": ["Smith", "Jones", "Davis"],"LengthInSeconds": 214}'
);
DynamoDB 의 경우 정형화된 스키마가 없다보니 앞의 속성 관련 내용은 삭제되고 객체형태의 데이터를 바로 입력한다.
INSERT into Music value {
'Artist': 'No One You Know',
'SongTitle': 'Call Me Today',
'AlbumTitle': 'Somewhat Famous',
'Year' : '2015,
'Genre' : 'Acme'
}
요금
온디맨드, 프로비저닝됨 요금제가 존재하며 24 시간마다 변경 가능하다.
Dynamodb 에서는 읽고 쓰는 처리에 따라 처리량(WCU, RRU) 이라는 단위로 금액을 청구, 저장중인 용량을 토대로 금액을 청구한다.
또한 두 요금제별로 지정된 처리량 제한이 있으며 이를 초과하게될 경우 바로 500 에러를 반환하기에 철저한 성능 계산후 결정해야 한다.
최종적 일관된 읽기 의 경우 4KB, 강력한 일관된 읽기 의 경우 2KB, 쓰기의 경우 1KB 를 1회로 지정한다.
또한 읽거나 쓴 요량이 기본 단위 미만, 초과 경우 올림처리하여 계산한다.
온디맨드
온디맨드는 트래픽 예측이 불가능할 경우, 용량 계획 없이 많은 요청을 처리해야 할 경우 유용한 요금제이다.
초당 수천개의 요청을 한자리수 밀리초 지연시간을 제공하며 실제 데이터를 읽고 쓴 만큼 요금을 지불한다.
프로비저닝(기본값)
어플리케이션별로 초당 읽기/쓰기 횟수를 지정하여 사용하는 방식, 물론 Auto Scaling을 사용하여 트래픽 변경에 따라 테이블의 프로비저닝된 용량을 자동으로 조정할 수 있음
애플리케이션 트래픽이 예측 가능한 경우 사용한다. 용량에 대해 상한, 하한을 지정할 수 있으며 사용량을 선결제(예약) 하는등의 작업이 가능하다.
온 디멘드 기준 프리티어로 월 25GB 용량은 무료제공되며 추가 GB 당 0.25불, WCR, RRU 백만건당 1.3불, 0.3불 정도의 금액이 청구된다.
프로비저닝은 저장공간, 읽기, 쓰기 요청별로 과금됨, https://aws.amazon.com/ko/dynamodb/pricing/provisioned/
Spring with DynamoDB
DynamoDB 의 가장 큰 단점은 다른 DB 밴더보다 유용한 라이브러리가 적다는 것.
다행이 Spring Boot 에선 DynamoDB 사용을 위한 SDK, 그리고 해당 SDK 를 보다 쉽게 사용할 수 있도록 비공식 라이브러리인 Spring Data DynamoDB 를 사용할 수 있다.
# local 에서 DynamoDB 를 실행
docker run -d -p 8000:8000 amazon/dynamodb-local
# application.properties
spring.data.dynamodb.entity2ddl.auto=create-only
// @Bean
// public AWSCredentialsProvider awsCredentialsProvider() {
// return new DefaultAWSCredentialsProviderChain();
// }
// local-dynamodb 사용을 위한 설정
@Bean(name = "amazonDynamoDB")
public AmazonDynamoDB amazonDynamoDb(AWSCredentialsProvider awsCredentialsProvider) {
AmazonDynamoDB amazonDynamoDb = AmazonDynamoDBClientBuilder.standard()
.withCredentials(awsCredentialsProvider)
.withEndpointConfiguration(new AwsClientBuilder.EndpointConfiguration("http://localhost:8000", "ap-northeast-2"))
.build();
return amazonDynamoDb;
}
DynamoDB 테이블 설정을 위한 주석은 아래 url 을 참조
가장 중요한건 DynamoDBIndexHashKey, DynamoDBIndexRangeKey 어노테이션일 것인데
각각 보조 인덱스를 만들기 위한 파티션키와 정렬키를 설정하는 어노테이션이다.
해당 어노테이션이 설정된 후 findBy... 과 같은 함수로 호출시 자동으로 인덱스를 찾아 객체를 매핑한다.
트랜잭션
DynamoDB 에서는 트랜잭션 기능을 제공하지만 안타깝게도 Srping Data DynamoDB 프로젝트에서 @Transaction 어노테이션은 작동하지 않는다.
Srping Data DynamoDB 라이브러리 또한 DynamoDBMapper 라는 내부 매퍼 클래스를 구현하여 작성한 라이브러리, DynamoDBMapper 의 자세한 내용은 아래 url 참고
https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/DynamoDBMapper.Methods.html https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/DynamoDBMapper.Transactions.html
위 url 에 작성된 데모코드와 같이 DynamoDBMapper 을 사용하면 트랜잭션 기능을 사용할 수 있기는 하다.
TransactionLoadRequest 를 작성하고 아래와 같이 매퍼에 전달하면 된다.
loadedObjects = mapper.transactionLoad(transactionLoadRequest);
DyanamoDB Java Client
https://docs.aws.amazon.com/ko_kr/sdk-for-java/latest/developer-guide/java_ec2_code_examples.html
비공식 Spring Data DyanamoDB 를 사용하기보다 AWS 에서 제공하는 DyanamoDB Java Client 라이브러리를 사용하는것도 좋은 방법이다.
또한 Dynamic Query 지원을 위해서는 AWS 에서 제공하는 DyanamoDB Java Client 의 DynamoDBMapper 의 scan, query 기능을 사용할 수 밖에 없다.
DynamoDB scan vs query: https://dynobase.dev/dynamodb-scan-vs-query/
scan,query모두 테이블에서 컬렉션을 읽어오기 위한 메서드이지만,query가파티션 키를 사용하기 때문에 성능이 더 뛰어나며 문서 역시query메서드 사용을 권장한다.
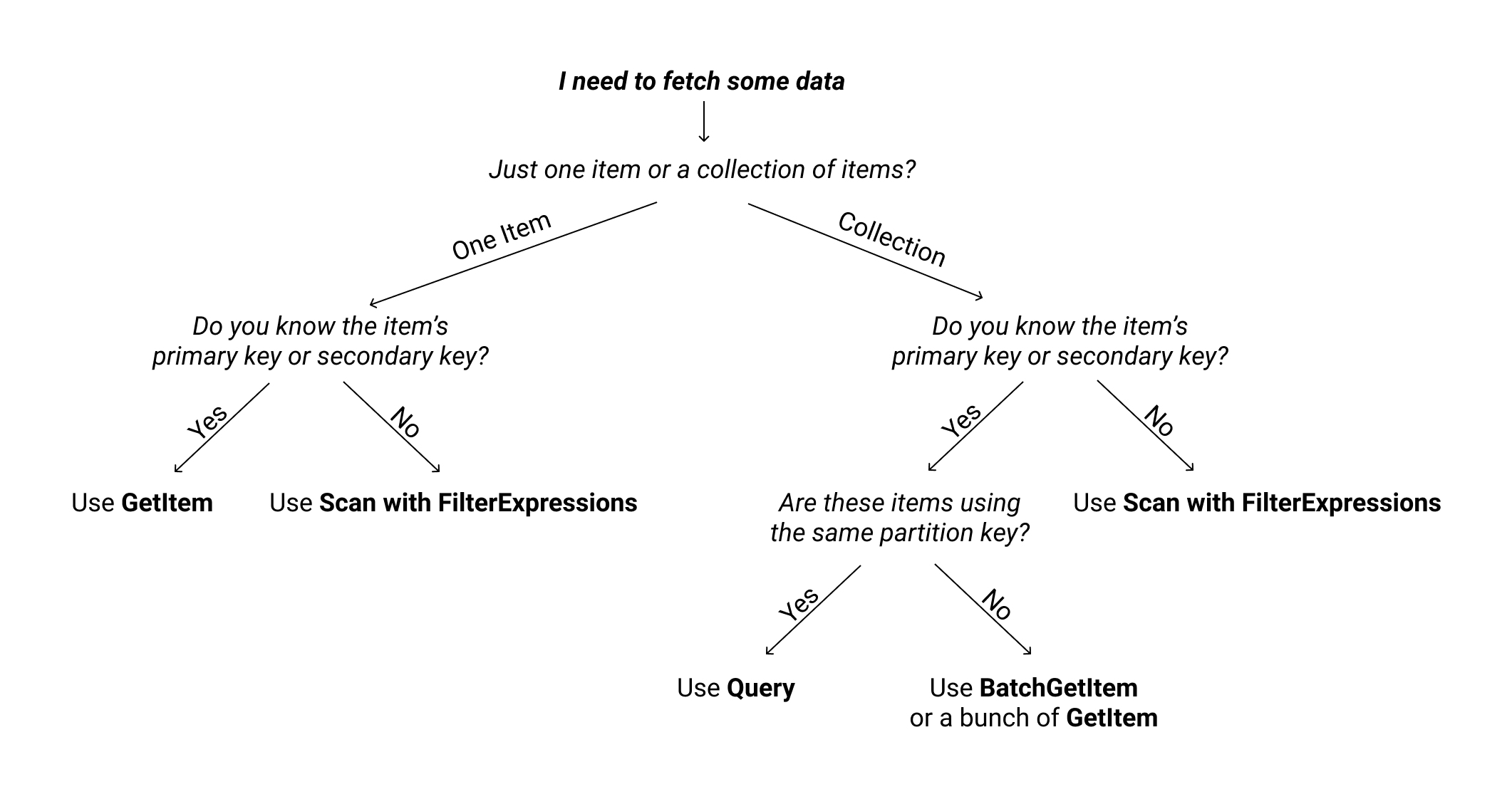
일단 아래처럼 Filter Condition 을 생성하는 코드를 작성할 수 있다.
private Map<String, Condition> generateFilter(GetCustomerRequestDto requestDto) {
Map<String, Condition> filter = new HashMap<>();
if (StringUtils.hasLength(requestDto.getName())) {
filter.put("name", new Condition()
.withComparisonOperator(ComparisonOperator.CONTAINS)
.withAttributeValueList(new AttributeValue(requestDto.getName())));
}
if (StringUtils.hasLength(requestDto.getType())) {
CustomerType type = CustomerType.forValue(requestDto.getType());
if (type != null) {
filter.put("type", new Condition()
.withComparisonOperator(ComparisonOperator.EQ)
.withAttributeValueList(new AttributeValue()));
}
}
if (requestDto.getBeginDate() != null && requestDto.getEndingDate() != null) {
if (requestDto.getEndingDate().isBefore(requestDto.getBeginDate())) {
throw new IllegalArgumentException("being date is after then ending date");
}
filter.put("create", new Condition()
.withComparisonOperator(ComparisonOperator.BETWEEN)
.withAttributeValueList(
new AttributeValue(CustomTimeUtil.getUTCString(requestDto.getBeginDate())),
new AttributeValue(CustomTimeUtil.getUTCString(requestDto.getEndingDate()))
// zone date time to UTC Time String
)
);
}
return filter;
}
타입에 따라 사용할 수 있는 ComparisonOperator 가 있으며 자세한 사항은 공식 문서 확인
https://docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_Condition.html
위의 경우 name, type, create 필드에 따라 dynamic 하게 쿼리를 생성할 수 있도록 설정하였다.
public List<Customer> findAllByUmidAndContractCdAndPortNo(String group, GetCustomerRequestDto requestDto) {
Customer forHash = new Customer();
forHash.setGroup(group);
Map<String, Condition> queryFilter = generateFilter(requestDto);
DynamoDBQueryExpression expression = new DynamoDBQueryExpression()
.withHashKeyValues(forHash)
.withConsistentRead(false)
.withQueryFilter(queryFilter);
return dynamoDBMapper.query(Customer.class, expression);
}
Customer 객체의 경우 group 문자열 필드를 GSI 로 설정하여 HashKeyValue 데이터로 사용하였다.
GSI 를 사용하다 보니 일관적인 읽기지원이 불가능함으로 withConsistentRead(false) 를 설정해주어야 한다.
scan 의 경우 아래처럼 진행해야 하는데 id 리스트를 기반으로 검색을 진행하려면 어쩔수 없이 scan 요청을 해야한다.
public List<Customer> findAllByIdIn(List<String> customerIds, GetCustomerRequestDto requestDto) {
Map<String, Condition> scanFilter = generateFilter(requestDto);
List<AttributeValue> attList = customerIds.stream().map(id -> new AttributeValue(id)).collect(Collectors.toList());
scanFilter.put("id", new Condition()
.withComparisonOperator(ComparisonOperator.IN)
.withAttributeValueList(attList));
DynamoDBScanExpression expression = new DynamoDBScanExpression()
.withScanFilter(scanFilter);
return dynamoDBMapper.scan(Customer.class, expression);
}
RCU 를 낮추기 위해 HashKey 를 사용하는데, 아쉽게도 동시에 여러개의 HashKey 를 사용하여 쿼리하는 것은 불가능하다.
queryFilter 를 사용해 전체읽기를 사용하거나, 두번 읽은다음 어플리케이션 레이어에서 조인해야한다.
여담
테이블 생성시 LSI 을 생성하려면 RangeKey 를 설정해야 한다.
그런데 이 RangeKey 를 Spring Data DynamoDB 와 같이 사용하기가 쉽지 않다.
Spring Data DynamoDB 에서 제공하는 Repository 객체들이 RangeKey 와 HashKey 중 어떤 값을 키값(Id)로 설정해야 하는지 혼동되어 아래와 같은 에러가 발생한다.
no field or method annotated with interface org.springframework.data.annotation.id found
그렇다고 @Id 어노테이션을 추가하면 아래 에러가 발생하게 되는데
No method or field annotated by @DynamoDBHashKey within type java.lang.String!
모두 Repository 인터페이스에서 제공하는 에러들이다.
RangeKey 를 써야한다면 Repository 객체를 사용하지 않고 DynamoDBMapper 를 이용해 쿼리를 작성하면 된다.
혹은 Spring Data DynamoDB 에서 제공하는 Custom Key Class 를 별도로 작성하면 된다.
https://github.com/derjust/spring-data-dynamodb/wiki/Use-Hash-Range-keys
DynamoDBMapper만을 사용하는것을 추천
만약 두개의 칼럼을 기반으로 필터링해야할 경우 칼럼1#칼럼2 형태로 2개의 칼럼을 하나의 칼럼에 우겨넣어 LSI 로 설정해야 한다.
DynamoDB 는 단순한 CRUD 에선 최적이라할 수 있지만 복잡한 쿼리식은 아예 설계불가능할 수 있기에 충분한 요구분석후에 사용을 결정해야 한다.
데모코드
https://github.com/Kouzie/spring-boot-demo/tree/main/dynamodb-demo