DB 복제!
복제
https://www.yes24.com/Product/Goods/59566585
https://www.brianstorti.com/replication
고부하가 발생하여 확장이 필요하다면 CPU, Memory 를 늘리는 수직확장이 가장 간단하지만 갈수록 비용이 비싸진다.
하지만 모든 문제가 수직확장으로 해결되진 않음으로 무한한 비용을 지불할 수 없기에 수평확장을 해야한다.
CPU core 가 메모리, 디스크를 공유하기에 수직활장을
공유 메모리 아키텍처(shared-memory architecture)라 부르기도 함.
수평확장을비공유 아키텍처(shared-nothing)라 부르기도 함.
수평확장은 특별한 하드웨어를 필요로 하지 않아 가격대비 성능이 가장 좋은 시스템을 사용할 수 있다. DB 에서 수평확장으로 분산하는 방법은 아래 두가지.
- 복제: 데이터의 복사본을 여러 노드에 유지, 일부 노드가 불가능 상태일 때 복구기능을 가지고 있음.
- 파티셔닝(샤딩): 데이터를 쪼개 각기 다른 노드에 할당.
수평확장시 데이터의 복제, 다중 노드에서 트랜잭션에 대해 고민해야할 부분이 생긴다.
DB ACID 원칙을 지키기 위해 write 요청이 모든 replica(복제서버)에 전달되어야 한다.
가장 일반적인 해결책은 leader-based replication 이다.
leader와read replica는 여러가지 이름으로 불림.
leader:active, master
read replica:passive, slave, secondary, read replica, hot standb
leader 와 동기화 되는 read replica 를 운영하는 방법은 아래 3가지,
leader 개수 순서대로 [single-leader, multi-leader, leaderless] 아키텍처 구성이 가능하다.
각 아키텍처별로 쓰기 충돌 이 발생했을 때 복구를 위한 충돌 회피 시나리오가 있다.
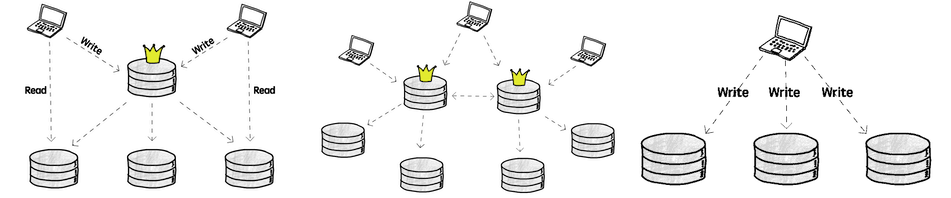
복제 환경은 모든 네트워크, 시스템이 분리되어 있어 부분장애가 언제든 일어날 수 있고 성공과 실패 여부도 정확히 알 수 없어 비결정적이다.
해당 환경에서 빠르게 결함있는 노드를 감지하고 일시적 네트워크 지연 장애인지, 장기적 결함인지 판단하고 기존 시스템이 정상 운영될 수 있도록 자동 복구되어야 한다.
single-leader
대부분 RDB 에선 single-leader 아키텍처를 사용.
leader 에서 write 요청을 처리할 때 마다 replication log(change stream) 을 read replica 에게 전달한다.
이때 해당 replication 를 논리적 로그(logical log) 라 부른다.
하나의
log가 하나의row를 논리적 변경하기 때문.
다수의row를 수정하는 트랜잭션은 다수의log를 생성 후 커밋됐음을 레코드 에 표시한다.
log기반 복제는 log 를 파싱해 ETL 구축도 쉽게 연동할 수 있다.
정확한 로그 비교는 MySQL 의 경우binlog coordinate(이진로그) 기법을 사용한다.
아래 그림이 logical log 가 read replica 에전달되는 과정.
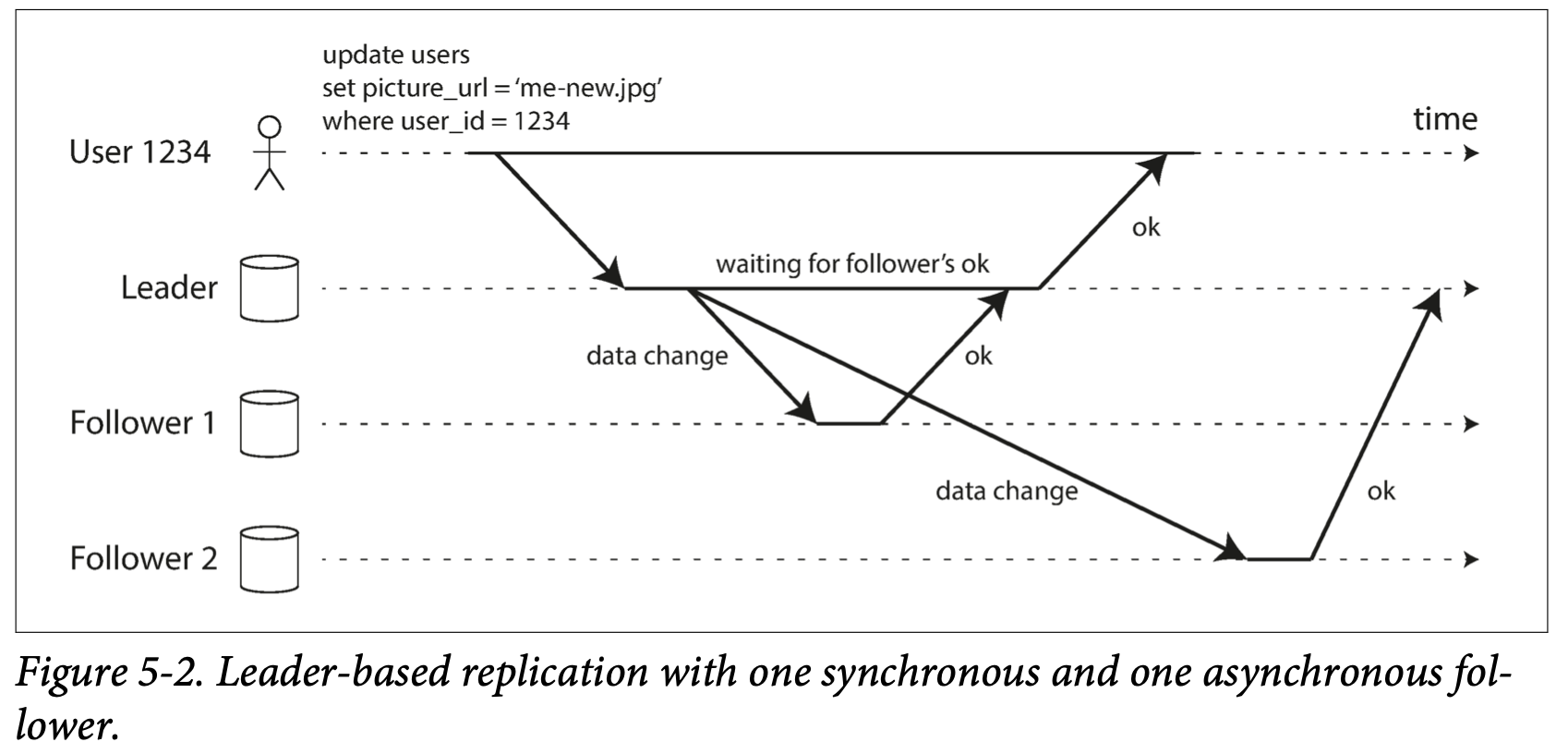
follower1은동기식 복제follower2는비동기식 복제
동기식 복제 는 시스템,네트워크 문제가 있을 수 있기 때문에 반환시간이 얼마나 걸릴지는 보장할 수 없다.
비동기식 복제 는 복제 적용 여부를 확인하지 않기 때문에 여러 충돌 시나리오에 휘말린다.
두 방법 모두 장단점이 있지만 복제 지연 문제로 인해 비동기식 복제를 주로 사용한다.
비동기식 복제 를 사용하면 read replica 에 문제가 발생해도 시스템은 정상동작한다.
비즈니스 로직에서 철저한 동기과정이 필요할 경우 동기식 복제를 사용.
혼합해서 사용하는반동기식(semi-synchronous)방법도 많이 사용한다.
failover
read replica 의 failover 는 아래와 같은 과정을 거쳐 leader 와 동기화 된다.
leader 의 스냅숏 과 그 이후의 모든 데이터 미처리분인 backlog 를 가져와 read replica 와 비교 한뒤 적용, backlog 을 처리한 순간 부터 해당 시간까지 leader 와 동기화 되었다 할 수 있다.
leader 의 failover 는 고려해야할 상황이 더 많다.
reader replica중leader하나를 승격하는leader 선출과정에서replica들의 실행이 변경되어야 한다.leader에서비동기식 복제사용시 동기화 되지 못한write 요청이 유실될수 있다.- 두개 이상의 노드가 자신을
leader로 생각하는스플릿 브레인(split brain)문제가 발생할 수 있다.
RDB 의 경우 leader 의 failover 는 사람이 수동으로 복구를 하는 편이다.
하지만 Hadoop 과 같은 대규모 분산 클러스터에선 수동복구는 쉽지 않아 자동 leader 선출 을 위한 합의 알고리즘 을 사용한다.
합의 알고리즘은 아래전체순서 브로드케스트에서 설명
복제 지연
비동기식 복제 방식을 사용하면 read replica 를 많이 만들어도 영향이 적고 높은 read-scaling 을 얻을 수 있다,
하지만 모든 read replica 들이 동일한 데이터를 가지고 있는지는 보장하지 못한다.
비동기식 복제 에서 복제 지연이 길어지면 아래와 같이 자기가 작성한 내용도 보지 못하는 쓰기 후 읽기 일관성(read after write consistnecy) 문제가 발생한다.
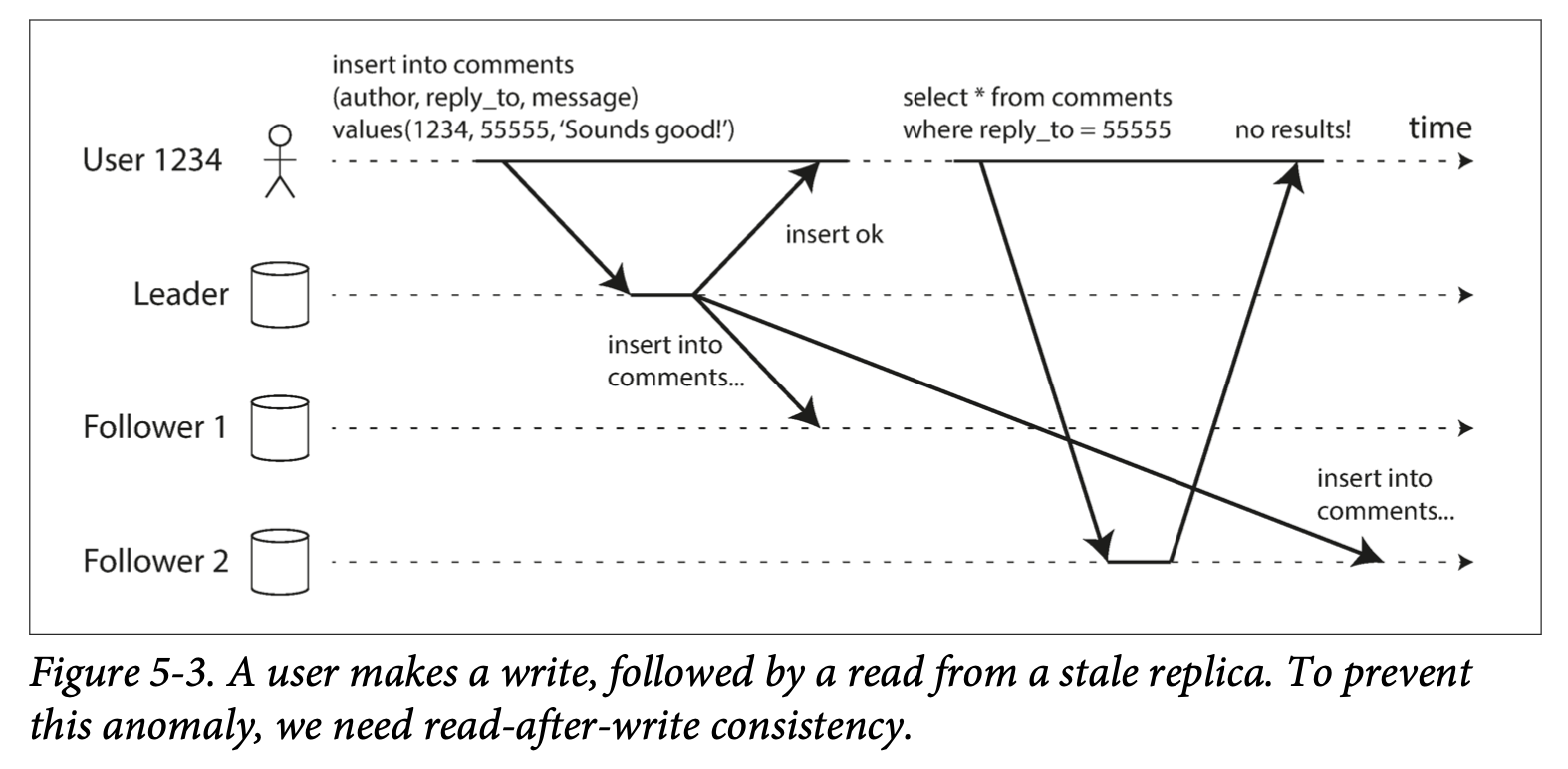
read replica 가 많아질수록 데이터의 불일치성은 심해진다.
잘 사용하지 않지만 복제 지연 해결을 위해 어플리케이션 레이어에서 할 수 있는 몇가지 조치방법이 있다.
- 동기화가 중요한 로직에선
leader에서만read/write 요청진행. - 읽어온 데이터의 마지막 갱신시간이 1분 미만이라면 이후
read 요청도leader에서 진행, 1분 이후 부턴read replica에서도read 요창진행.
어플리케이션에서 DB 접근을 변경하는건 까다롭기 때문에 거의 사용하지 않는다.
multi-leader
multi-leader 복제는 leader 간 복제에서 쓰기 충돌 이 발생할 수 있다.
아래 그림은 multi-leader 에서 거의 동시 write 요청 을 비동기식 복제 로 처리시 발생하는 쓰기 충돌 시나리오 이다.
동기식 복제사용시쓰기 충돌을 해소할수 있지만sigle-leader를 사용하는 것이 성능상 더 낫다.
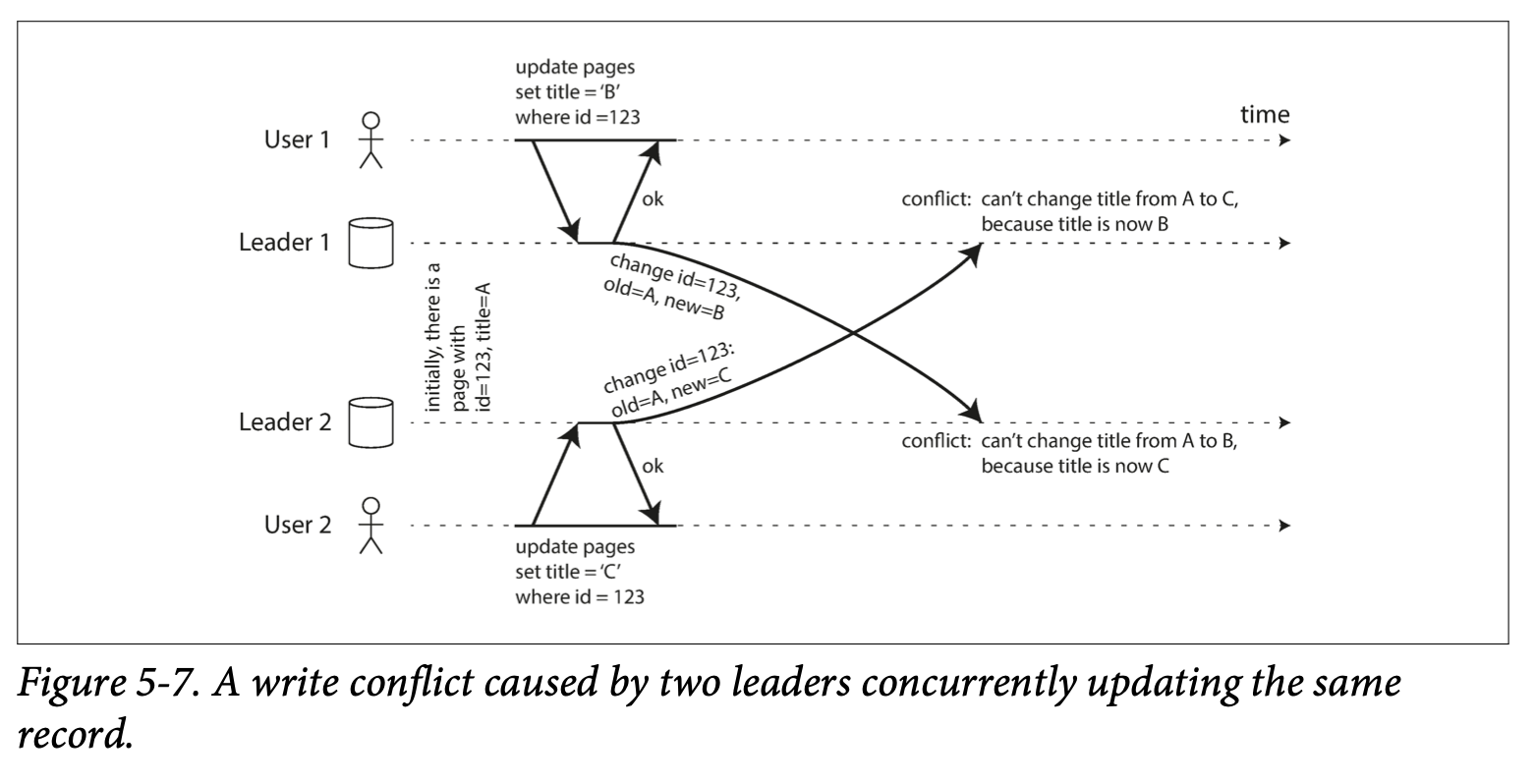
만약 한개 row 에 대해서만 충돌 회피 를 구현하려면 아래와 같은 사전 규약을 몇개 만들면 가능하다.
- 특정 레코드
write 요청은 특정leader에서만 처리. last write wins(LWW)방법 사용고유 ID(timestamp, uuid, hash)를 부여하고 우선순위를 적용.leader에 우선순위를 적용.
versioning을 사용,write 요청에 대한 결과를 반환.
leaderless
leaderless 복제는 는 aws Dynamo 시스템에서 사용한 후 다시 유행했다.
카산드라, 볼드모트등이leaderless복제 기반 DB 가 있음.
복제서버에 병렬로 write/read 요청을 전송한다.
n개 복제서버에서w개 노드에서write 요청성공하면 성공으로 간주.n개 복제서버에서r개 노드에서read 요청성공하면 성공으로 간주.- 노드 수에 따른 설정
w = r = (n + 1) / 2
아래 그림은 n=3, w=2, r=2 인 경우
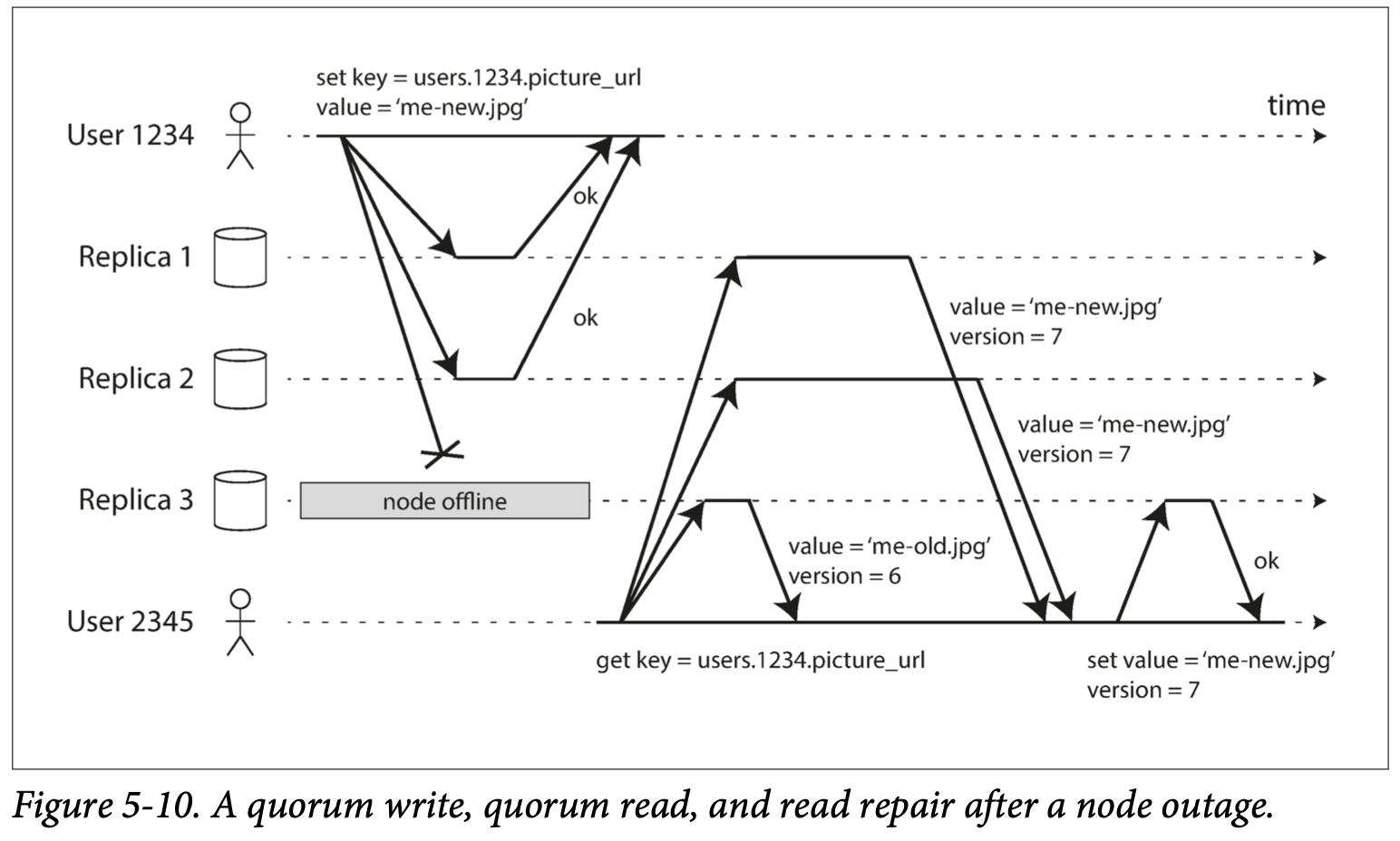
실패한 write 요청 를 처리하기 위해 2가지 방법을 사용.
- 읽기 복구: 위 그림처럼 read 요청 반환값을 사용.
- 안티 엔트로피: 백그라운드 프로세스가 복제서버간 차이를 지속적으로 찾음.
선형성(Linearizable)
살아 있지만 틀린 게 나은가, 올바르지만 죽은 게 나은가? 제이 크렙스, 카프카와 젭슨에 대한 몇 가지 기록1 (2013)
복제 환경에서 가장 단순한 일관성 보장 방법은 최종적 일관성 이다, 쓰기를 멈추고 기다리면 언젠간 모든 replica 에서 동일한 값을 읽을 수 있게 된다는 뜻이다.
하지만 언제 완료될지는 알 수 없기에 약한 일관성 보장이다.
좀더 강력한 방법으로 일관성을 보장하는 선형성(Linearizable) 에 대해 알아본다.
선형성은 각종 일관성 아이디어인 [원자적 일관성, 강한 일관성, 즉각 일관성, 외부 일관성] 을 포함하는 개념으로 최신성 보장(recency guarantee) 라 불리기도 한다.
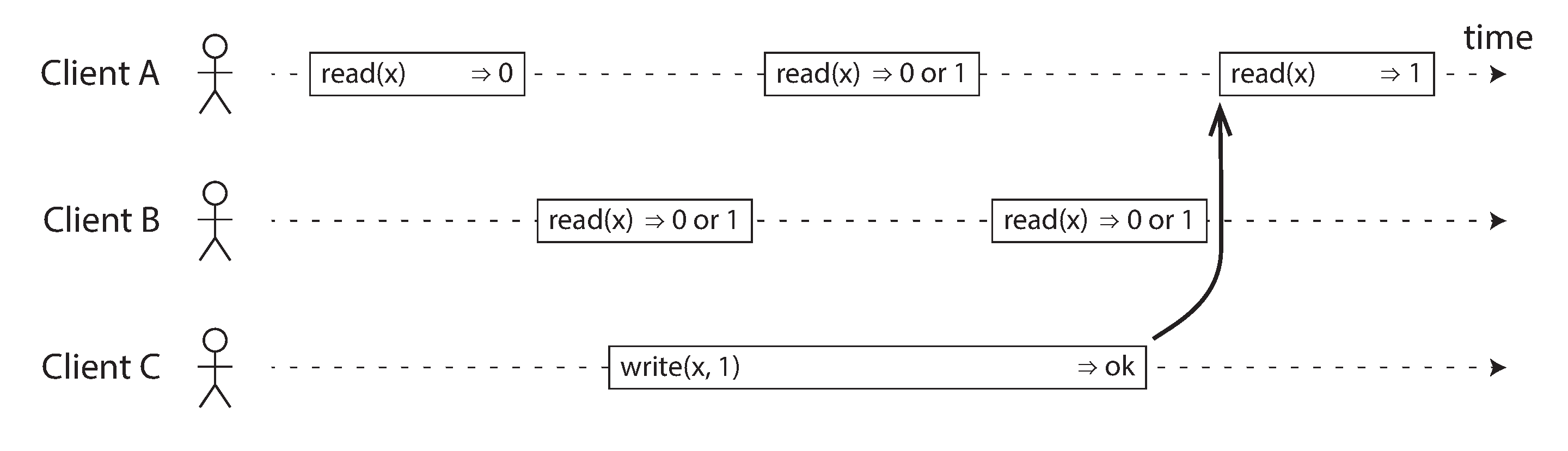
다음 그림처럼 클라이언트A,B 는 read(x) 값을 읽을때 0과 1이 번갈아 출력될 수 있으며 이는 선형성이라 부를 수 없다.
특정시점에서 반환값이 최신값으로 결정되었다면, 해당 시점 이후로는 모든 클라이언트에서 최신화된 값을 받아야 한다.
선형성이 구현되었다면 아래 그림과 같이 ClientA 가 read(x)=>1 를 수신한 순간부터 ClientB 에서도 동일한 결과값을 받도록 결정되어야 한다.
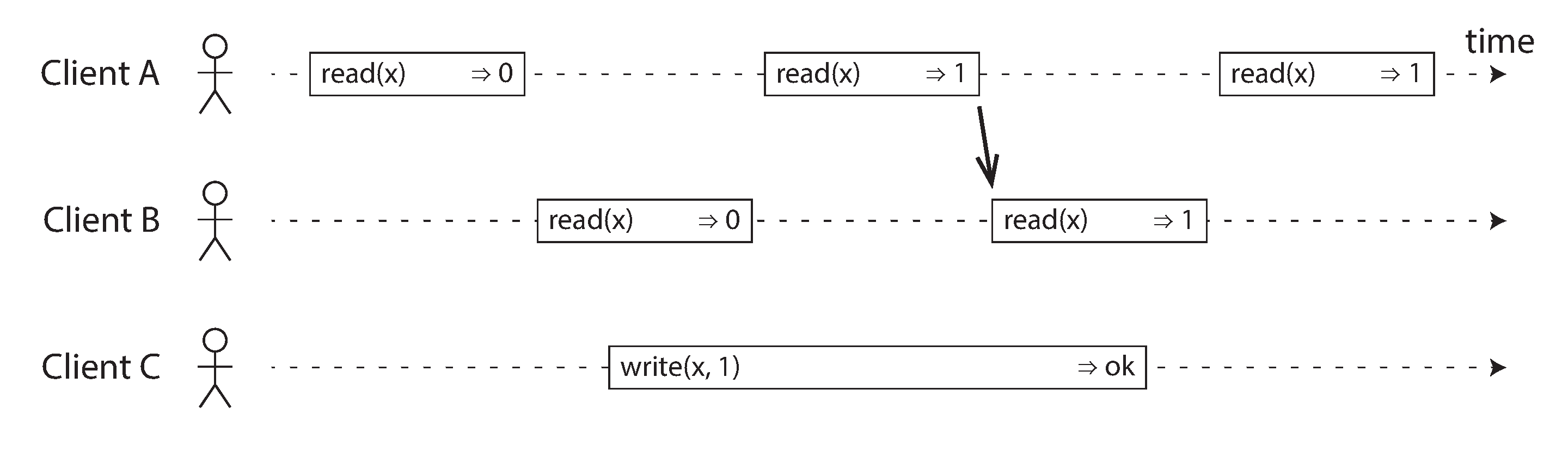
선형성은 데이터의 일관성 있는 read & write 에서도 사용되지만 서비스에서 구현해야할 [잠금장치, 제약조건(unique)] 을 구성하는데에도 중요하게 사용된다.
CAP 정리
CAP 정리 는 분단 내성(Partition tolerance) 이 발생했을 때 일관성(Consistency) 과 가용성(Availability) 을 모두 만족하는 시스템은 구현할 수 없다는 이론이다.
복제환경에서 선형성을 구현하기는 쉽지 않다. 지금까지 선형성의 특징을 보면 single-leader 에서 빡빡한 동기식 복제 를 사용해야 겨우 선형성을 구현할 수 있다.
항상 가용성과 선형성을 저울질하며 어떤것을 우선시할지 결정해야한다.
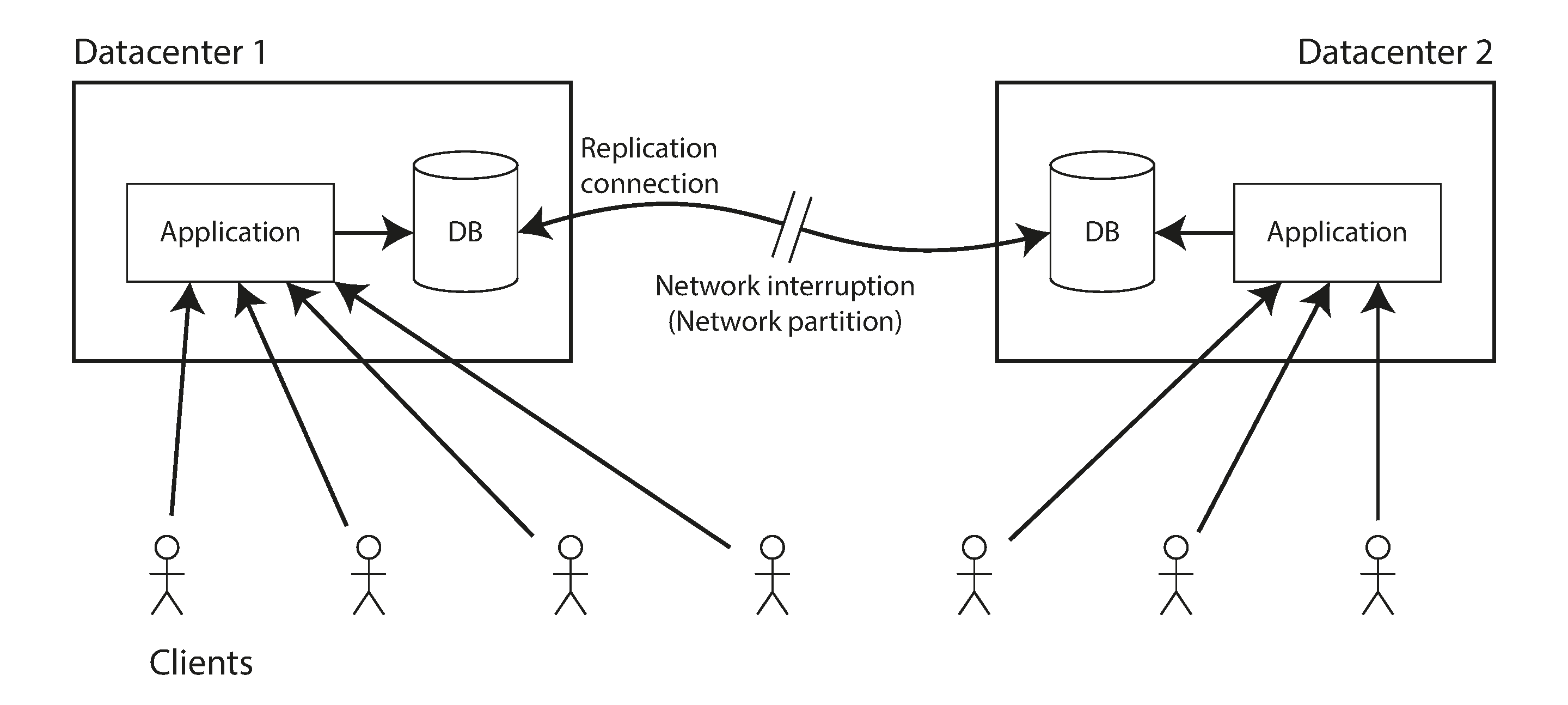
위와 같이 Datacenter1(leader), Datacenter2(replica) 로 구성될 때, 둘 사이 연결이 끊기면 Datacenter2 가 leader 로 승격하면서, 데이터 동기화가 깨짐과 동시에 선형성도 깨진다.
위와 같은 상황에서 선형성을 구현하려면 연결이 끊긴 replica 는 복구될 때까지 시스템 중단되어야 한다.
인과적 의존성(causally consistent)
대부분의 경우에서 선형성을 위해 가용성을 전부 포기하지 않는다. 완화된 일관성 을 지향하고 선형성이 필요한 상황을 회피하는 방법을 사용하는것이 일반적이다.
두 이벤트에 인과적인 관계가 있으면 이들은 순서가 있다는 뜻이고, 어떤 연산이 먼저 실행됐는지 인과성을 유지할 수 있게된다.
인과적 의존성 을 사용하면 완화된 일관성을 사용하면서도 선형성이 필요한 비즈니스에 대안으로 사용할 수 있다.
이전 발생(happend-before)
multi-leader, leaderless 에서 발생하는 쓰기 충돌 의 충돌 회피 방법중 하나.
가장 간단한 충돌 회피 방법은 LWW 이지만 아래 그림처럼 일부 write 요청 이 유실될 가능성이 있다.
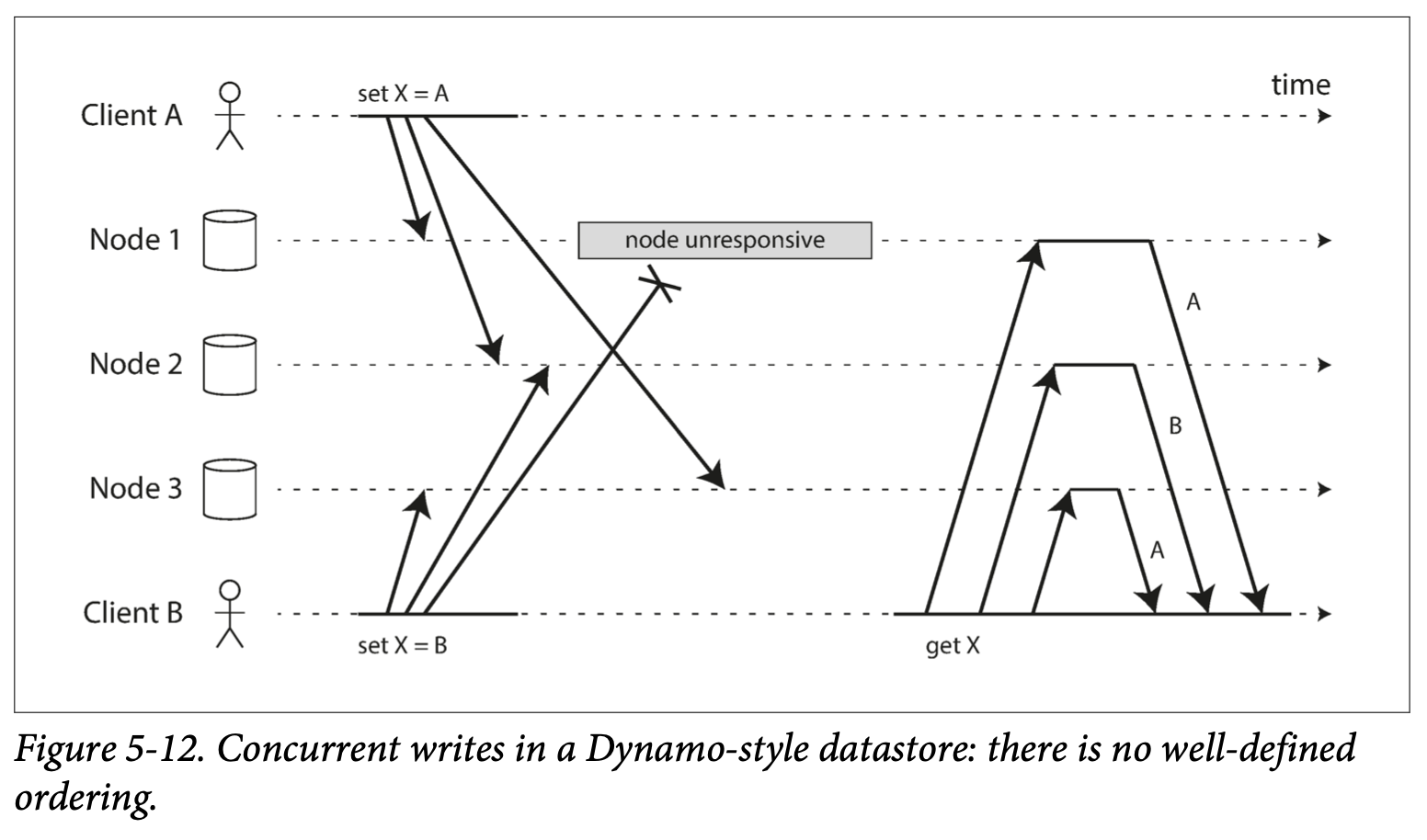
set X=B 연산은 병합되는 과정에서 없었던 일이 되어버린다.
이전 발생 은 모든 요청에 versioning 과 수정사항을 별도로 관리한다.
아래는 2개의 클라이언트가 [milk, eggs, flour, milk, ham, eggs, bacon] 을 같은 장바구니에 동시에 삽입하는 예제이다.
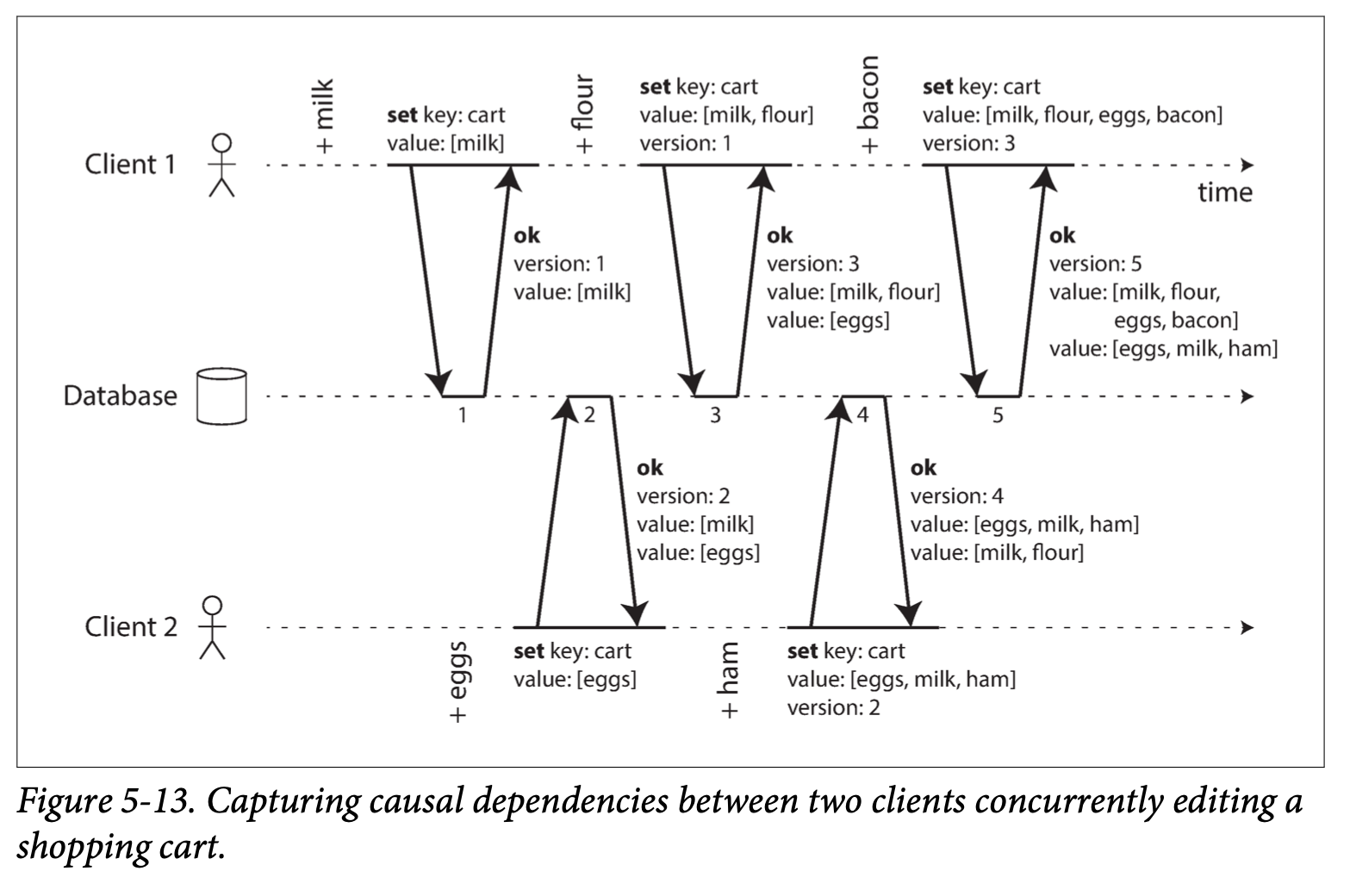
이전 발생 기법은 버전에 값을 덮어 씌우는 방식이기 때문에 write 요청 유실없이 충돌 회피 가능하다.
[milk, eggs] 의 경우 모든 version 에 들어가게 되면서 중복되는데, leaderless DB 에서 자체적으로 병합을 처리해준다.
그림은 단일 replica 에 대해서 설명하지만 다중 replica 라 하더라도 모든 write 요청에 대한 유일한 versioning 인 버전 벡터(version vector) 를 사용한다면 원리는 동일하다.
multi-leader, leaderless 환경에서 버전 벡터를 생성하는 방법은 여러가지가 있다.
- 노드별 일련번호 구간 관리
Node1(홀수), Node2(짝수)
Node1(0~1000), Node2(1001~2000) - 램포트 타임스탬프
노드별 카운터 별도 관리, 질의시 노드번호와 카운터를 모두 알고 있어야 접근 가능하다.
모든 연산과정에 버전 벡터 을 사용한다면 모든 연산에 대해 인과적 의존성 을 알 수 있고 최종적 일관성 을 지킬 수 있다.
2PC(Two-Phase Commit: 2단계 커밋)
복제환경에서 하나의 논리적 트랜잭션을 원자적으로 처리하기 위한 방법 중 하나.
이전 발생 같은 방식으로 인과적 의존성 구현 시 write 요청 의 정확한 결과는 병합과정 이후에나 알 수 있다.
계정 중복체크와 같은 제약조건과 동시성이 중요한 로직에선 write 요청 의 결과를 확인해야 한다.
2PC 에서 트랜잭션을 조율하는 조정자(Coordinator), 참여자(participant) 가 존재하며, 모든 DB 에게 준비→확인→커밋→확인 형식으로 일관성을 유지한다.
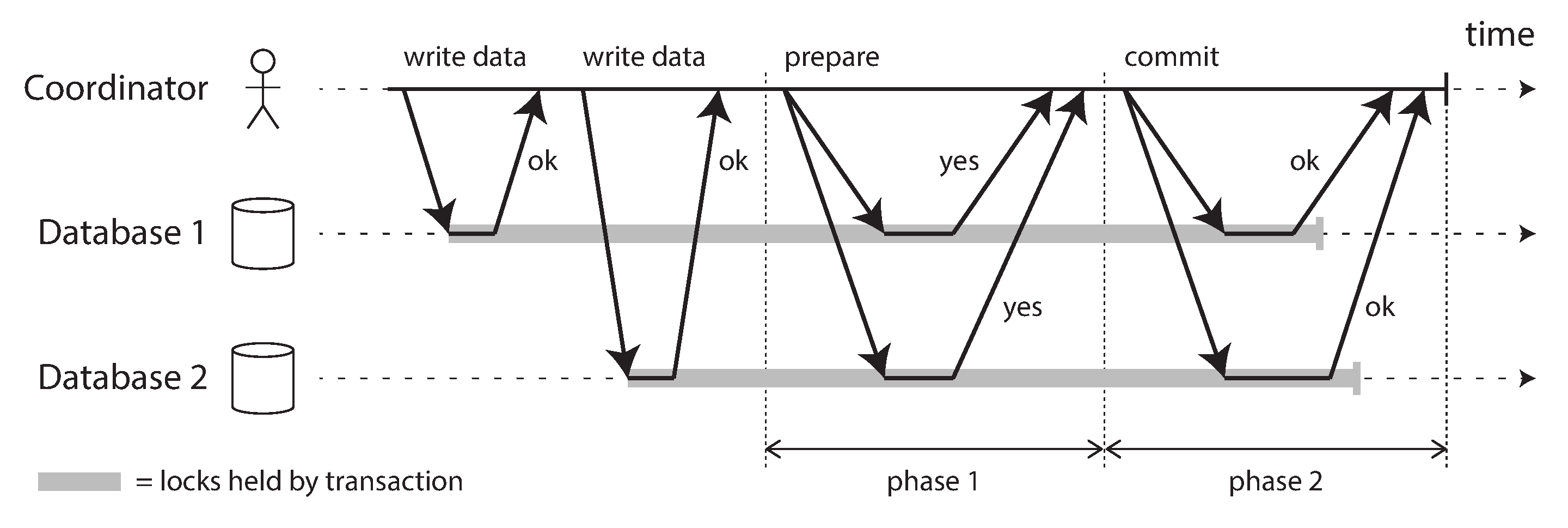
phase1(준비) 은 phase2(커밋) 을 치루기 전 마지막 보루 같은 개념이다.
phase1 과정에서 모든 노드에게 yes 사인이 떨어지면 해당 트랜잭션은 반드시 커밋된다.
phase2 과정 도중 특정 노드가 죽더라도 나중에 복구될것이라 믿고 정상 노드들은 commit 요청 을 강행한다.
반대로 phase1 과정에서 no 사인이 떨어지면 모든 참가자에게 phase2 과정에서 abort 요청 을 전송하게 된다.
2PC 는 원자성을 보장하지만 데드락 상황에 빠지기 매우 쉬운 구조이다. 만약 phase2 가 실패할 경우 모든 노드가 복구될때 까지 조정자는 영원히 phase2 를 재시도하게된다. 또한 조정자 장애 발생시 참여자들은 무한 대기상태로 멈춘다.
참여자 노드가 늘어날수록 단일 DB 에 비해 성능차이가 심하게 일어나며, 조정자가 단일장애지점(SPoF)으로 동작하기에 굉장히 제한적인 상황에서 사용한다.
조정자는
트랜잭션 관리자라고도 함
조정자는 일반적으로write 요청하는 어플리케이션 프로세스에서 라이브러리 형태로 구현된다.
XA 트랜잭션
XA 트랜잭션(eXtended Architecture) 는 메세지 브로커와 DB같이 이종 서비스간의 동작을 하나의 트랜잭션으로 묶어 2PC 처럼 동작하도록 지원하는 표준 기술이다.
2개의 별개의 시스템을 2PC 처럼 묶어서 결과적으로 정확히 한번(effectively exactly once) 동작하도록 할 수 있다.
Java Transaction API(JDBC 구현체), Java Message Service(브로커용 드라이버) 를 사용하여 XA 트랜잭션을 구현할 수 있다.
- 메세지 브로커
- ActiveMQ
- IBM MQ
- DB
- Oracle
- MySQL
- PostgreSQL
// ActiveMQ 연결 설정
ConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory("tcp://localhost:61616");
// MySQL XA 데이터 소스 생성
MysqlXADataSource mysqlXADataSource = new MysqlXADataSource();
mysqlXADataSource.setUrl("jdbc:mysql://localhost:3306/test");
mysqlXADataSource.setUser("username");
mysqlXADataSource.setPassword("password");
// ActiveMQ와 MySQL에 대한 XA 연결 생성
XAConnection activeMQConnection = ((ActiveMQConnectionFactory) activeMQConnectionFactory).createXAConnection();
XAConnection mysqlXAConnection = mysqlXADataSource.getXAConnection();
...
public void startXaTransaction() {
// ActiveMQ와 MySQL에서 XAResource 가져오기
XAResource activeMQXAResource = activeMQConnection.createXASession().getXAResource();
XAResource mysqlXAResource = mysqlXAConnection.getXAResource();
// XID 생성
byte[] gid = new byte[]{0x01};
byte[] bid = new byte[]{0x02};
Xid xid = new XidImpl(0x1234, gid, bid);
// 트랜잭션 시작
activeMQXAResource.start(xid, XAResource.TMNOFLAGS);
mysqlXAResource.start(xid, XAResource.TMNOFLAGS);
// ActiveMQ에 메시지 전송
Session activeMQSession = activeMQConnection.createSession(true, Session.SESSION_TRANSACTED);
Queue queue = activeMQSession.createQueue("exampleQueue");
MessageProducer producer = activeMQSession.createProducer(queue);
TextMessage message = activeMQSession.createTextMessage("Hello, ActiveMQ!");
producer.send(message);
// MySQL에 데이터 삽입
Connection mysqlConnection = mysqlXAConnection.getConnection();
PreparedStatement preparedStatement = mysqlConnection.prepareStatement("INSERT INTO test_table VALUES (?)");
preparedStatement.setString(1, "Hello, MySQL!");
preparedStatement.executeUpdate();
// 트랜잭션 커밋
activeMQXAResource.prepare(xid);
mysqlXAResource.prepare(xid);
activeMQXAResource.commit(xid, false);
mysqlXAResource.commit(xid, false);
// 리소스 정리
preparedStatement.close();
mysqlConnection.close();
producer.close();
activeMQSession.close();
mysqlXAConnection.close();
activeMQConnection.close();
}
XA 트랜잭션이 유지되는 동안 잠금을 유지하기에 이종 시스템간의 일관성을 유지시킨다.
전체순서 브로드케스트(total order broadcast)
원자적 브로드캐스트(atomic boradcast) 라 부르기도 함.
전체순서 브로드케스트(이하 TOB) 일반적인 브로드캐스트 개념에서 아래와 같은 추가사항을 요구한다.
- 신뢰성 있는 전달: 모든 노드에 메세지가 전달되어야 함.
- 전체 순서가 정해진 전달: 모든 메세지는 모든 노드에 같은 순서로 전달된다.
TOB 를 구현하기 위해서 아래와 같은 내용을 고민해야 한다.
- 네트워크 지연이 발생해도 모든 노드에 메세지가 전달되기 위한 재시도 방법.
- 전달받은 메세지의 수신과 정확한 순서를 확인하는 방법.
- 모든 노드에서 전달된 메세지의 처리에 대한 원자적 커밋 방법.
TOB 는 다양한 합의 알고리즘(Consensus Algorithm) 을 사용해 선형성 원자적 연산 구현하고 노드간 원자적 연산(compare and set) 을 지원한다.
TOB 는데이터 복제, 상태 동기화 를 필요로하는 서비스들이 사용한다.
대표적인 서비스는 아래와 같다.
- Zookeeper
- etcd
분산환경에서 동작하는 Hadoop, Kafka 같은 서비스가 Zookeeper 에 의존하는 이유가 합의 알고리즘 때문이다.