MySQL 인덱스!
인덱스
400페이지가 넘는 책을 한장씩 펼처 원하는 내용를 찾기보단 목차를 통해 찾느게 빠르듯,
DB에서도 레코드가 저장된 주소를 key-value 쌍으로 삼아 정렬된 인덱스를 생성한다.
인덱스 장단점
위의 설명대로 인덱스의 장점은 검색시 시스템 부하를 획기적으로 줄일 수 있다.
트리 구조의 저장을 통해 O(log n)의 시간을 요구한다.
단점은 인덱스를 위한 저장공간, 별도의 연산과정이 필요하다.
특히 추가/삭제 과정에서 균형이 무너질 수 있고 균형 재분배를 통해 다시 균형을 맞추는대 매우 큰 비용이 발생한다.
따라서 추가/삭제가 빈번히 일어나는 경우 오히려 성능저하 가능성이 있다.
WHERE 조건문에 자주 사용되는 칼럼, JOIN 이 많이 사용되고 NON NULL 컬럼을 인덱스로 설정하면 좋다.
물론 테이블 행 수가 적거나, INSERT/DELETE 가 자주 일어나고,
WHERE 조건으로 검색결과가 전체 데이터의 10~15% 이상이라면 인덱스를 설정하지 않는게 더 효율적일 수 있다.
인덱스의 종류
- 고유 인덱스(Unique Index)
- 비고유 인덱스(NonUnique Index)
- 단일 인덱스(Single Index)
- 결합 인덱스(Composite Index)
- 함수기반 인덱스(Function Index)
고유 인덱스 생성
기본키, 유일키에 대한 칼럼에 대한 인덱스, 제약조건에 가까운 인덱스이다.
CREATE UNIQUE INDEX index_board
ON tbl_board (b_idx)
비고유 인덱스 생성
중복값이 있는 칼럼에 대한 인덱스
CREATE INDEX index_board
ON tbl_board (b_idx)
복합 인덱스 생성
복수개의 칼럼으로 구성된 인덱스
CREATE UNIQUE INDEX index_board
ON tbl_board (b_idx, b_title)
내부적으론 2개의 칼럼을 합쳐 B Tree 를 구성하게 됨으로 결합 인덱스의 칼럼 순서가 중요하다.
복합 인덱스는 결합 인덱스, 다중칼럼 인덱스 등 불리우는 이름이 많다.
또 복합 인덱스 내부 칼럼만 읽는 질의 요청시 인덱스만 사용해 질의 응답하는 커버링 인덱스 방법을 사용할 수 있다.
함수기반 인덱스
특정 연산이후의 만들어진 값을 인덱스로 만들고 싶을 때 함수기반 인덱스를 사용한다.
CREATE TABLE tbl_user
(
user_id BIGINT,
first_name VARCHAR(10),
last_name VARCHAR(10),
PRIMARY KEY (user_id)
);
CREATE INDEX index_full_name ON tbl_user ((CONCAT(first_name,' ',last_name)));
테이블 구조를 변경하지 않고 빠른 검색을 위한 인덱스 생성이 가능하다.
B Tree(Balanced Tree)
참고
https://www.youtube.com/watch?v=bqkcoSm_rCs
https://www.youtube.com/watch?v=H_u28u0usjA
https://cuuduongthancong.com/~galles/visualization/BTree.html
대부분의 DB 인덱스 내부구조는 B Tree 를 기반으로 한다.
최상위 루트노드로부터 자식노드가 붙어있는 트리형태로, 차수 만큼의 자식노드를 가질 수 있고 차수 - 1 개의 데이터를 가질 수 있다.
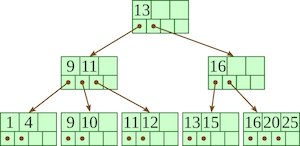
B Tree 는 이론상 탐색에서 가장 빠른 $O(\log{n})$ 의 속도를 보여준다.
위 그림의 경우 차수가 4인
B Tree
B+ Tree, B* Tree 가 인덱스에 주로 사용된다.
인덱스 크기에 따른 B Tree 변화
https://blog.jcole.us/2013/01/10/btree-index-structures-in-innodb/
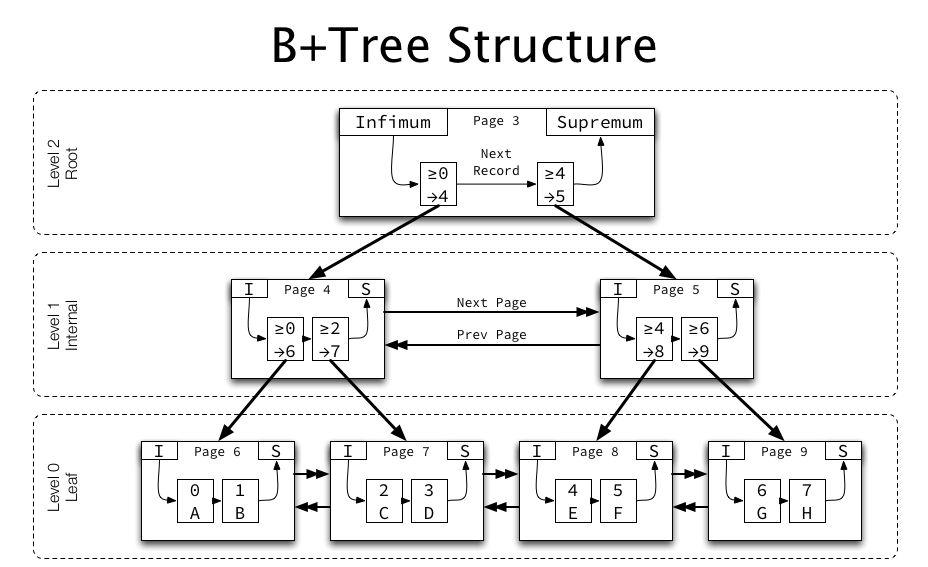
MySQL InnoDB 의 인덱스 페이지는 위 그림과 같이 B+ Tree 로 구성되어 있으며,
실제 데이터 레코드는 리프 노드 인덱스 페이지에서 가리키게 된다.
그림만 봐도 인덱스 페이지 에 넣을 수 있는 키값의 크기가 작을수록 많은 데이터 레코드를 가리킬 수 있다.
키값 16byte, 자식노드 주소 크기가 12byte 일 때 대략 585 개 정도의 노드 포인터를 저장할 수 있다. 레벨이 3만되어도 리프노드 에서 2억(585^3) 의 데이터 레코드를 가리킬 수 있다.
대부분의 대용량 데이터베이스라 하더라도 레벨이 5를 넘지 않는다.
보통 스토리지 엔진이 인덱스 페이지 단위로 디스크에서 데이터를 읽기 때문에 키값 크기가 늘어날 수록 비효율적으로 동작하게된다.
만약 키값이 16byte 에서 32byte 로 늘어나면 리프노드에서 가리키는 데이터 레코드는 5천만개로, 급속도로 줄어들게 된다.
인덱스 페이지 사이즈는 기본 16KB,
@@innodb_page_size글로벌 환경변수로 확인 및 변경 가능.
인덱스 탐색(Index seek), 인덱스 스캔(Index scan)
인덱스를 통해 데이터 레코드를 읽어올 때 아래 2가지 과정을 먼저 거처야한다.
- 인덱스 탐색(Index seel): 조건을 만족하는 인덱스 저장위치 탐색
- 인덱스 스캔(Index scan): 저장위치부터 Range 만큼 스캔
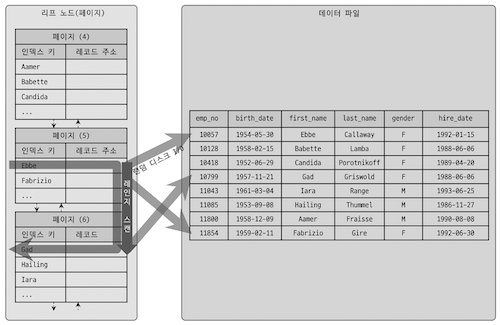
B Tree 인덱스 페이지에서 인덱스르 검색해도 해당 인덱스에는 primary key 만 저장되어 있기에, primary key 를 통해 데이터 레코드를 다시한번 읽기 때문에 레코드 단위로 랜덤 I/O 가 한번씩 발생한다.
SHOW STATUS LIKE 'Handler_%';
/*
+------------------+-----+
|Variable_name |Value|
+------------------+-----+
|Handler_read_key |0 | 인덱스 탐색 횟수
|Handler_read_next |0 | 인덱스 스캔 시작
|Handler_read_prev |0 | 인덱스 스캔 마무리
| .... |... |
+------------------+-----+
*/
인덱스의 파일시스템 기록과정은 대략 아래와 같다.
인덱스 초기화
DB 시작시 기존에 영구 저장소(파일시스템) 에 저장된 인덱스 데이터를 로드, 인메모리 인덱스 구조로 초기화
인덱스 영구 저장소 기록
인메모리 인덱스 데이터를 직렬화하여 주기적으로 또는 특정 이벤트(시스템 종료, 체크포인트 도달)가 발생했을 때 파일 시스템에 기록한다.
장애발생으로 인한 강제 종료시에는 DB 로그를 참고하여 인덱스 데이터의 일관성과 영구성을 보장한다.
MySQL 지원 인덱스
멀티밸류 인덱스
JSON 타입 칼럽에 사용하는 인덱스
배열이나 객체에 대해 인덱스 설정이 가능하다.
CREATE TABLE tbl_json_user
(
user_id BIGINT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(10),
last_name VARCHAR(10),
credit_info JSON,
INDEX mx_creditscores ((CAST(credit_info -> '$.credit_scores' AS UNSIGNED ARRAY))
) );
INSERT INTO tbl_json_user VALUES (1, 'Matt', 'Lee', '{"credit_scores":[360, 353, 351]}');
SELECT * FROM tbl_json_user WHERE 360 MEMBER OF(credit_info->'$.credit_scores');
클러스터링 인덱스
InnoDB 스토리지 엔진 에서 제공하는 클러스터링 인덱스 는 primary key 기준으로 비슷한 레코드를 묶어서 저장하는 방법, 인덱스에 의한 저장 방법이기 때문에 클러스터링 테이블 방법이라 부르기도 한다.
클러스터링 인덱스 를 사용하면 primary key 에 의해 데이터 레코드의 물리적 저장위치가 결정되어 [DELETE, INSERT, UPDATE] 에선 느리지만,
대부분 웹서비스의 읽기/쓰기 비율이 1:9 ~ 2:8 정도이기에 사용하는것을 권장한다.
InnoDB 스토리지 엔진 에서 기본 사용되며 이런 특성으로 인해 인덱스를 생성하면, 해당 생성한 인덱스가 바로 데이터 레코드 주소를 가리키는것이 아닌 primary key 를 가리킨다.
primary key, 인덱스 모두 없는 테이블의 경우에도 클러스터링 인덱스 사용을 위해 내부적으로 레코드의 일련번호 칼럼을 생성한다.
primary key 를 거쳐가는 과정에서 인덱스 탐색 과 인덱스 스캔 이 한번씩 더 일어나기 때문에 비효율적이라 생각할 수 있지만 primary key 를 기준으로 검색하는 경우에는 빠른 성능을 보장한다.
이런 특성 때문에 클러스터링 될 수 있는 유의미한 값으로 primary key 를 직접 지정하는 것을 권장하고, 필요하다면 복합 인덱스로 primary key 를 사용하는 것도 좋다.