JVM!
개요
클래스로딩
java HelloWorld 명령을 내려 자바 애플리케이션을 실행하면 OS는 JVM 바이너리를 구동한다.
JVM 이 초기화된 후 HelloWorld 클래스 파일의 main 메서드가 실행된다.
이 과정 전에 클래스로딩 매커니즘이 실행된다.
사슬처럼 줄지어 연결된 클래스로더가 차례차례 작동한다.
- 부트스트랩 클래스로더가 최소한의 필수 클래스인 런타임 코어 클래스를 로드한다.
런타임 코어 클래스는[Object, Class, ClassLoader]클래스를 뜻한다. - 부트스트랩 클래스로더가 확장 클래스로더 를 생성한다.
확장 클래스로더는[네이티브 코드, OS 의존 코드]관련 클래스를 로드한다. - 확장 클래스로더가 어플리케이션 클래스로더 를 생성한다.
지정한classpath의 모든 클래스를 로드한다.
각 클래스로더들은 사슬처럼 이어져 있으며 JVM 이 import 문을 만나면 클래스로더가 로드한 클래스들을 탐색하며 클래스파일을 찾는다.
결국 최상위 클래스로더가 찾지 못하면 ClassNotFoundException 이 발생한다.
JMM(Java Memory Model)
대부분 JVM 구현체는 스레드 하나당 OS 스레드 하나에 매핑되는 구조이다.
자바의 멀티스레드는 아래 설계 원칙을 가진다.
- 모든 java 스레드는 하나의 JVM 공용 heap 을 가진다.
- 스레드간 객체참조가 가능하다.
만약 스레드A 가 사용중인 객체를 스레드B 가 변경한다면, 스레드A 가 실행하는 코드에서 에러가 발생할 수 있다.
JMM에서 동시접근을 제어하는 Concurrency Control(동시제어)을 제공한다.
핫스팟 가상머신
1999/4, Sum Microsystems 에서 핫스팟 가상머신을 선보였다.
기존에 빠른 동작속도를 보장하려면 플렛폼에 맞는 특정 기계어로 컴파일하는 AOT(Ahead-of-Time) 사전 컴파일을 사용했는데 많이 번거롭다.
최근 추세는 코드를 자동으로 알아서 native code 로 생성하고 실행하는 편이다.
핫스팟 가상머신은 이런 추세에 따라 자동으로 Interpreted byte code 에서 native code 코드로 컴파일을 제공하는데 JIT(Just-in-Time) 컴파일이라 부른다.
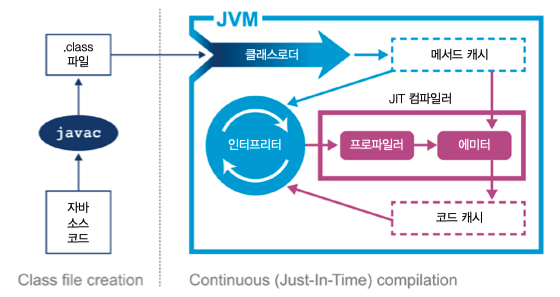
javac 를 이용해 컴파일하여 byte code를 생성한다.
byte code는 특정 시스템에 제한되지 않는 중간표현형(IR: Intermedia Representation) 형태이다.
javap 와 같은 역어셈블리 툴로 다시 java 코드로 확인할 수 도 있다.
핫스팟 가상머신의 가장 큰 목적은 코드를 변환하면서도 오버헤드를 최소한으로 줄이는 것이다.
java 가 업데이트 되며 핫스팟 가상머신이 많을 발전을 이루었음으로 최신 java 버젼 사용을 권장한다.
java 에서 사용하는 변수는 아래 2가지 종류만 있다.
- 기본형(byte, int, boolean 등)
- 객체참조형
코드에 사용한 객체참조변수는 핫스팟 런타임시 OOP 로 변경되어 사용된다.
Ordinary Object Pointer: 평범한 객체 포인터.
흔히 객체참조변수라 부르며 힙 내부를 가리킨다.
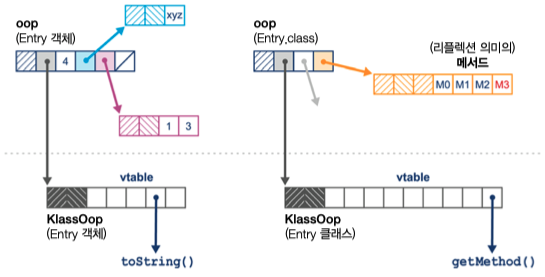
OOP 는 [Mark 워드, Klass 워드] 로 시작된다.
- Mark 워드: OOP 메타데이터 시작지점
- Klass 워드: 클래스 메타데이터 시작지점
객체 Depth 에 따라 OOP 객체 또한 트리처럼 구성된다.
klassOop 는 JVM 클래스로더가 로드한 Class 객체를 JVM 수준에서 나타낸 구조체
OS bit 별로 표기한 Integer 클래스의 OOP 는 아래와 같다.
Integer i = new Integer(23);
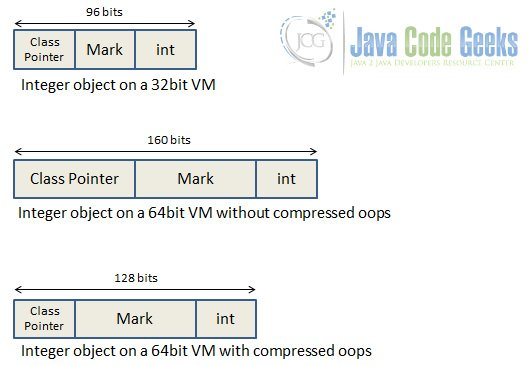
https://www.javacodegeeks.com/2016/05/compressedoops-introduction-compressed-references-java.html
OOP 는 객체종류에 따라 조금씩 다른데 아래와 같은 형태가 존재한다.
- instanceOop (인스턴스 객체)
- methodOop (메서드 표현형)
- arrayOop (배열 추상 베이스)
- symbolOop (내부 심볼 / 스트링 클래스)
- klassOop (Klass 헤더)
- markOop
GC(Garbage Collection)
GC(Garbage Collection) Process 가 자동으로 힘 메모리를 관리한다.
불필요한 메모리를 회수, 재사용하는 불확정성 프로세스이다.
아래는 모든 버전의 GC 에서 사용되는 용어로 참고.
STW(Stop the world)
GC 가 동작하는 동안 모든 어플리케이션 스레드가 중단된다.
대부분 단순한 GC 알고리즘에서 STW 가 일어난다.
GC루트
메모리의 고정점(anchor point), 힙 내부 객체를 가리키는 객체참조변수 또한 가장 단순한 형태의 GC루트 라 할 수 있다.
할당 & 수명
할당률: 일정기간(MB/s) 동한 객체가 사용한 메모리량
객체수명: 객체가 메모리상에 존재하는 시간
Mark-and-Sweep
Mark-and-Sweep 기반으로 메모리를 자동회수한다.
객체들이 할당되어있는 할당리스트를 순회하면서 참조된 변수가 있는지 체크(mark) 하는 방식이다.
mark 가 없는 객체들은 메모리를 회수하고 할당리스트에서 삭제한다.
Mark-and-Compact
Mark-and-Sweep 가 가지고 있는 메모리 파편화 단점을 보완하기 위해, Compact 과정 을 추가로 진행하는 방법.
약한 세대별 가설(Weak Generational Hypothesis)
여기서 설명하는 내용들은 GC 종류 상관없이 대부분 통용되는 지식이다.
객체수명은 bimodal(쌍봉)분포 양상을 보인다.
수명이 아주 길거나, 짧은 극단적인 양상이다.
GC 는 짧은 객체수명을 가진 단명객체를 최대한 빠르게 수집할 수 있어야 하는데
이때문에 장수객체와 단명객체를 별도의 메모리 공간으로 관리하기 위해 카드 테이블 자료구조를 사용한다.
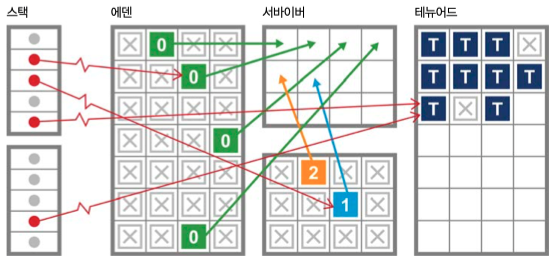
에덴이 모두 찰 경우 더이상 사용하지 않는 개체들을 수집해서 비우는데, 이 작업을 영세대수집, MinorGC, Stop And Copy 알고리즘 등으로 부른다.
초창기 GC 에선 영세대수집 이 발생할 때 마다 STW 가 발생하며
살아남은 객체에 몇번살아남았는지 카운팅(세대 카운팅)한다.
영세대수집 에서 오랜기간 살아남은 객체들은 올드영역이라 부르는 테뉴어드 공간으로 배치된다.
프로모션 과정이라 부르며 보통 세대 카운팅이 15 이상일 때 테뉴어드 로 이동시킨다.
테뉴어드 가 다 찰 경우 마찬가지로 더이상 사용하지 않는 객체들을 수집해서 비우는데, 이 작업을 올드세대수집, MajorGC 등으로 부른다.
테뉴어드 의 기본크기는 에덴 의 7배 정도 크기이며 많은 변화가 일어나지 않는 공간이다.
크기가 크다보니 수집기 동작시 STW 시간이 길다.
STW 시간을 조금이라도 단축하기 위해 아래와 같은 기법들을 사용한다.
- 스레드 로컬할당 버퍼
- 반구형 방출 수집기
서바이버 영역을 가리키는 용어로 [From Space, To Space] 가 자주 나온다.
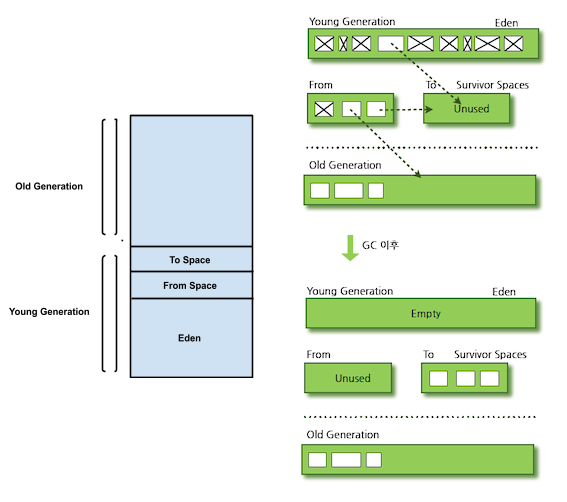
TLAB(스레드 로컬할당 버퍼)
에덴 구역은 스레드별로 관리되는 공간이 나뉘는데 스레드 로컬할당 버퍼(TLAB: Thread Local Allcation Buffer) 이라한다.
다른 스레드가 버퍼공간을 침범할 걱정이 필요없기 때문에 할당복잡도가 O(1) 이다.
자신의 TLAP 버퍼를 다 채울경우 새로운 영역에 TLAP 를 할당해서 포인터를 내어준다.
만약 새로운 새로운 TLAP 영역을 할당 받을 수 없는 상태라면 영세대수집이 발생한다.
스레드를 자유롭게 생성하는건 java 의 장점이지만, 새로운 스레드 스택과 GC 루트들이 생겨나면서 성능을 저하시킬 수 있다.
반구형 방출 수집기
서바이버 공간은 영(Young) 세대 객체수집을 위한 공간으로, 영세대수집이 발생하고 살아남은 객체들이 이동하는 공간이다.
위 그림에서 서바이버 공간이 두개로 쪼개져있는것을 볼 수 있는데, 항상 한 공간이 비워져 있고 영세대수집 이 발생하면 에덴에서 살아남은 객체들과 기존 서바이버내부에 존재하던 객체들이 모두 한 공간으로 이동된다.
위 그림에선 위 공간에 있는 서바이버로 모든 객체들이 이동하는 것을 확인할 수 있다.
이동과정으로 인해 Evacuation Pauses 가 발생하게 된다.
서바이버의 두 공간을 통해 객체를 이동시키는 방식을 반구형 방출 수집(Hemispheric Evacuating Collector) 이라 한다.
조기승격
GC 는 특정시간마다 일어나는 것이 아니라 필요할 때(메모리 공간이 부족할 때) 일어난다.
그렇기 때문에 짧은시간내에 급격하게 많은 객체가 생성될 경우 GC 가 여러번 발생하게 되는데,
이때 실제 자주사용되지 않음에도 단순히 GC 가 많이 호출되면서 세대 카운트가 증가해버리는 객체들이 만들어진다.
많은 양의 의미없는 객체들이 서바이버와 테뉴어드 공간으로 할당되는데 이를 조기승격(premature promotion) 이라 한다.
Safe Point
STW 를 구현하려면 모든 스레드를 중지시켜야 하는데, 이를 위해 Safe Point 방법을 사용한다.
어플리케이션 스레드가 실행하는 명령 사이사이에 세이프포인트 시간 플래그(time to safepoint flag) 를 확인하는 코드를 배치하고,
플래그값에 따라 CPU 제어권을 반납하는 코드(배리어)를 실행한다.
일반적으로 인터프리터에서 바이트코드 2개를 실행할 때 마다 플래그를 체크한다.
그리고 컴파일 과정에서도 [메서드 반환, 루프 회차] 등의 코드 직후에 플래그를 체크할 수 있는 코드를 삽입한다.
를 세팅해서 어플리케이션 스레드가 수행될 수 있도록 한다.
GC 종류
java 에서 GC 는 pluggable subsystem 으로 취급되며 여러 GC 를 같은 java 코드에 적용할 수 있다.
GC 별로 성능이 다르게 나오며 평가하는 항목은 아래와 같다.
- 중단시간: 중단 길이 또는 기간이라고도 함
- 처리율: 애플리케이션 런타임시간과 GC 시간 비율
- 중단빈도: 애플리케이션이 중단 빈도수
- 회수효율: GC 당 가비지가 수집 양
- 중단일관성: 중단시간 빈도
JVM 이 발전하면서 GC 종류도 들어나는데 아래와 같은 종류의 GC 들이 개발되었다.
개발된 년도부터 JVM 버전까지 모두 다르지만 대부분 LTS 버전의 JVM 에서 모든 GC 가 동작한다.
- Serial(JVM 1.0 - 1.3)
- Parallel(JVM 1.4 - 1.7)
- CMS(JVM 1.4)
- G1(JVM 1.5)
- Shenandoah(JVM 8 ~ JVM 11)
- ZGC(JVM11 ~ 현재)
삼색마킹
CMS 이후부터 STW 시간을 줄이기 위해 어플리케이션 스레드와 GC 스레드가 동시에 진행될 수 있도록 하는 알고리즘, [흰색, 회색, 검정색] 색깔을 사용해 GC 활동을 지원하는 이론이다.
- 흰색(White)
초기 표시 과정에서 모든 객체는 흰색으로 시작. - 회색(Gray)
객체가 방문되었지만 해당 객체의 참조들은 아직 탐색되지 않은 상태. - 검은색(Black)
해당 객체와 해당 객체의 참조들이 모두 탐색된 상태. 검은색 객체는 라이브 객체 로 간주하여 GC 대상에 포함되지 않는다.
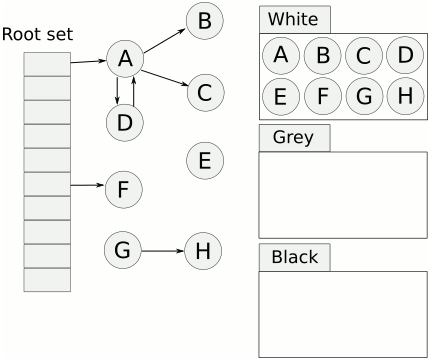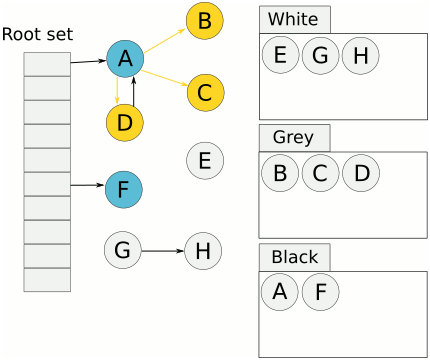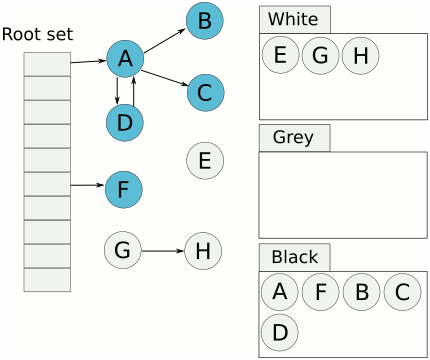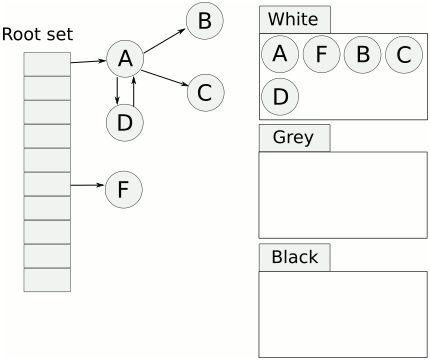
- 기본적으로 객체는 모두 흰색 표시한다.
- GC 루트가 가리키는 객체를 방문하고 회색 표시. 그후 마킹스레드가 회색 객체로 랜덤하게 이동한다.
- 방문한 회색 객체는 검은색 표시하고 이 노드가 가리키는 모든 흰색 객체를 회색으로 표시한다.
- 이 과정을 회색 객체가 하나도 남지 않을 때까지 반복한다.
위 조건들로만 GC 처리를 하려면 STW 가 발생해야 한다.
이유는 위 과정에서 갑자기 나타난 흰색객체를 검정객체가 참조할 경우, 위의 조건들이 해당되지않아 흰색객체 검은객체에 참조됨에도 불구하고 결국 사라지게 되기때문.
삼색마킹에서 Concurrent marking(동시 마킹)을 가능하게 해주기 위해 SATB(snapshot at the beginning), 일단 스냅샷 뜨기 기법을 사용한다.
SATB 는 위의 삼색마킹 조건대로 진행하되, 새로 추가되거나 변경되는 객체들은 GC 수집조건에 포함되지 않도록 설정하는 것이다.
아래조건을 수행한다.
- 마킹 중 생성객체는 검은색으로 표시한다.
- 마킹 중이 아니라면 생성객체는 흰색으로 표시한다.
- 어플리케이션 스레드에 의해 흰색 객체는 언제든지 검은색객체에 의해 참조될 수 있다. 검은색 객체가 새로이 흰색객체를 참조하게 되면, 검은색 객체를 회색으로 변경하여 GC 시작을 늦춘다.
CMS
CMS(Concurrent Mark-Sweep) 는 올드세대 전용 수집기이다.
영세대 수집을 위해 ParNew GC(멀티스레드 GC) 와 함께 사용한다.
삼색마킹을 기반으로 Major GC 를 진행하며 STW 는 [초기 마킹, 재마킹] 두 과정에서만 일어난다.
나머지 과정은 어플리케이션 스레드와 동시에 진행된다.
- 초기 마킹 (Initial Mark), STW
어플리케이션 스레드를 잠시 중지하고 GC 루트로부터 도달 가능한 객체들을 회색으로 표시.
STW 를 진행하기 때문에 확실한 GC 루트를 얻을 수 있다. - 동시 마킹 (Concurrent Marking)
삼색마킹을 적용, 초기 마킹으로부터 얻을 객체들과 자식객체들을 회색, 검은색으로 마킹해 나간다. - 동시 사전 정리 (Concurrent Precleaning)
재마킹 단계에서 STW 시간을 줄이기 위해 동시 마킹 과정중 변화한 객체들의 마킹을 조정한다.
회색 객체들 중에서 더 이상 참조되지 않는 객체들을 식별하여 삭제하거나 상태를 변경한다. 이를 통해 실제 마크-스위프 단계로 진입했을 때의 작업량을 줄이고 정지 시간을 최소화합니다. - 재마킹 (Remark), STW
동시 사전 정리이후 변경된 객체들의 상태를 다시 검사하고 마킹하는 과정,
새로 추가된 객체들을 점검할 때 짧지만 STW 가 발생한다. - 동시 스위프 (Concurrent Sweeping)
흰색 객체들을 회수하여 메모리에서 제거, 기존 검은색과 회색으로 처리된 객체들은 흰색으로 되돌린다.
기본적으로 가용 스레드 절반을 동원해 CMS의 동시 단계를 수행하는데 사용하고, 나머지 절반은 애플리케이션 스레드로 활동한다.
만약 어플리케이션 사용량이 늘어 에덴 영역이 꽉 차서 더이상 어플리케이션 스레드가 실행할 수 없는 경우 영세대 수집이 발생하면서 STW 가 발생하는데,
CMS 때문에 스레드가 절반 밖에 남아있지 않는 상황이기 때문에 기존 Parallel GC 만 사용하는 것보다 느리다.
만약 어플리케이션 사용량이 폭발적으로 늘어 조기승격이 급하게 늘어 테뉴어드 영역까지 꽉 차게될 경우, 메모리 파편화로 인해 테뉴어드 공간이 부족해질 경우,
CMF(Concurrent Mode Failure) 가 발생하며 모든 스레드를 멈추고 Parallel GC 의 수집방식으로 돌아간다.
G1 GC
G1(Garbage-First) 은 java6 에서 공개되어 java8 부터 범용사용되기 시작한 수집기, java9 부터 기본 GC 로 사용되고 있다.
아래 그림과 같이 세대마다 연속된 메모리공간을 구성하지 않고 Region 단위(chunk)로 힙을 관리한다.
1MB ~ 64MB 크기로 Region 단위를 지정한다.
거대영역은 Region 의 절반 크기를 초과하는 객체를 저장하기 위한 공간이다.
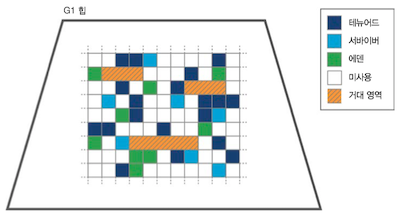
Garbage만 있는 Region 만 빠르게 회수하기 위해 Garbage-First 라 부른다.
CMS 의 약점이었던 메모리 파편화를 해소하기 위해 Compaction 과정을 지원한다.
G1 의 Major GC 사이클은 아래와 같다.
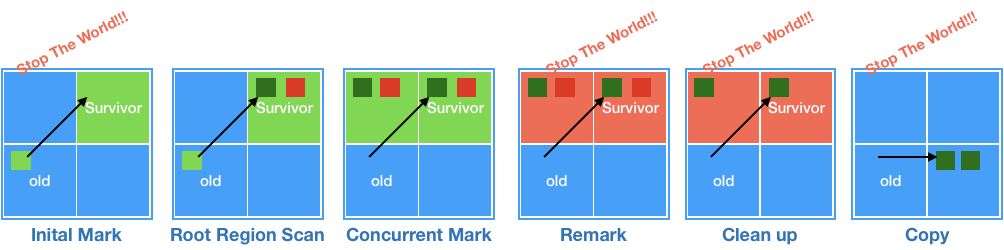
- 초기 마킹(Initial Mark), STW
GC 루트로부터 살아있는 객체를 마킹 - 루트 Region 탐색(Root Region Scan)
서바이버공간에서 테뉴어드의 객체를 가리키는 레퍼런스를 찾는 동시 단계, - 동시 마킹(Concurrent Mark)
전체 힙에 대해 스캔 작업을 진행하며, GC 대상 Region을 선별한다. - 재마킹(Remark), STW
최종적으로 GC 대상 객체를 선별한다. - 정리(Clean up), STW
살아남을 객체가 가장 적을 Region을 우선으로 GC 를 진행, 자유공간이 되어 재사용 준비를 하는 어카운팅 과정, RSet 을 업데이트하는 스크러빙 과정을 진행한다. - 복사(Copy), STW 완전히 비워지지 않은 Region을 비우기 위해 다른 Region으로 복사하여 Compaction 작업을 수행한다.
G1 에선 GC 진행할 때 [RSet, CSet] 을 사용한다.
RSet(Remember Set)
Region별로 하나씩 구성되며 힙 외부에서 내부참조를 관리하기 위한 자료구조.
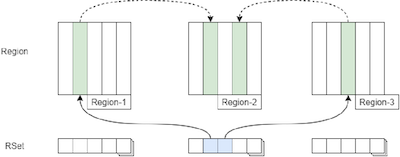
위 그림과 같이 Region별로 하나의 RSet 이 구성되며, Region-2 의 객체를 참조하는 외부 객체 2개의 위치를 RSet 에서 관리한다.
만약 RSet 이 비어있다면 해당 Region의 객체를 참조하는 객체는 없다고 할 수 있다.
CSet(Collection Set)
가비지 컬렉션 대상, 일부 Region을 CSet으로 선택하여 가비지 컬렉션 대상으로 지정한다.
셰난도아
G1 를 기반으로 하는 셰난도아(Shenandoah) 는 레드햇에서 공개한 수집기로, 다른 GC 와 조금씩 다른점을 가진다.
셰난도아는 G1과 다르게 세대별로 저장공간을 구분하지 않고 Single-Generational 을 사용한다.
세대별 가설이 현재와서는 적당하지 않은 가설이라 생각하기 때문.
따라서 Young → Old 세대로 복사로 인한 오버헤드가 발생하지 않는다.
이는 향후 소개할 ZGC 에서도 마찬가지이다.
셰난도아의 가장 큰 특징은 동시 객체 이동(Concurrent Evacuation)을 지원하는 것이다.
다른 GC 들은 파편화를 막기위해 객체 이동(재배치) 시 항상 STW 가 발생했지만 셰난도아에선 어플리케이션 스레드와 동시에 동작한다.
동시 객체 이동은 Region 의 Compaction 을 위한것으로동시 압착 알고리즘이라 부르기도 한다.
동일한 객체가 두개의 메모리 공간에 존재하기 때문에 어플리케이션을 멈추지 않고 객체를 이동시킬 경우 동시성 이슈가 발생할 수 있는데,
이를 해결하기 위해 포워딩 포인터 기법을 사용한다.
아래 그림과 같이 셰난도아에선 OOP 헤더 앞에 브룩스 포인터(Brooks Pointer)를 붙여 관리한다.
(보라색, 주황색 박스안 8byte 크기의 포워딩 포인터)
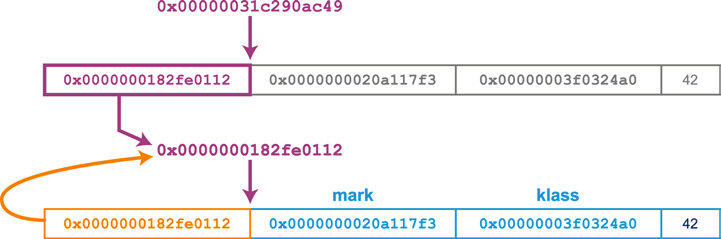
브룩스 포인터를 사용해 GC 과정에서 객체가 재배치 되었는지 확인 가능하다.
그림처럼 기존(회색) 객체가 새로운 공간(파랑색) 으로 이동될 때, 기존 객체의 브룩스 포인터가 이동된 객체의 새로운 위치를 가르키기 때문에 객체 이동으로 인한 동시성 문제가 발생하지 않는다, 이를 self-healing 구조라 부른다.
객체의 이동과 포인터 변경은 하드웨어 레벨에서 관리하는
Compare & Swap원자성 명령으로 진행되기 때문에 스레드 safe 하다.
셰난도아의 GC 사이클은 아래와 같다.
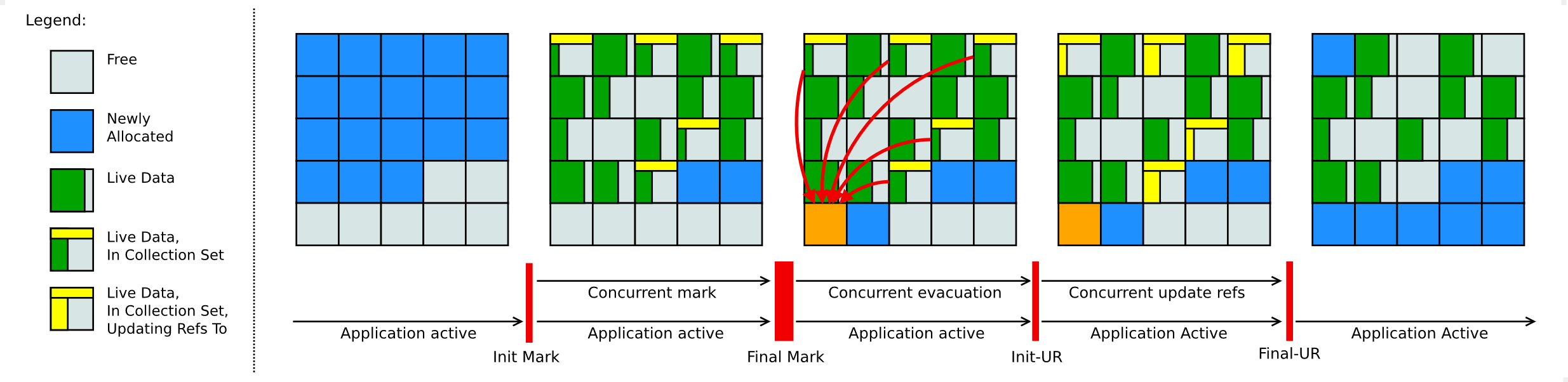
- 초기 마킹(Initial Mark), STW
GC 루트를 스캔, 사용중인 객체들 탐지 - 동시 마킹(Concurrent Mark)
사용중인 객체들에 대한 마킹 - 최종 마킹(Final Mark), STW
GC 루트를 다시 검사하고 동시 마킹에서 부족한 부분을 처리.
삭제와 이동을 위한 객체를 정확히 구분하기 위한 과정. - 동시 정리(Concurrent Cleanup)
위 그림에는 없지만 참조가 없는 객체는 정리된다. - 동시 이동(Concurrent Evacuation) 메모리 파편화를 막기 위해 영역간 객체 이동.
- 초기 참조 업데이트(Init Update Refs), STW
Update References 단계 시작, 모든 GC 스레드가 Evacutaion 완료하였는지 확인하는 과정. - 동시 참조 업데이트(Concurrent Update References)
동시 정리,동시 이동간에 발생한 참조 업데이트. - 최종 참조 업데이트(Final Update Refs), STW
GC 루트 업데이트. - 동시 정리(Concurrent Cleanup)
모든 과정이 끝나고 참조없는 객체를 정리한다.
Azul C4
https://studylib.net/doc/18395951/azul-pauseless-garbage-collection
C4 (Continuously Concurrent Compacting Collector) Azule 사에서 만든 수집기. Azule Zulu, Azule Zing 이라는 JVM 에서 사용되고 세대별 가설을 사용한 GC 이다.
C4 의 3가지 과정에서의 각종 동작을 설명한다.
- 마킹(Mark)
- 재배치(Relocate)
- 재매핑(Remap)

마킹
Azule Zing 에선 단순 힙에서 살아있는 객체를 찾는 것 뿐만 아니라,
아래와 같은 별도 관리하는 객체 레퍼런스 구조체가 존재한다.
struct Reference {
unsigned inPageVA : 21; // 0-20비트
unsigned PageNumber: 21; // 21-41비트
unsigned NMT : 1; // 42비트
unsigned SpaceID : 2; // 43-44비트
unsigned unused : 19; // 45-63비트
};
NMT(not marked through) 를 통해 현재 수집 사이클에서 객체가 이미 마킹됐는지 여부를 알 수 있다.
Azule Zing 에선 Mark 와 Remap 과정이 동시에 이루어지기 때문에, NMT 는 향후 접근해도 안전한 객체인지 확인할 때 사용된다.
객체 레퍼런스 구조체는 Remap 과정의 Compaction 최적화에도 사용된다.
재배치(Relocate)
재배치 단계에선 죽은 객체의 메모리를 회수하고 Compaction 을 진행한다.
C4 에서도 동시이동을 지원한다, 동시성 문제를 처리하기 위해 셰난도어의 브룩스 포인터 와 같은 포인터 구조 대신
LVB(Load Value Barrier, 로드값 배리어) 구조를 사용한다.
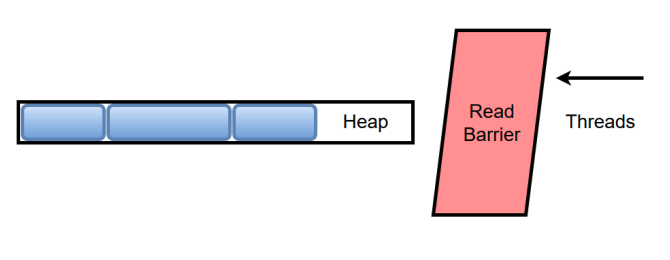
위 그림과 같이 어플리케이션 스레드는 Read Barrier 를 통해서만 객체에 접근가능하고,
LVB 에선 안전한 접근을 위해 NMT 에 마킹된 객체만 접근 가능하도록 강제한다.
또한 LVB 는 항상 이동 완료된 객체만 접근할 수 있도록 강제하는데, 이러한 과정은 트랩 코드 에 의해 이루어진다.
트랩 코드 가 객체를 새로운 공간에 재배치할 때 까지 LVB 는 From Space 에 어플리케이션 스레드의 접근을 지연시키고,
객체가 완벽하게 이동될때 까지 From Space 의 객체가 저장되어있는 공간을 보호하고, 해당 주소를 별도의 공간(Forwarding Pointer) 에 저장해둔다.
GC는 객체의 원래 주소와 새 주소를 추적하면서 재배치한다.
재배치가 완료되면 기존에 지연되었던 어플리케이션 스레드에게 알림을 보내고 새롭게 이동된 객체 위치를 반환한다.
트랩 코드는 수집기가 전체 페이지 재배치를 완료할 때까지 기다리지 않기 때문에 빠르게 어플리케이션 스레드가 다시 동작할 수 있도록 지원하고, 앞으로 LVB 접근시 새 주소를 제공하기 때문에 self-healing 이라 부른다.
새 위치만 참조시키면 되기 때문에 기존 객체는 어떠한 작업도 할 필요가 없다.
재매핑(Remap)
모든 재배치 된 객체의 이전 참조값을 모두 없애는 과정이다.
저장해 두었던 Forwarding Pointer 도 모두 삭제한다.
재매핑 단계와 마킹 단계가 섞여서 실행되기 때문에 살아있는 객체를 찾고 재배치 완료된 객체를 다시 가리키는 작업이 수행된다.
수집 주기가 다름에도 마킹, 재매핑 단계가 결합되어 실행된다.
<!–
ZGC
ZGC(Z Garbage Collector) 는 JDK15 ~ JDK17 의 정식 GC로 반영되었다.
그림처럼 크기별로 [Small, Medium, Large] Region 을 나눠 관리하고 ZGC는 Region을 ZPage로 정의한다.
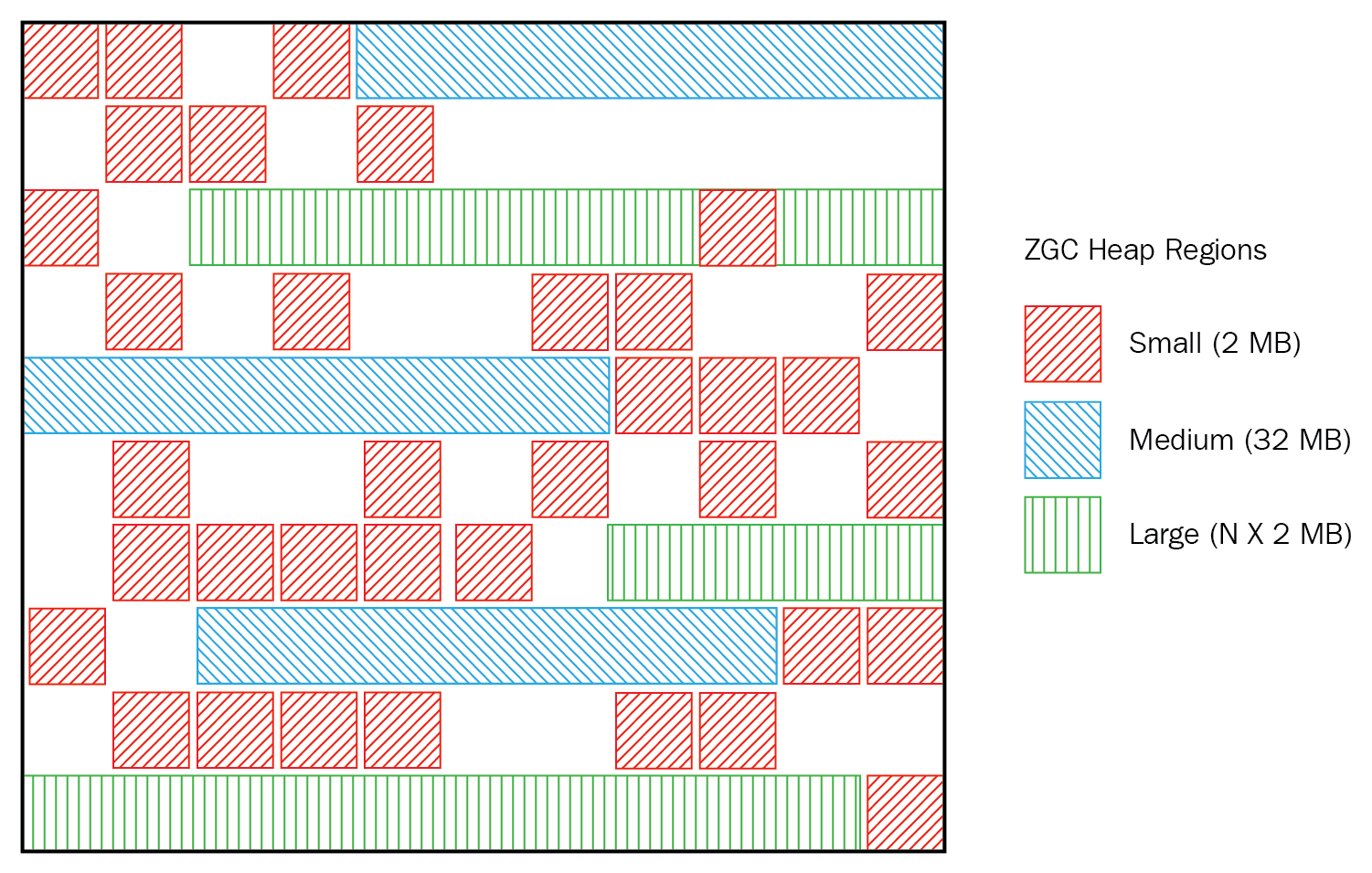
Large Region 는 가변크기인데 단 하나의 객체만 할당 가능하다.
최적화 기법
성능테스트
vmstat -w -t 2
procs -----------------------memory---------------------- ---swap-- -----io---- -system-- --------cpu--------
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 49500 219624 494432 10087332 0 0 0 2 0 0 0 0 100 0 0
0 0 49500 218980 494432 10087344 0 0 0 68 889 2020 0 0 100 0 0
0 0 49500 217616 494432 10087344 0 0 0 22 902 2055 0 0 100 0 0
0 0 49500 217128 494432 10087344 0 0 0 0 904 2070 0 0 100 0 0
0 0 49500 216988 494432 10087360 0 0 0 48 914 2046 0 0 100 0 0
0 0 49500 216740 494432 10087360 0 0 0 0 873 2002 0 0 100 0 0
0 0 49500 216756 494432 10087360 0 0 0 56 895 2012 0 0 100 0 0
0 0 49500 215020 494432 10087360 0 0 0 122 908 1985 0 0 100 0 0
0 0 49500 214632 494432 10087380 0 0 0 0 888 2042 0 0 100 0 0
0 0 49500 214012 494432 10087380 0 0 0 36 892 2029 0 0 100 0 0
0 0 49500 214012 494432 10087384 0 0 0 8 868 2027 0 0 100 0 0
iostat 1
disk0 cpu load average
KB/t tps MB/s us sy id 1m 5m 15m
91.46 83 7.39 9 5 86 2.76 3.02 2.72
4.00 17 0.07 4 2 94 2.76 3.02 2.72
14.88 50 0.72 4 2 94 2.76 3.02 2.72
- procs
r: 실행가능한 프로세스
b: 블록킹된 프로세스 - memory
swpd: 스왑 메모리 크기
free: 미사용 메모리 크기
buff: 버퍼 메모리 크기
cache: 캐시 메모리 크기 - swap
si: 스왑인 메모리
so: 스왑아웃 메모리 - io
bi: 블록인 개수
bo: 블록아웃 개수 - system
in: 인터럽트 개수
cs: 문맥교환 개수 - cpu us: 유저시간 sy: 커널시간 id: 유휴시간 wa: 대기시간
GC 로깅
–>