헥사고날 아키텍처!
개요
만들면서 배우는 클린 아키텍처
https://www.yes24.com/Product/Goods/105138479
https://github.com/thombergs/buckpal
계층형 아키텍처
전통적인 계층형 아키텍처는 아래와 같이 간결한 요청 흐름이 장점인 아키텍처이다.
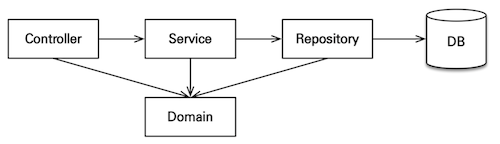
단점은 모든 코드가 도메인에 의존성을 두고 있다보니 도메인 변경되면 다른 코드도 전부 변경되어야 하고,
도메인=DB 라는 강한 매핑관계로 인해 DB 의존적인 아키텍처라 할 수 있다.
점점 망가지는 계층형 아키텍처
시간이 지나면서 서비스 클래스가 의존하는 영속성 계층의 코드가 많아지고
서비스 클래스에 다양한 유스케이스들이 추가되면서 비대한 서비스 클래스가 생성된다.
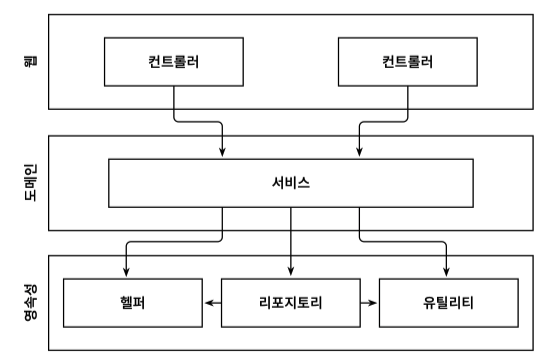
서비스 클래스를 테스트하기도 어려워지고 유스케이스를 책임지는 서비스 클래스를 찾기도 어려워진다
클린 아키텍처는 이러한 계층형 아키텍처에서 발생하는 각종 문제점들을 막기 위해
여러가지 원칙들을 넣은 아키텍처라 할 수 있다.
클린 아키텍처
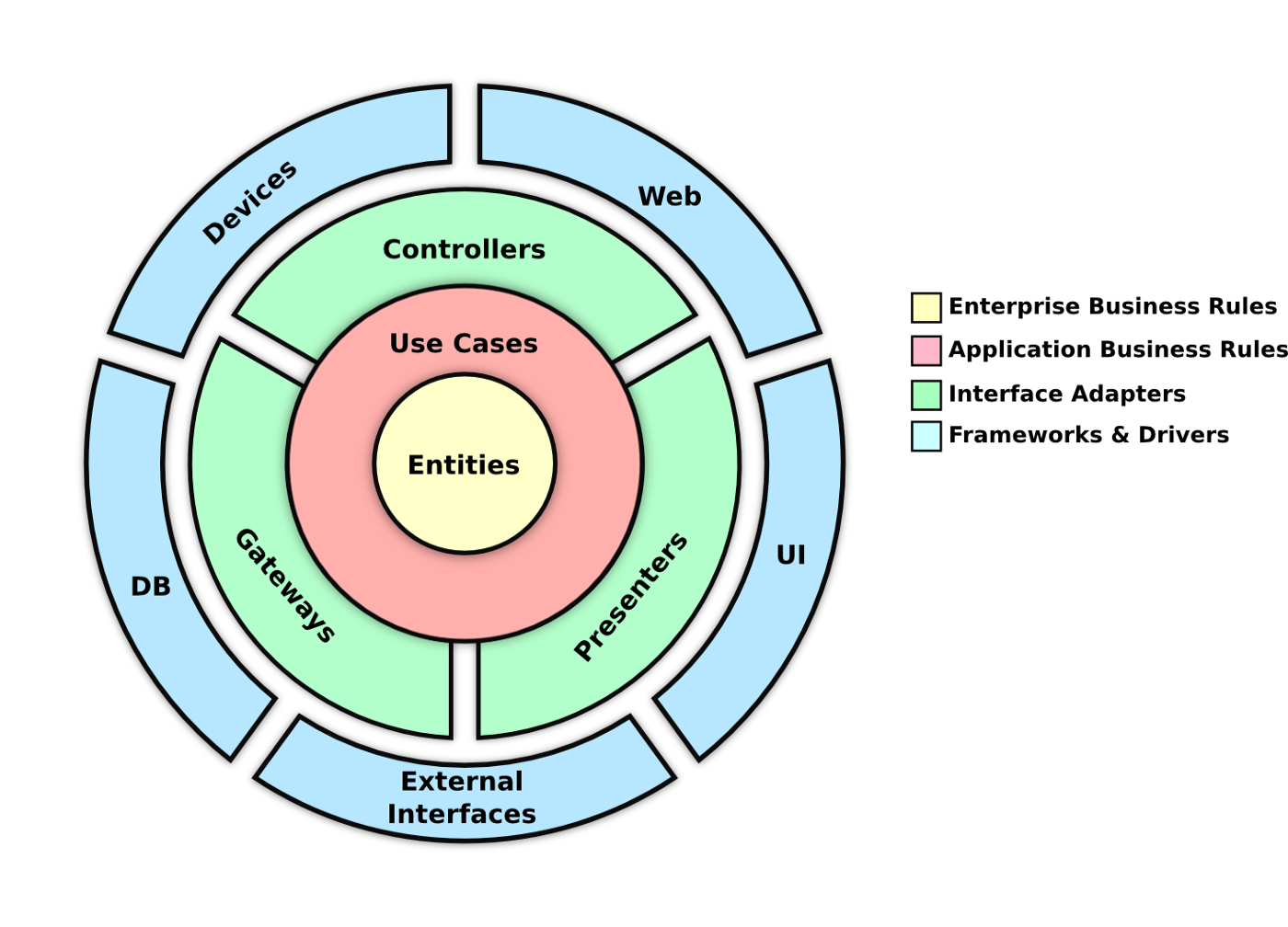
클린 아키텍처는 모든 레이어에 DIP 를 추가해 레이어들간의 의존성을 해결한다.
계층형 서버개발을 자주하였고 JPA(Java Persistence API) 를 사용중이라면 [Entity, Repository] 가 강하게 결합되어,
위 그림처럼 DB(Persistence) 레이어 와 Entity(도메인) 레이어 를 분리해서 생각하기가 어렵다.
클린 아키텍처는 둘 사이에 DIP 개념으로 도메인 레이어 와 DB 레이어 를 분리하고,
도메인 레이어에서 사용할 도메인객체, DB 레이어에서 사용할 엔티티객체를 따로 정의하고 매핑을 통해 데이터를 동기화 시키는 방식을 사용한다.
사용자 계좌를 표시하는 Account 도메인객체
package com.demo.account.domain;
public class Account {
private final AccountId id;
private final Money baselineBalance;
private final ActivityWindow activityWindow;
public static Account withoutId(Money baselineBalance, ActivityWindow activityWindow) {
return new Account(null, baselineBalance, activityWindow);
}
public static Account withId(AccountId accountId, Money baselineBalance, ActivityWindow activityWindow) {
return new Account(accountId, baselineBalance, activityWindow);
}
public Optional<AccountId> getId(){
return Optional.ofNullable(this.id);
}
public Money calculateBalance() {
return Money.add(this.baselineBalance, this.activityWindow.calculateBalance(this.id));
}
public boolean withdraw(Money money, AccountId targetAccountId) {
if (!mayWithdraw(money)) {
return false;
}
Activity withdrawal = new Activity(
this.id,
this.id,
targetAccountId,
LocalDateTime.now(),
money);
this.activityWindow.addActivity(withdrawal);
return true;
}
private boolean mayWithdraw(Money money) {
return Money.add(this.calculateBalance(), money.negate()).isPositiveOrZero();
}
public boolean deposit(Money money, AccountId sourceAccountId) {
Activity deposit = new Activity(
this.id,
sourceAccountId,
this.id,
LocalDateTime.now(),
money);
this.activityWindow.addActivity(deposit);
return true;
}
@Value
public static class AccountId {
private Long value;
}
}
사용자 계좌를 표시하는 Account 엔티티객체
@Entity
@Data
@Table(name = "account")
@AllArgsConstructor
@NoArgsConstructor
class AccountJpaEntity {
@Id
@GeneratedValue
private Long id;
}
도메인 레이어에선 Account 도메인객체를 사용하고,
DB 레이어에선 Account 엔티티객체를 사용한다.
이동 시 매핑방식을 통해 각 레이어에서 사용할 객체로 변환시킨다.
헥사고날 아키텍처
2005년에 Alistair Cockburn 블로그에 소개되었다.
문서로 정리된 클린 아키텍처의 원칙을 코드와 패키지 구조로 표기한 아키텍처이다.
헥사고날 아키텍처 그림을 보면 클린 아키텍처의 원칙을 지키기 위해
DIP에 기반한 패키지 구조, 생성해야할 인터페이스, 구현체 클래스들을 구체적으로 표현한다.
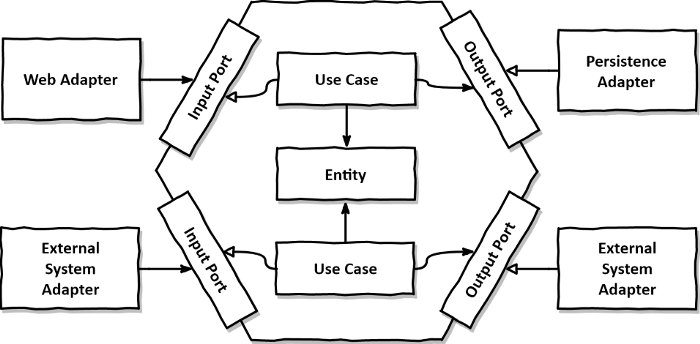
도메인은 유스케이스를 통해 변경이 이뤄저야하고,
DB 를 포함한 모든 외부 시스템들은 [input port, output port] 업뎁터를 통해 데이터를 송수신해야 한다.
그리고 각 레이어간 의존성은 DIP 를 최대한 활용하기 위해 인터페이스를 사용해야 한다.
input port 는 외부에서 들어오기 때문에 어플리케이션을 주도하는 어뎁터라 표현하고,
output port 는 어플리케이션이 호출하기 때문에 주도되는 어뎁터라 표현한다.
이런 특징때문에 포트와 어뎁터(ports-and-adapters)패턴 이라 부르기도 한다.
account 도메인에 대한 헥사고날 아키텍처 패키지 구조는 도메인을 기준으로 아래와 같이 크게 3개 레이어로 나눠져 있다.
- 어뎁터 레이어
- 어플리케이션 레이어
- 도메인 레이어
├── account
│ ├── adapter
│ │ ├── in
│ │ │ └── web
│ │ │ └── SendMoneyController.java
│ │ └── out
│ │ └── persistence
│ │ ├── AccountJpaEntity.java
│ │ ├── AccountMapper.java
│ │ ├── AccountPersistenceAdapter.java
│ │ ├── ActivityJpaEntity.java
│ │ ├── ActivityRepository.java
│ │ └── SpringDataAccountRepository.java
│ ├── application
│ │ ├── port
│ │ │ ├── in
│ │ │ │ ├── GetAccountBalanceQuery.java
│ │ │ │ ├── SendMoneyCommand.java
│ │ │ │ └── SendMoneyUseCase.java
│ │ │ └── out
│ │ │ ├── AccountLock.java
│ │ │ ├── LoadAccountPort.java
│ │ │ └── UpdateAccountStatePort.java
│ │ └── service
│ │ ├── GetAccountBalanceService.java
│ │ ├── MoneyTransferProperties.java
│ │ ├── NoOpAccountLock.java
│ │ ├── SendMoneyService.java
│ │ └── ThresholdExceededException.java
│ └── domain
│ ├── Account.java
│ ├── Activity.java
│ ├── ActivityWindow.java
│ └── Money.java
adapter 패키지에 어뎁터 레이어를 구성하고, 외부시스템과 의 연결점을 표현하기 위한 [in, out] 패키지를 정의한다.
application.port 패키지에 [어플리케이션 레이어, 어뎁터 레이어] 의 연결고리인 [input port, output port] 를 정의한다.
어뎁터 레이어에서 어플리케이션 레이어에 접근하기 위한 DIP 인터페이스,
어플리케이션 레이어에서 어뎁터 레이어에 접근하기 위한 DIP 인터페이스가 정의되어 있다.
DIP 인터페이스로 어플리케이션 레이어 과 어뎁터 레이어 를 철저히 분리해놓았기 때문에 의존성이 완벽하게 분리되어 있다.
따라서 어플리케이션 레이어 에선 DB output port 가 [JPA, JDBC, jooq, MyBatis, NoSQL] 중 어떤 구조를 사용하는지 알 필요가 없고,
어플리케이션 레이어 의 input port 구현체 또한 외부에서 [HTTP, gRPC, Messaging] 중 어떤 입력 방식으로 구현했는지 알 필요가 없다.
어렙터 레이어 에서도 어떤 복잡한 유스케이스가 어플리케이션 레이어에 정의되어있는지 알 필요가 없다.
웹 어뎁터
대부분 서버시스템에서 input port 는 웹 어뎁터를 사용한다.
adapter.in.web 에서 시작되는 웹 어뎁터는 값을 매핑해서 유스케이스의 구현체가 정의되어 있는 application.port.in 패키지로 값을 넘긴다.
웹 어뎁터 내부에서 아래와 같은 작업을들 책임지고 수행한다.
- HTTP 요청을 자바 객체로 매핑 권한 검사
- 입력 유효성 검증(파라미터 형식, 인증, 권한 등)
- 입력을 유스케이스의 입력 모델로 매핑
- 유스케이스 호출
- 유스케이스의 출력을 HTTP로 매핑
- HTTP 응답을 반환
웹 어뎁터 역할을 할 컨트롤러 클래스는 적게 만드는 것 보다 많이 만드는 것을 추천한다.
원할한 테스트코드 작성과 의존성 분리를 위해 최대한 컨트롤러 클래스를 유스케이스별로 쪼개고 여러개의 클래스 생성을 권장한다.
영속성 어뎁터
영속성 어뎁터(JPA) 의 의존코드가 많아질수록 DB 주도 설계 가 되어버린다.
헥사고날 아키텍처에선 어플리케이션 레이어의 코드들이 JPA에 관련해서 모르는 상태로 만들어야 한다.
어플리케이션 레이어의 클래스들이 영속성 어뎁터 의존성을 갖지 못하도록 output port 인터페이스를 사용해 철처하게 DIP 를 지킨다.
주로 아래와 같이 applicaiton.port.out 패키지에 JPA 관련 코드들을 DIP 로 사용할 인터페이스를 정의해두고 사용하는 방식이다.
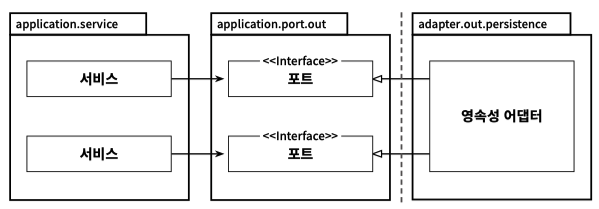
영속성 어뎁터는 아래와 같은 작업들을 책임지고 수행한다.
- 입력을 받는다
- 입력을 데이터베이스 포맷으로 매핑한다
- 입력을 데이터베이스로 보낸다
- 데이터베이스 출력을 애플리케이션 포맷으로 매핑한다
- 출력을 반환한다
applicaiton.port.out에 정의된 영속성 어뎁터가 [JPA, JDBC, jooq, MyBatis, NoSQL] 무엇을 사용하든 application.service 패키지에 있는 어플리케이션 코드들은 알필요 없다.
영속성 어뎁터가 유스케이스에 맞는 메서드만 제공해주면 된다.
웹 어뎁터와 마찬가지로 의존성 분리를 위해 applicaiton.port.out에 정의된 영속성 어뎁터는 최대한 유즈케이스별로 분리하는것을 권장한다.
사용할일 없는 메서드를 가진 영속성 어뎁터로부터 자유로워진다.
계층간 데이터 매핑
웹 어뎁터에서 사용하는 데이터어플리케이션 레이어에서 사용하는 데이터영속성 어뎁터에서 사용하는 데이터
각 레이어에서 사용하는 데이터를 매핑전략에 따라 아래 그림과 같이 4단계로 나눌 수 있따.
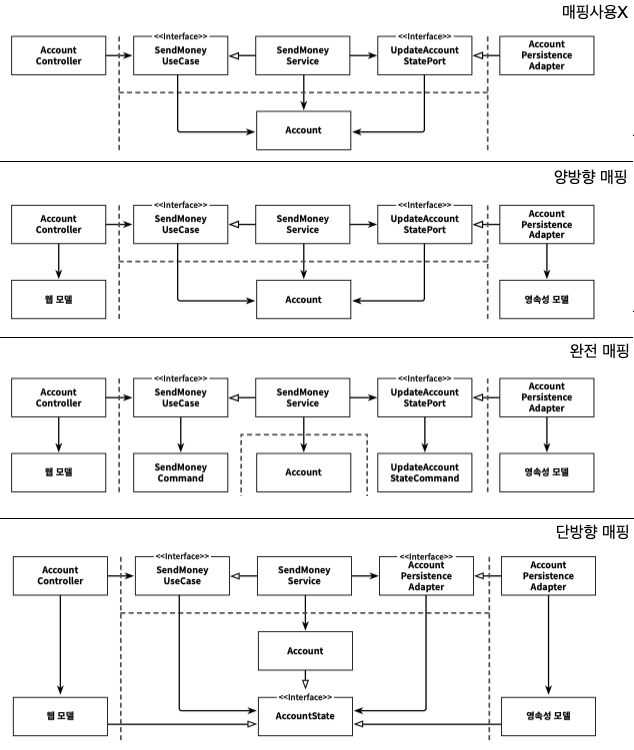
- 매핑사용X - 모든 레이어에서 동일한 모델 데이터 사용.
영속성 코드가 분리되어 있거나 아예사용하지 않을때, 간단한 CRUD 유스케이스에서 사용을 권장한다. - 양방향매핑 - 계층간 이동시 사용하는 모델 데이터 분리.
간단한 CRUD 유스케이스에서 사용을 권장한다. - 완전매핑 - 모든 요청에 별도의 모델 데이터 사용.
어뎁터 계층과 유스케이스의 경계가 명확할 때 사용한다. - 단방향매핑 - 양방향매핑과 비슷하지만 모두 동일한 interface 의 구현체.
매핑을 이전 레이어에게 맡기는 방법. 유연하지만 모호한 방법.
계층간 모델이 비슷할 때 사용한다.
매핑전략을 사용하면 책임이 분리되기 때문에 명확하고 SRP 을 준수한다.
대신 보일러플레이트 코드가 생기고 유스케이스 자체가 변하면 SRP 상관없이 같이 변경해야할 코드도 많아진다.
대부분 양방향매핑을 정석처럼 사용하고 있으며, 그때그때 상황에 맞춰 다양한 매핑전략을 사용하면 된다.
의존성 경계
헥사고날 아키텍처에선 그림처럼 4가지 의존성 경계를 가지는 것을 권장한다.
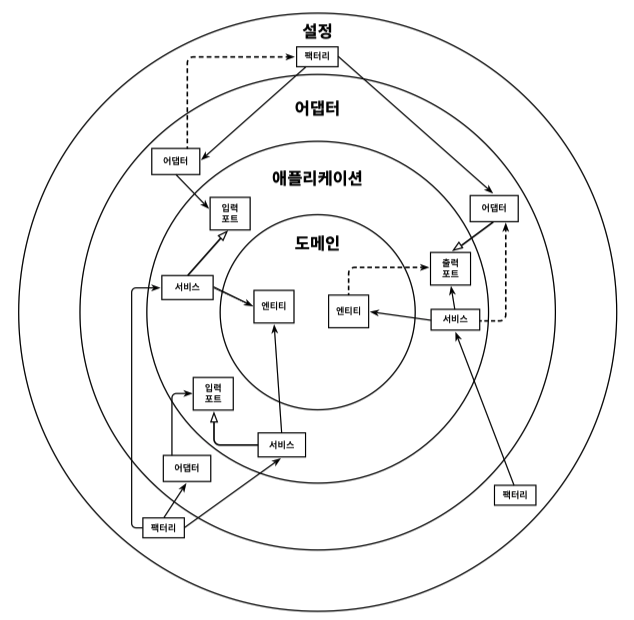
설정 레이어는 스프링 부트의 의존성 주입 구조를 사용할 수 있다.어뎁터 레이어는 외부 통신에 대한 외부의존성을 가진다.어플리케이션 레이어는 유스케이스를 구현하기 위해 도메인 엔티티에 접근한다.
어뎁터 레이어와 어플리케이션 레이어는 항상 이동시에 [input port, output port] 에 정의된 DIP 인터페이스를 통해서만 호출하고 호출된다.
아래와 같이 패키지를 나눴었다.
- adapter
- in(WEB)
- out(DB)
- application
- usecase port in
- usecase port out
- usecase implements service
- domain
DIP 용도로 생성한 interface 외에는 패키지 밖의 객체간 의존성이 발생할 일이 없다.
그럼으로 DIP 로 생성되는 인터페이스 구현 클래스를 제외하고는
모든 클레스들의 메서드 접근제한자를 default(pakcage-private) 으로 설정하는 것을 권장한다.
ArchUnit
ArchUnit 테스트툴을 사용하면 의존성 방향이 설계한 대로 설정돼 있는지 테스트할 수 있다.
testImplementation 'com.tngtech.archunit:archunit-junit5:0.17.0'
// package path
@AnalyzeClasses(packages = "io.reflectoring.buckpal")
class ArchRuleTests {
// domain 이 의존하는 application 클래스가 없는지 체크
@ArchTest
ArchRule domainRule = ArchRuleDefinition.noClasses()
.that()
.resideInAPackage("..domain..")
.should()
.dependOnClassesThat()
.resideInAnyPackage("..application..");
// application 이 의존하는 adapter 클래스가 없는지 체크
@ArchTest
ArchRule applicationRule = ArchRuleDefinition.noClasses()
.that()
.resideInAPackage("..application..")
.should()
.dependOnClassesThat()
.resideInAnyPackage("..adapter..");
}
@AnalyzeClasses, ArchRuleDefinition 의 패키지 문자열에 오타가 발생할 경우 검증하지 않고 넘어감으로, 패키지명을 변경하거나 오타가 나지 않도록 주의가 필요하다.
빌드 아티펙트
의존성 경계를 패키지로 나눌 수 도 있지만 아래와 같이 gradle 멀티모듈구조로 나눠버릴 수 도 있다.
아예 모듈 구조로 나눠버렸기 때문에 아키텍처의 계층간 의존성을 강제할 수 있다.
어느정도로 분리할지는 아래 그림을 참고
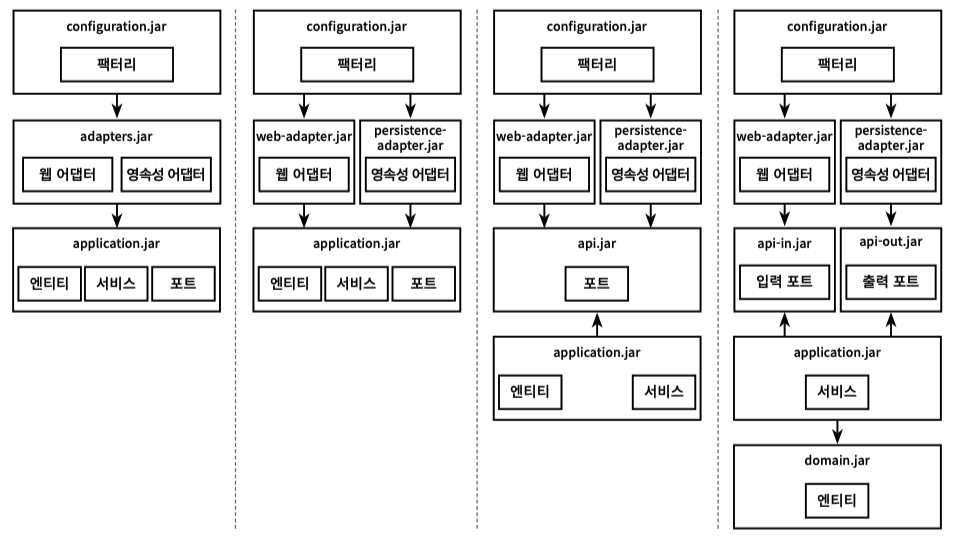
또한 멀티모듈의 각 레이어 의존성 구성할때 gradle 을 통해 명시적으로 정의하기 때문에,
무의식적 실수로 레이어간 의존성을 침범하거나 순환참조를 방지할 수 있다.
모듈관 순환의존은 아예 빌드에러가 발생한다.
빌드 아티펙트가 가져다주는 장점이 많지만 그만큼 컴파일 과정이 늘어나고, 의존관계에 대한 빌드 스크립트가 추가된다.
아키텍처가 어느정도는 안정된 상태에서 빌드 아티펙트로 분리하는 것을 권장한다.
테스트
- 도메인 엔티티를 구현할 때는 단위 테스트로 커버하자
- 유스케이스를 구현할 때는 단위 테스트로 커버하자
- 어댑터를 구현할 때는 통합 테스트로 커버하자
- 사용자가 취할 수 있는 중요 애플리케이션 경로는 엔드투엔드 테스트로 커버하자
지름길
DIP 를 유지하려고 억지로 인터페이스들을 정의하고, 매핑과정을 거치는 일은 상당히 피곤한 일이다.
[어뎁터 레이어, 어플리케이션 레이어]에선 매핑작업을 하지 않고 그냥 도메인 모델을 주고받아도 되지 않을까?
input port 정도는 생략하고 바로 어플리케이션 레이어 서비스 클래스 들을 사용해도 되지 않을까?
유스케이스가 없는 간단한 CRUD 는 어뎁터 레이어에서 모든 작업을 처리해도 되지 않을까?
헥사고날 아키텍처를 사용하면 계속 지름길을 사용하고 싶은 유혹이 생긴다.
실제로 지름길을 사용하면 개발속도가 빨라질 것이다.
유스케이스가 없는 서비스의 경우 지름길을 선택하는것도 좋은 방법이다.
그리고 유스케이스가 생기는 시점부터 지름길을 걷어내고 다시 헥사고날 아키텍처의 원칙을 지켜도 된다.
개인적인 생각으론 지름길 사용하지 않는것이 좋아보인다.
유스케이스가 없는 서비스는 계층형 아키텍처로도 충분하다.
유스케이스가 복잡하거나 복잡해질것 같은 서비스는 헥사고날 아키텍처 원칙을 지키면서 개발한다.