OS - 데드락
Deadlock (교착상태)
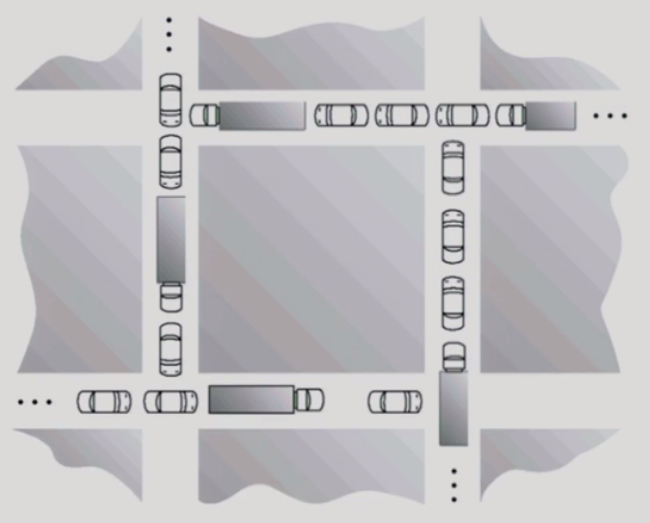
그림처럼 막혀서 더 이상 꼼짝할 수 없는 상태를 교착상태라 한다.
시스템 안에서 Deadlock이란 각각의 프로세스가 자원이 있고 자신의 자원은 절대 포기 안하면서 다른 프로세스의 자원을 기다리는 상태가 맞물리면서 발생되는, 즉 일련의 프로세스들이 서로가 가진 자원을 기다리며 block된 상태이다.
Deadlock이 발생하는 이유는 간단하다, 자원 동시충족을 못하고, 2개 이상의 자원이 필요한데 1개밖에 못 가졌고, 또 얻은 자원을 포기하지 못할 경우 발생한다.

예로 A와 B가 Binary Semaphore 일 때 발생하는 동기화 문제 또한 Deadlock이다.
프로세스가 자원을 사용하는 절차는 Request(요청), Allocate(할당), Use(사용), Release(방출) 4개로 구분된다.
이 과정 중에서 아래의 발생조건 4가지가 모두 충족되면 Deadlock이 발생한다.
아래 4가지 조건을 모두 충족해야 Deadlock 이 발생한다.
한 가지만 해결돼도 발생하지 않는다.
Mutual exclusion (상호 배제)
매순간 하나의 프로세스만이 자원을 사용할 수 있음. 만약 한 자원을 여러 프로세스가 동시에 사용할 수 있다면 교착상태는 발생하지 않는다.
No Preemption (비 선점: 빼앗기지 않는)
프로세스는 자원을 스스로 내어놓을 뿐 강제로 빼앗기지 않음.
Hold and wait (보유 대기)
자원을 가진 프로세스가 다른 자원을 기다릴 때 보유자원을 놓지 않고 계속 가지고 있음.
Circular wait (순환 대기)
자원을 기다리는 프로세스 간 사이클이 형성되어야 함. 위의 도로 그림처럼 프로세스들이 원하는 자원이 꼬리에 꼬리를 물고 늘어지는 것.
자원 할당 그래프
Resource Allocation Graph(자원 할당 그래프) 를 통해 데드락 발생경유를 알아보면
P=Process, R=Resource
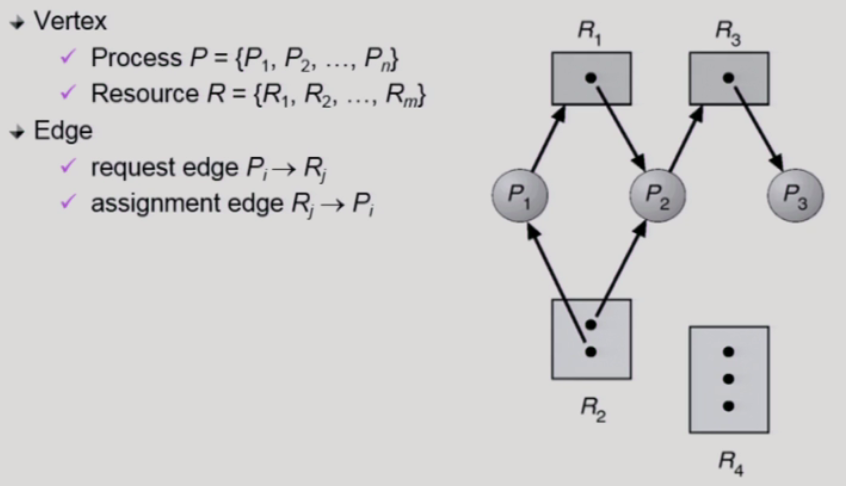
R-->P 는 프로세스가 그 자원을 점유하고 있는 것
P-->R 은 프로세스가 자원을 요청하는 것
R 안의 점은 Instance 로 자원의 개수
Resource Allocation Graph 그래프를 보고 Deadlock 이 생겼는지 확인 가능하다.
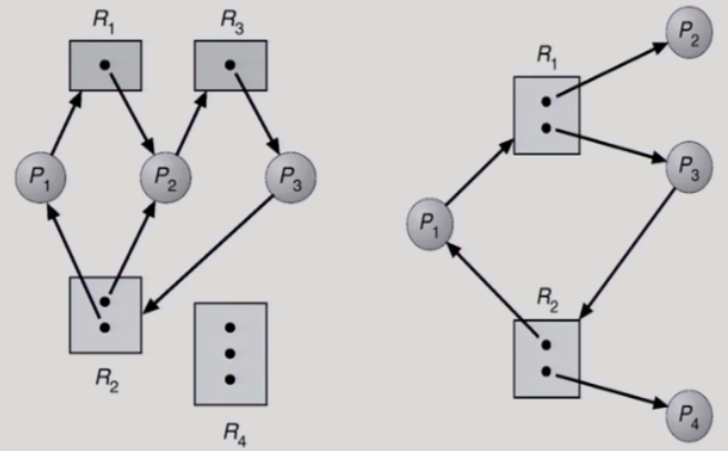
Resource Allocation Graph 에 Cycle 이 있으면 Deadlock 이 발생한다.
왼쪽 그래프는 Cycle 이 있어 Deadlock 이 발생한다.
R2 의 Instance 가 2개나 있지만 Cycle 이 2개다.
만약 R2의 Instance 가 3 개이거나 Cycle 이 1개였다면 Deadlock은 발생하지 않는다.
오른쪽 그래프는 Cycle이 1개이다. 하지만 R2 의 Instance 가 2개이기 때문에 Deadlock 이 발생하지 않는다.
Deadlock Prevention (방지)
Deadlock 은 위의 발생조건 4개를 모두 충족해야 발생한다.
No PreemptionHold and waitCircular waitMutual exclusion
이중 하나만 방지해도 해결되기 때문에
Deadlock Prevention 은 위 발생조건 4가지를 중 하나라도 만족 못하게 하는 것이다.
Hold and wait Prevention
자신이 가진 자원은 절대 내어놓지 않으면서 충족되지 않은 자원을 기다리는 Dead lock조건이다.
첫 번째 방지방법은 프로세스 시작부터 모든 필요한 자원을 프로세스 끝날 때 까지 갖고 가는 방법이 있다, 딱 봐도 낭비가 심한 방법.
두 번째 방법은 특정 자원이 필요할 경우 보유 자원을 모두 내려놓고 자원을 요청하는 방법.
No Preemption Prevention
프로세스가 가진 자원을 뺏을 수 없고 스스로 내려놓을 수만 있을 때 생기는 Deadlock조건이다.
방지방법으론 뺏을 수 있게 하면 된다. CPU나 Memory같은 경우는 Save & Restore 작업이 잘 돼있기 때문에 빼앗아도 문제가 안생기지만
그 외엔 뺏었다간 하던 작업이 엉망이 될 수 있다. 일부 자원만 이 방지 방법이 채택 가능하다.
Circular Wait Prevention
자원을 기다리는 프로세스들 간 사이클이 형성되면 발생하는 Deadlock조건.
근본적으로 사이클이 안 생기게 하면 방지가능하다. Cycle 생성방지를 위해 모든 자원 유형에 할당 순서를 매기고 순서대로 자원을 할당하게 하면 된다.
만약 5번 자원을 할당 받은 프로세스가 2번 자원이 필요하다면 5번 자원을 반납하고 2번부터 얻고 5번을 얻는, 차례대로 할당 받게 한다는 뜻이다.
Mutual exclusion Prevention
자원 공유를 가능하게 하면 해결 가능하다.
Deadlock Prevention 방법들은 Deadlock 을 원천 봉쇄하지만 아래 문제들이 발생한다.
- Utilization(이용률)
- Throughput(처리량)
- Starvation
잘 생기지도 않는 Deadlock 방지를 위해 사용하기는 비효율적이다.
Deadlock Avoidance (회피)
지원요청에 대한 부가적인 정보를 이용, Deadlock의 가능성이 없는 경우에만 자원을 할당시킨다
프로세스가 태어나서 죽을 때까지 사용할 자원을 미리 알고 있을 때 사용하는 방법이다.
Deadlock Avoidance 는 자원이 놀고 있더라도 Cycle발생 위험이 있다면 주지 않도록 하는방법이다.
Deadlock Avoidance 는 자원 개수가 Single Instance 이냐 Multiple Instances 이냐에 따라 방법이 나뉜다.
Resource Allocation Graph Algorithm (Single Instance)
위에서 보았던 자원할당 그래프에서 점선이 추가되었다.
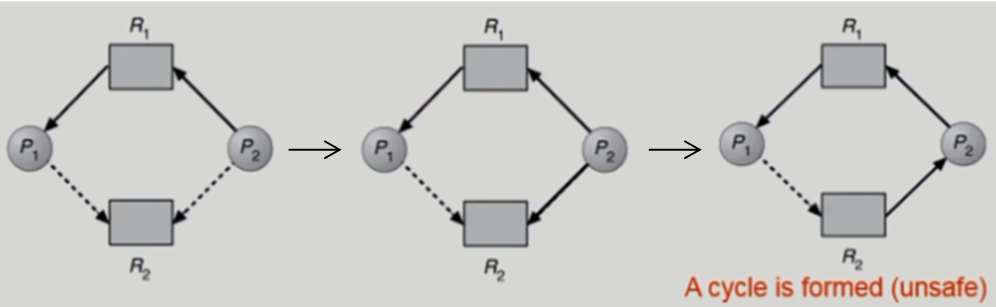
실선은 자원을 요청, 할당 되었다는 정보이고
점선은 자원 요청 방향만 있는데 미래에 요청할 가능성이 있다는 뜻이다.
실제 요청되면 실선으로 바뀐다.
점선을 포함해서 Cycle이 생길 위험이 있으면 자원할당을 해주지 않는다.
위 그림처럼 흘러간다면 Cycle이 생길 가능성이 높다.
따라서 중간 그림 단계에 왔을 때(P2가 R2를 요청했을 때) R2자원이 쓰여지지 않더라도 자원을 주면 안 된다.
P1이 R1자원을 내려놓으면 비로소 R2자원을 P2에게 줄 수 있다.
Single Instance의 경우 위와 같이 graph 기법만으로 해결 가능하다.
Banker’s Algorithm (Multiple Instances)
두 알고리즘 모두 프로세스가 평생에 사용할 자원의 개수를 알고 있는 전제하에 이루어진다.
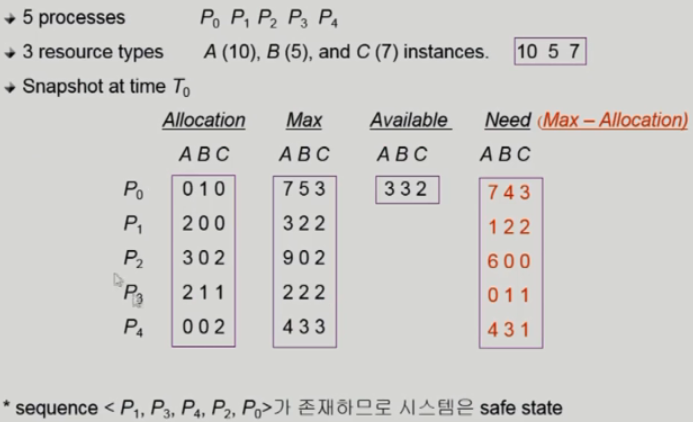
A, B, C 괄호안의 숫자는 Instance 개수.
Allocation 안의 숫자는 프로세스가 이미 가지고 있는 Instance 개수.
Available 안 숫자는 가용할 수 있는, 남아있는 자원 Instance 개수.
Max 안 숫자는 앞으로 사용할 최대 자원 개수.
Need 추가로 요청할 자원 개수(max – allocation).
만약 P0 가 C 1개를 요청한다면 비록 가용자원(Available)은 2개가 있지만 줄 수 없다.
P0 은 앞으로 A(7) B(4) C(3) 개를 더 요청할 것인데 이를 계속 요청하다 보면 가용자원은 동날 것이고 Deadlock 이 발생한다.
가용자원이 A(7) B(4) C(3) 만큼 있지 않는 이상 P0 의 요청은 계속 무시된다.
반면에 P1 이 Need 만큼 요청한다면 줄 수 있다.
이미 그이상의 가용자원이 있기 때문!
즉 Banker’s Algorithm 은 Available 이 Need 이상이라면 자원을 주지만
그 반대라면 자원이 있더라도 주지 않는다.
밑의 Sequence 는 프로세스에게 자원을 주는 순서이다.
P1 이 자원을 받고 나중에 종료 후 위의 프로세스 정렬 순서대로 실행하는 것이다.
Deadlock Avoidance 의 두 알고리즘은 모두 Safe state 에서 절대로 벗어나지 않기 위해 만들어졌다.
이 알고리즘은 Deadlock 회피를 위한 극단적인 예로 실제 시스템은 위처럼 동작하진 않는다.
현재 시스템은 프로세스가 앞으로 사용할 가용자원 이상이 생길 때 동안 기다리지 않고 먼저 가져다 썼다가 반납하고 추가로 더 쓰기도 한다. (물론 추가 알고리즘이 있어야 가능)
Deadlock Detection and recovery (탐지와 회복)
Deadlock 발생은 허용하되 그에 대한 Detection 루틴을 두어 Deadlock 발견 시 Recover 하는 방법이다.
Deadlock막겠다고 여유 있는 자원 안주면 비효율적이기 때문에 사용하는 방법.
Detection 방법도 Single Instance 에선 graph 방법을 사용하고 Multiple Instances 에선 table 방법을 사용한다.
Single Instance
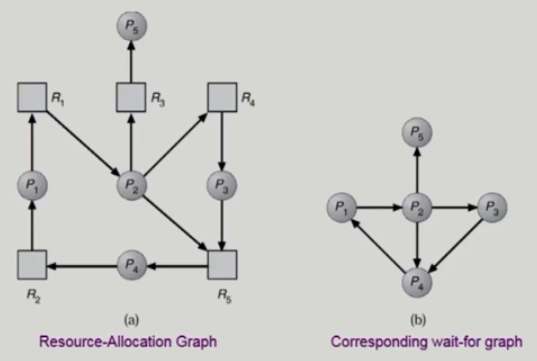
(a) 경우 Cycle이 2개 있다. Deadlock이 있는 상황이다.
(b) 는 (a) 에서 자원을 빼고 프로세스만 있는 그림이다.
P1이 P2의 자원을 기다리고 있는 상태를 쉽게 볼 수 있다.
사람도 한눈에 보고 감지하는데 컴퓨터는 당연히 더 복잡해도 탐지할 수 있다.
Multiple Instances
프로세스가 앞으로 사용할 Instance 가 몇 개인지 알 수 없다.
Instance 들은 모든 프로세스들에게 할당 돼있고 더 이상 남은자원이 없다.
Instance 를 요청한 프로세스들은 요청한 자원이 들어오기 전까지 자신의 자원을 내놓지 않는다.
프로세스들은 운 좋으면 Instance 를 내놓고 가용 Instance 를 만들어 줄 수 도 있고 아닐 수 도 있다.
내놓지 않는다면 Deadlock 이라 생각할 수 있지만
Deadlock Detection 은 매우 낙관적인 방법이기 때문에 에선 이정도는 Safe Sequence가 있다면 Deadlock이 아니라 본다.
Safe Sequence란 프로세스가 자원을 반납하는Sequence이다.
하지만 이 상황에서 모든 프로세스가 추가로 Instance 를 요청하면 하고 반납을 죽어도 안한다면 결국 Deadlock 으로 Detection 한다.
Detection방법을 알아봤으니 Recovery를 알아보자, 방법은 두 가지다
Process Termination (강제종료)
Deadlock 과 연루된 프로세스를 죽이는 방법
관련 프로세스를 모두 죽이는 방법과 관련 프로세스를 하나씩 죽여 가며 Deadlock cycle이 사라지는지 확인하는 방법이 있다.
Resource Preemption (자원 선점)
Deadlock과 관련된 프로세스를 골라서 자원을 빼앗는 방법.
자원 조금만 때가도 Deadlock이 풀리는, 비용을 최소화할 프로세스를 골라야한다.
특정 프로세스만 자원을 빼앗기는
Starvation문제가 발생할 수 있다.
빼앗는 자원(cost factor)의 회수(rollback)횟수를 같이 고려해서 같은 프로세스의 자원만 빼앗지 않도록 해야 한다.
Deadlock ignorance (무시)
Deadlock에 대해 시스템이 책임지지 않음
말 그대로 Deadlock이 일어나지 않는다고 생각하고 아무런 조치도 하지 않는다.
Deadlock이 드물게 일어나기 때문에 조치 자체가 오버헤드라 생각해서 사용하는 방법이다.
Deadlock이 발생하면 그냥 시스템 비정상 작동으로 보고 사람이 직접 프로세스를 강제종료 혹은 시스템을 강제종료 시키면 된다.
우리가 작업관리자로 강제종료 하거나 시스템 전원을 꺼버리듯이….
놀랍게도 현대 Unix, Windows 등 대부분의 OS가 이 방법을 사용한다.