모니터링 - Prometheus 메트릭!
개요
관측모니터링에서 시스템 기반 모니터링의 첫번째 관측 대상인 Metric 을 가장 효과적으로 다루는 오픈소스.
2012년 사운드클라우드의 몇 명의 개발자가 Go 언어로 아파치 2.0 라이선스를 기준으로 개발하였으며 2016년 CNCF 에 두번째로 합류했다(첫번째는 k8s)
수만은 프레임워크와 서드파티에서 Prometheus 라이브러리와 exporter 를 제공하고 label(key-value) 형태의 문자열로 메트릭을 게시한다.
모니터링 작업의 종류는 아래 4가지
- alerting
문제 발생 시기 파악 - debugging
문제 발생 원인 파악 - treding
문제 발생 컨텍스트 파악, 특정 시간에만 발생하는 문제를 파악하는 작업이 여기에 속함. - plumbing
모니터링 시스템을 또 다른 작업을 처리하기 위한 목적으로 사용, 이메일 전송같은 관리자 노티가 여기에 속함.
Prometheus 는 위 4가지를 작업을 효과적으로 수행할 수 있게 도와준다.
설정
프로메테우스의 설계원칙에선 설정 파일(prometheus.yml) 로는 런타임시 동작 과정을 설정하고, 명령줄 플래그 로는 시스템 레벨를 설정한다.
- prometheus.yml
- https://prometheus.io/docs/prometheus/latest/configuration/configuration/
- 주로 스크래핑 규칙, 알림 규칙, 경보 설정 등 런타임 동작과 관련된 설정
- 명령줄 플래그
- https://prometheus.io/docs/prometheus/latest/storage/#operational-aspects
- 데이터 저장소와 같은 시스템 레벨 설정을 관리
--storage.tsdb.retention.time(보존 기간)--storage.tsdb.retention.size(용량 제한)--storage.tsdb.path(데이터 저장 경로)--web.enable-lifecycle(HTTP 기반 재시작 지원)
services:
prometheus:
image: prom/prometheus:v3.1.0
volumes:
- "./path/to/prometheus.yml:/etc/prometheus/prometheus.yml"
- "./path/to/rules.yml:/etc/prometheus/rules.yml"
- "./volume/prometheus:/prometheus"
ports:
- '9090:9090'
command:
- "--config.file=/etc/prometheus/prometheus.yml" # command 지정시 yml 위치 지정해줘야함.
- "--storage.tsdb.retention.time=30d"
- "--storage.tsdb.retention.size=2GB"
- "--storage.tsdb.path=/prometheus"
기간이 완료되기 전에 용량이 초과될 경우 오래된 데이터를 삭제하여 용량제한을 유지한다.
데모코드
https://github.com/Kouzie/spring-boot-demo/tree/main/observability-demo
기본 config 파일
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
계측데이터
먼저 Prometheus 에 어떤 형식의 데이터가 계측데이터로 쌓이는지 알아야 한다.
계측라이브러리별로 사용하는 클래스명, 함수명이 다르지만 대부분 비슷하며, 여기선 java-micrometer 를 기준으로 설명한다.
// prometheus micrometer registry 등록
implementation "io.micrometer:micrometer-registry-prometheus"
메트릭 형식
# HELP jvm_gc_memory_promoted_bytes_total Count of positive increases in the size of the old generation memory pool before GC to after GC
# TYPE jvm_gc_memory_promoted_bytes_total counter
jvm_gc_memory_promoted_bytes_total{service_name="greeting",} 0.0
# 메트릭이름{레이블 key-value} 값 [time_stamp]
HELP 주석은 메트릭에 대한 설명, 수집할 때마다 변경되어서는 안됨, TYPE 주석은 [counter, gauge, summary, histogram, untyped] 중 하나의 값을 가진다.
주석 데이터는 Prometheus 의 연산에선 사용하지 않지만 Grafana 표시창에선 출력될 수 있다.
모든 문자열은 snake type 으로 구성되어야 하고, 아래와 같은 플랫폼과 타입에 해당하는 예약어를 메트릭이름이나 레이블 key 값으로 사용하지 않는것을 권장한다.
- go
- jvm
- sum
- count
- max
- mean
- total
Counter
계측할 데이터의 개수, 크기를 측정한다.
계측할 데이터가 얼마나 빠르게 증가하는지 추적한다.
private final MeterRegistry registry; // prometheus micrometer exporter
// Counter 설정
this.counter = Counter.builder("api.call.count")
.description("api call count")
.register(registry);
@GetMapping
public String greet() throws JsonProcessingException {
log.info("greet invoked");
registry.counter("api.call.count", "api.name", "greet").increment(1);
HelloJava helloJava = new HelloJava(greetingMessage, LocalDateTime.now());
return objectMapper.writeValueAsString(helloJava);
}
# HELP api_call_count_total
# TYPE api_call_count_total counter
api_call_count_total{api_name="greet",service_name="greeting",} 6.0
Gauge
계측 데이터의 현시점 상태에 대한 스냅샷을 측정한다.
아래와 같은 상태를 모니터링하는데 효과적
- CPU/Memory 사용량
- Pool 개수
계측할 데이터는 참조객체, 그리고 값을 반환할 일등함수를 매개변수로 넣어야한다.
private static AtomicLong result = new AtomicLong(0);
// Gauge 설정
this.gauge = Gauge.builder("result.sum", result, AtomicLong::get)
.description("result sum")
.register(registry);
@GetMapping("/{num1}/{num2}")
public String calculate(@PathVariable Long num1, @PathVariable Long num2) {
log.info("calculate invoked, num1:{}, num2:{}", num1, num2);
// 결과 값을 저장할 AtomicInteger 생성
result.set(num1 + num2);
return result.toString();
}
curl localhost:8080/greeting/3/4
# 7
# HELP result_sum result sum
# TYPE result_sum gauge
result_sum{service_name="greeting",} 7.0
Summary
계측한 데이터의 수(count), 평균값(mean), 최대값(max), 합계(sum) 통계값을 제공한다.
// summary
this.summary = DistributionSummary.builder("request.num.size")
.baseUnit("num")
.register(registry);
@GetMapping("/{num1}/{num2}")
public String calculate(@PathVariable Long num1, @PathVariable Long num2) {
log.info("calculate invoked, num1:{}, num2:{}", num1, num2);
summary.record(num1);
summary.record(num2);
return (num1 + num2).toString();
}
@GetMapping("/summary")
public String summary() {
String result = "";
result += "Total count: " + summary.count() + "\n";
result += "Total sum: " + summary.totalAmount() + "\n";
result += "Average: " + summary.mean() + "\n";
result += "Maximum: " + summary.max() + "\n";
return result;
}
curl localhost:8080/greeting/1/2
# 3
curl localhost:8080/greeting/3/4
# 7
curl localhost:8080/greeting/5/6
# 11
curl localhost:8080/greeting/summary
# Total count: 6
# Total sum: 21.0
# Average: 3.5
# Maximum: 6.0
# HELP request_num_size_num
# TYPE request_num_size_num summary
request_num_size_num_count{service_name="greeting",} 6.0
request_num_size_num_sum{service_name="greeting",} 21.0
# HELP request_num_size_num_max
# TYPE request_num_size_num_max gauge
request_num_size_num_max{service_name="greeting",} 6.0
Timers
이벤트 수행 시간을 측정. histogram 에 대한 내용을 출력, bucket 형태로 제공한다.
평균 시간, 최소/최대 시간, 카운트(작업 수), throughput 등의 정보를 제공.
// timer
this.timer = Timer
.builder("test.timer")
.publishPercentiles(0.3, 0.5, 0.95)
.publishPercentileHistogram()
.register(registry);
@GetMapping("/record")
public String record() {
timer.record(() -> {
try {
Thread.sleep(1000); // 1초 대기
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
// 작업 수행 후 Timer에서 정보 가져오기
String result = "";
result += "총 실행 횟수: " + timer.count() + "\n";
result += "평균 실행 시간(ms): " + timer.mean(TimeUnit.MILLISECONDS) + "\n";
result += "최대 실행 시간(ms): " + timer.max(TimeUnit.MILLISECONDS) + "\n";
result += "총 실행 시간(ms): " + timer.totalTime(TimeUnit.MILLISECONDS) + "\n";
return result;
}
curl localhost:8080/greeting/record
# 총 실행 횟수: 1
# 평균 실행 시간(ms): 1004.828625
# 최대 실행 시간(ms): 1004.828625
# 총 실행 시간(ms): 1004.828625
curl localhost:8080/greeting/record
# 총 실행 횟수: 2
# 평균 실행 시간(ms): 1004.7607295
# 최대 실행 시간(ms): 1004.828625
# 총 실행 시간(ms): 2009.521459
curl localhost:8080/greeting/record
# 총 실행 횟수: 3
# 평균 실행 시간(ms): 1003.3067086666666
# 최대 실행 시간(ms): 1004.828625
# 총 실행 시간(ms): 3009.920126
curl localhost:8080/greeting/record
# 총 실행 횟수: 4
# 평균 실행 시간(ms): 1003.74377125
# 최대 실행 시간(ms): 1005.054959
# 총 실행 시간(ms): 4014.975085
# HELP test_timer_seconds_max
# TYPE test_timer_seconds_max gauge
test_timer_seconds_max{service_name="greeting",} 1.005054959
# HELP test_timer_seconds
# TYPE test_timer_seconds histogram
test_timer_seconds{service_name="greeting",quantile="0.3",} 0.973078528
test_timer_seconds{service_name="greeting",quantile="0.5",} 0.973078528
test_timer_seconds{service_name="greeting",quantile="0.95",} 0.973078528
test_timer_seconds_bucket{service_name="greeting",le="0.001",} 0.0
test_timer_seconds_bucket{service_name="greeting",le="0.001048576",} 0.0
# ... 빈도수 측정을 누적 히스토그램
test_timer_seconds_bucket{service_name="greeting",le="0.984263336",} 0.0
test_timer_seconds_bucket{service_name="greeting",le="1.073741824",} 4.0
# ...
test_timer_seconds_bucket{service_name="greeting",le="30.0",} 4.0
test_timer_seconds_bucket{service_name="greeting",le="+Inf",} 4.0
test_timer_seconds_count{service_name="greeting",} 4.0
test_timer_seconds_sum{service_name="greeting",} 4.014975085
Prometheus 출력값을 보면 분위수 측정을 위한 quantile 부터 _bucket 으로 범위를 지정해 빈도수를 측정할 수 있다.
1초 sleep 임으로 1초를 기점으로 누적히스터그램에
4번 호출됨을 알수 있다.
꼭 Runnable 로 측정할 필요 없이 아래와 같이 실행시간에 대한 값만 입력해도 된다.
// 작업 시작 전 시간 측정
long startTime = System.nanoTime();
Thread.sleep(1000); // 측정할 이벤트
long endTime = System.nanoTime();
timer.record(endTime - startTime, TimeUnit.NANOSECONDS);
AOP 를 사용하면 간단한 어노테이션으로 함수별, 함수그룹 Timer 측정 가능.
레이블
레이블은 시계열과 연관된 key-value 쌍으로 데이터 식별자로 사용된다.
# HELP jvm_memory_committed_bytes The amount of memory in bytes that is committed for the Java virtual machine to use
# TYPE jvm_memory_committed_bytes gauge
jvm_memory_committed_bytes{area="heap",id="G1 Eden Space",service_name="greeting",} 6.291456E7
jvm_memory_committed_bytes{area="heap",id="G1 Old Gen",service_name="greeting",} 4.194304E7
jvm_memory_committed_bytes{area="nonheap",id="CodeCache",service_name="greeting",} 1.0289152E7
jvm_memory_committed_bytes{area="nonheap",id="Metaspace",service_name="greeting",} 5.6623104E7
jvm_memory_committed_bytes{area="heap",id="G1 Survivor Space",service_name="greeting",} 8388608.0
jvm_memory_committed_bytes{area="nonheap",id="Compressed Class Space",service_name="greeting",} 7798784.0
위와 같이 메트릭이름이 동일하더라도 레이블을 통해 PromQL 를 통해 다양한 집계연산이 가능하다.
레이블을 설정시 중복의미를 피해야한다. PromQL 를 사용해 대부분 집계연산이 가능하기에 중복의미의 값이 Prometheus 에 저장되는것을 피해야한다.
some_metric{label="foo"} 7
some_metric{label="bar"} 13
some_metric{label="total"} 20
위와같이 label=total 은 foo, bar 의 합계로도 구할수 있음으로 중복의미라 할 수 있다.
레이블 개수(카디널리티)가 많아질수록 카타시안곱만큼 데이터가 생성되기 때문에 Prometheus 저장공간에 부담이 될 수 있다.
레이블 개수가 적다 하더라도 분포가 넓은 값(IP, 사용자명 등)을 레이블로 설정하면 안된다.
만약 카디널리티를 수십개씩 설정해야 하는 상황이라면 Prometheus 메트릭을 사용하기 보단 로그를 통해 모니터링하는 것을 권장한다.
Scraping 설정
pull base 로 동작하는 Prometheus 에선 어떤 서비스에서 메트릭을 스크래핑 해올지 알고 있어야 한다.
수동으로 아래와 같이 설정할 수 있다.
scrape_configs:
# static 등록
- job_name: Prometheus
static_configs:
- targets:
- localhost:9090
# 파일기반 등록
- job_name: file
file_sd_configs:
- files:
- "*.json"
// filesd.json
[
{
"targets": ["host1:9100", "host2:9100"],
"lables": {
"team": "infra",
"job": "node"
}
},
{
"targets": ["host1:9090"],
"lables": {
"team": "monitoring",
"job": "prometheus"
}
}
]
Service Discovery
클라우드 환경에서는 서비스 인스턴스가 동적으로 생성/삭제되고, IP 주소나 호스트명이 자주 변경된다.
이런 환경에서 static_configs로 수동 등록하는 것은 불가능하며, Service Discovery를 통해 자동으로 타겟을 발견하고 스크랩해야 한다.
- Prometheus가 주기적으로 Service Discovery API를 호출하여 타겟 목록을 가져옴
- 발견된 타겟에 대해
discovered labels(메타데이터) 자동 생성 relabel_configs를 통해 필요한 타겟만 필터링하고 라벨 조정- 변경사항이 있으면 자동으로 타겟 목록 업데이트
k8s 환경에선 kubernetes_sd_configs(Kubernetes Service Discovery) 를 지원하며 다른 클라우드 서비스에서도 각종 Service Discovery 기능을 제공한다.
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
namespaces:
names:
- default
- production
relabel_configs:
# prometheus.io/scrape: "true" 어노테이션이 있는 Pod만 스크랩
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
# metrics_path 설정
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
# 포트 설정
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
Role 종류
role: node: 각 노드의 kubelet을 모니터링role: pod: 모든 Pod를 모니터링 (가장 많이 사용)role: service: Service 엔드포인트를 모니터링role: endpoints: Service의 엔드포인트를 모니터링role: ingress: Ingress 리소스를 모니터링
Pod 어노테이션을 통한 자동 스크랩
Pod에 다음 어노테이션을 추가하면 자동으로 스크랩 대상에 포함된다:
apiVersion: v1
kind: Pod
metadata:
annotations:
prometheus.io/scrape: "true" # 스크랩 여부
prometheus.io/port: "8080" # 메트릭 포트
prometheus.io/path: "/actuator/prometheus" # 메트릭 경로
spec:
containers:
- name: app
ports:
- containerPort: 8080
예제: Spring Boot 애플리케이션 스크랩
scrape_configs:
- job_name: 'kubernetes-springboot'
kubernetes_sd_configs:
- role: pod
relabel_configs:
# prometheus.io/scrape 어노테이션이 true인 Pod만 선택
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
# 메트릭 경로 설정
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
# 포트 설정
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
# 라벨 추가
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
Prometheus Operator 의 ServiceMonitor
Kubernetes 환경에서 Prometheus Operator를 사용하는 경우, ServiceMonitor CRD를 통해 더 쉽게 관리할 수 있다.
ServiceMonitor 예제
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: springboot-app
namespace: production
labels:
app: springboot-app
spec:
selector:
matchLabels:
app: springboot-app
endpoints:
- port: http
path: /actuator/prometheus
interval: 30s
scrapeTimeout: 10s
namespaceSelector:
matchNames:
- production
- staging
PodMonitor 예제
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: springboot-pods
spec:
selector:
matchLabels:
app: springboot-app
podMetricsEndpoints:
- port: http
path: /actuator/prometheus
interval: 30s
장점
- Kubernetes 네이티브 방식으로 관리
- GitOps와 잘 통합됨
- 자동으로 relabeling 처리
- 네임스페이스별로 분리 관리 가능
동적 환경에서의 Best Practices
- Relabeling을 통한 필터링
- 필요한 타겟만 선택하여 불필요한 스크랩 방지
- 라벨을 통한 메트릭 카디널리티 관리
- 적절한 스크랩 간격 설정
- 동적 환경에서는
scrape_interval을 짧게 설정 (15s~30s) - 타겟이 많을 경우 부하 고려
- 동적 환경에서는
- 타임아웃 설정
scrape_timeout을 적절히 설정하여 느린 타겟으로 인한 블로킹 방지
- 라벨 관리
relabel_configs를 통해 일관된 라벨 구조 유지- 카디널리티가 높은 라벨(IP, 사용자ID 등) 사용 지양
- 모니터링 대상 선정
- Pod 어노테이션이나 라벨을 통한 명시적 선정
- 모든 리소스를 스크랩하지 않고 필요한 것만 선택
예제: 종합 설정
scrape_configs:
- job_name: 'kubernetes-apps'
kubernetes_sd_configs:
- role: pod
namespaces:
names:
- production
- staging
scrape_interval: 30s
scrape_timeout: 10s
relabel_configs:
# prometheus.io/scrape 어노테이션이 있는 Pod만 선택
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
# 메트릭 경로 설정
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
# 포트 설정
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
# Pod 라벨을 메트릭 라벨로 추가
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
# 네임스페이스와 Pod 이름 추가
- source_labels: [__meta_kubernetes_namespace]
target_label: namespace
- source_labels: [__meta_kubernetes_pod_name]
target_label: pod
# 불필요한 라벨 제거
- action: labeldrop
regex: '__meta_kubernetes_pod_.*'
타겟 라벨(traget labels)
traget labels 은 모든 메트릭에 기본적으로 추가되는 식별자 레이블 이라 할 수 있다.
traget labels 은 모든 메트릭의 레이블에 추가된다.
Spring Boot Actuator + micrometer prometheus 를 기반으로 메트릭을 설정하여 수집하면 아래와 같은 그림을 볼 수 있다.
scrape_configs:
- job_name: "actuator"
scrape_interval: 1s # 1초 간격으로 스크래핑, default 1m
metrics_path: '/actuator/prometheus'
static_configs:
- targets:
- '192.168.10.66:9404'
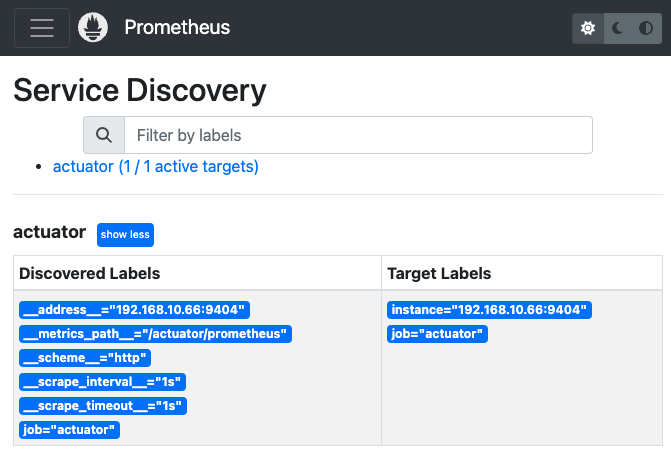
Service Discovery 서비스에서 discovered lables, target lables 를 확인가능하다.
discovered lables는 모든 서비스가 가지는 메타데이터 레이블이라 할 수 있다.
relabel_configs
https://grafana.com/blog/2022/03/21/how-relabeling-in-prometheus-works/
relabel_configs 는 스크래핑 작업을 수행하기 전에 알고 있는 정보를 기준으로 작업을 진행하기 때문에,
위의 내장라벨로 불리우는 discovered lables, target lables 를 사용해서 여러 작업을 수행한다.
relabel_configs 의 하위속성으로 아래와 같은 설정이 가능하다.
source_labelsseparator (default = ;)target_labelregex (default = (.*))replacement (default = $1)action (default = replace)modulus
action 의 default 값은 replace 이고 아래와 같은 값을 할당할 수 있다.
- action: replace:
target label의 추가. - action: keep:
target label이regex에 매칭될 경우 스크래핑 함. - action: drop:
target label이regex에 매칭될 경우 스크래핑 하지 않음. - action: labelkeep:
regex에 매칭되는target label유지, 그외 모두 제거. - action: labeldrop:
regex에 매칭되는target label제거. - action: labelmap:
regex에 매칭되는target label부분을replacement값으로 변경해새로운target label생성. - action: hashmod:
target label값들을 해시연산,modulus로 나눈 나머지를target label로 설정. 대규모 클러스터에서 분산수집시 사용.
action: replace 를 사용해 target lable 추가 작업이 가능하다.
scrape_configs:
- job_name: "actuator"
scrape_interval: 1s # 1초 간격으로 스크래핑, default 1m
metrics_path: '/actuator/prometheus'
static_configs:
- targets:
- '192.168.10.66:9404'
relabel_configs:
- action: replace # 생략 가능, deploy=dev 추가
target_label: deploy
replacement: dev
- action: replace # 생략 가능, address_job={__address__};{job} 추가
source_labels: [__address__, job]
target_label: address_job
- action: replace # 생략 가능, replaced_address_job={__address__}_{job} 추가
source_labels: [__address__, 'job']
separator: '_'
regex: '(.*)_(.*)'
target_label: replaced_address_job
replacement: '${1}_${2}'
총 3개의 target_lable 을 추가하였고 아래와 같이 추가된 target label 확인이 가능하다.
instance="192.168.10.66:9404"
job="actuator"
deploy="dev"
address_job="192.168.10.66:9404;actuator"
replaced_address_job="192.168.10.66:9404_actuator"
이 외에도 action 속성을 사용해 target label 관련 여러가지 작업 수행이 가능하다.
PromQL
백터 선택기
백터 선택기 는 PromQL 로 메트릭을 조회할 때 사용하는 쿼리 조회기라 할 수 있다,
각종 검색 조건을 설정할 수 있고, 출력하려는 데이터(벡터) 형태에 따라 2가지로 나뉜다.
인스턴트 벡터 선택기범위 벡터 선택기
# 인스턴트 벡터 선택기
jvm_threads_states_threads{service_name='greeting', state='runnable'}
# 범위 벡터 선택기
jvm_threads_states_threads{service_name='greeting', state='runnable'}[5m]
백터 선택기 내부에서 사용되는 연산자를 matcher 라 부르며 아래 4가지가 연산이 가능하다.
=:동등 matcher, 레이블이 없음을 표기하기 위해선foo=""를 사용.!=:부정 동등 matcher=~:정규 표현식 matcher,jon=~"n.*"!~:부정 정규 표현식 matcher
node_filesystem_size_bytes {
job="node-exporter",
mountpoint=~"/run/.*",
mountpoint!~"/run/user/.*"
}
백터 선택기 와 offset 을 같이 사용할 수 있는데, 1h 전 부터 메트릭을 조회하려면 아래처럼 offset 을 설정.
jvm_memory_used_bytes{id=~"Eden.*", service_name="greeting"} offset 1h
인스턴트 벡터
인스턴트 벡터는 특정 시점에서의 메트릭 값들의 집합이다.
PromQL 을 사용하여 데이터를 조회하거나 연산할 때 기본적으로 다루어지는 데이터 형식이다.
인스턴트 벡터 선택기를 통해 조회된다.
만약 메트릭이 과거에는 수집되었었지만 현재는 더이상 수집되지 않고 멈춰있다면, 쿼리조회 결과로 동일한 값들을 인스턴트 벡터로 출력시킬 것이다.
따라서 더이상 수집되지 않는 메트릭은 스테일 마커(stale marker) 를 사용해 인스턴트 벡터로 취급하지 않으며 쿼리조회 결과에서 제외시키는 과정을 수행한다.
stalenesss 과정이라 부름.
스테일 마커 의 처리는 내부 로직에 의해 자동으로 이루어지며, 데이터베이스에서 자동으로 제거해 리소스를 확보한다.
# 인스턴트 벡터 조회
jvm_threads_states_threads{service_name='greeting'}
# 조회 결과, 수집된 인스턴트 벡터
jvm_threads_states_threads{service_name="greeting",state="runnable"} 12.0
jvm_threads_states_threads{service_name="greeting",state="terminated"} 0.0
jvm_threads_states_threads{service_name="greeting",state="new"} 0.0
jvm_threads_states_threads{service_name="greeting",state="blocked"} 0.0
jvm_threads_states_threads{service_name="greeting",state="waiting"} 23.0
jvm_threads_states_threads{service_name="greeting",state="timed-waiting"} 15.0
범위 벡터
Gauge 형태의 데이터를 최신 한건 보여줄 때에나 인스턴트 백터 를 사용하고,
그래프 형태의 데이터를 출력할 땐 범위로 메트릭을 조회한다.
# 범위 벡터 조회
process_cpu_usage{service_name="greeting"}[5m]
# 조회 결과, 5분 동안의 범위 벡터
process_cpu_usage{service_name="greeting"}
0.0015325453023316401 @1711339473.398 # 1분 단위로 5개 반환
0.0013616055598816446 @1711339533.398
0.0015336334332262665 @1711339593.398
0.0015323496027067837 @1711339653.398
0.0013628039691665603 @1711339713.398
대시보드에서 graph탭을 누르면 각 시간대별로 메트릭값을 볼 수 있도록 범위 조회를 진행한다. 아래와 같이 범위 벡터 를 검색해서 출력해준다.
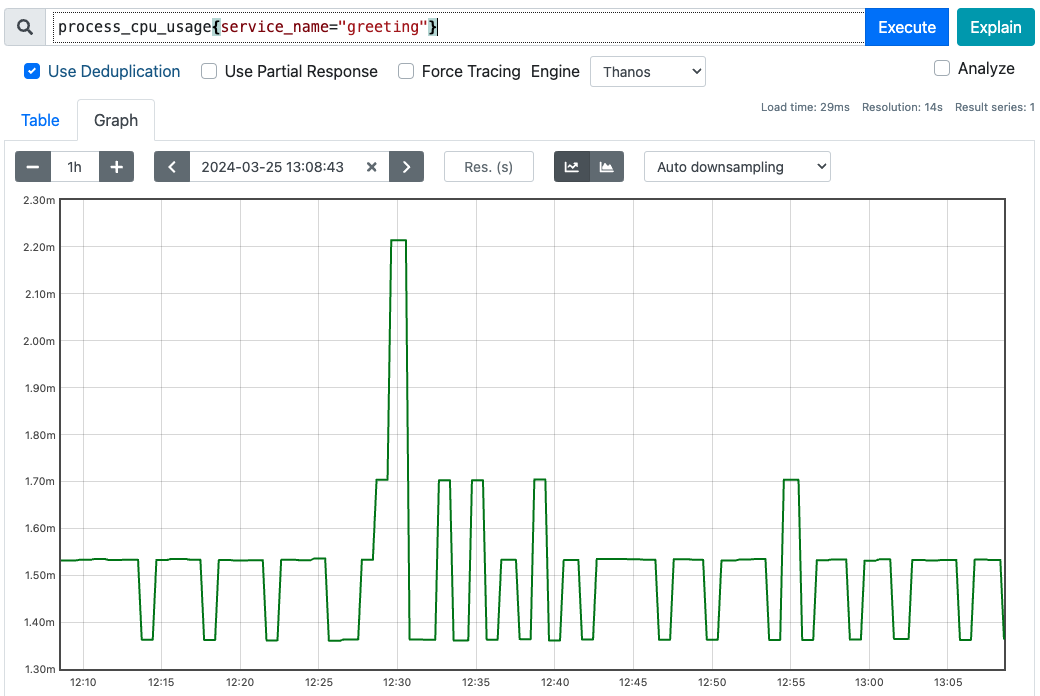
rate, avg_over_time 등, 함수가 범위벡터를 파라미터로 요구할 수 있다.
Counter 메트릭를 범위벡터로 rate 함수에 전달하면 아래와 같이 그래프로 표기해준다.
집계연산자
PromQL 에서 제공하는 집계연산으로 [sum, avg, max, min, count] 등이 있다.
집계연산은 상태를 측정하는
Gauge메트릭을 측정할 때 주로 사용한다.
집계연산은 항상 그룹화를 거쳐야 한다. 그룹화를 위한 함수는 아래 2개
by: 해당 속성을 기준으로 그룹화whitout: 해당 속성을 제외하여 그룹화
아래와 같이 2개의 Spring Boot actutator 서버에서 메트릭을 뽑아냈을 때,
# HELP jvm_threads_states_threads The current number of threads
# TYPE jvm_threads_states_threads gauge
jvm_threads_states_threads{service_name="greeting",state="runnable"} 12.0
jvm_threads_states_threads{service_name="greeting",state="terminated"} 0.0
jvm_threads_states_threads{service_name="greeting",state="new"} 0.0
jvm_threads_states_threads{service_name="greeting",state="blocked"} 0.0
jvm_threads_states_threads{service_name="greeting",state="waiting"} 23.0
jvm_threads_states_threads{service_name="greeting",state="timed-waiting"} 15.0
# HELP jvm_threads_states_threads The current number of threads
# TYPE jvm_threads_states_threads gauge
jvm_threads_states_threads{service_name="calculating", state="blocked"} 0.0
jvm_threads_states_threads{service_name="calculating", state="new"} 0.0
jvm_threads_states_threads{service_name="calculating", state="runnable"} 11.0
jvm_threads_states_threads{service_name="calculating", state="terminated"} 0.0
jvm_threads_states_threads{service_name="calculating", state="timed-waiting"} 13.0
jvm_threads_states_threads{service_name="calculating", state="waiting"} 28.0
같은 이름을 가진 여러개의 메트릭이 있을경우, 개별 그래프로 출력시킬 수 있고 그룹화하여 출력시킬 수도 있다.
by 그룹화 연산자를 사용해 sum 집계연산을 진행.
# service_name 레이블 기준으로 집계
sum by(service_name)(jvm_threads_states_threads)
# 조회 결과
# 현 시점에는 각 서비스별로 52, 46 개의 스레드가 동작중이라 할 수 있다.
{service_name="calculating"} 52
{service_name="greeting"} 46
jvm_threads_states_threads의 경우 속성이 2개밖에 없기 때문에by(service_name)은whitout(state)와 동일하다.
이 외에도 topk, bottomk, quantile, count_values 등의 집계연산자가 존재한다.
topk, bottomk 은 각각 상위, 하위 N개 메트릭을 반환하는 함수
# 상위 2개에 대한 메트릭, state 를 제외하고 그룹화
topk without(state)(2, jvm_threads_states_threads)
# 조회 결과, 각 서비스별 상위 2개씩 반환
jvm_threads_states_threads{service_name="calculating", state="waiting"} 28
jvm_threads_states_threads{service_name="calculating", state="timed-waiting"} 13
jvm_threads_states_threads{service_name="greeting", state="waiting"} 23
jvm_threads_states_threads{service_name="greeting", state="timed-waiting"} 13
# 하위 2개에 대한 메트릭, state 를 제외하고 그룹화
bottomk without(state)(2, jvm_threads_states_threads)
# 조회 결과, 각 서비스별 하위 2개씩 반환
jvm_threads_states_threads{service_name="calculating", state="blocked"} 0
jvm_threads_states_threads{service_name="calculating", state="new"} 0
jvm_threads_states_threads{service_name="greeting", state="blocked"} 0
jvm_threads_states_threads{service_name="greeting", state="new"} 0
quantile 은 분위수를 측정하여 반환하는 함수
# 0.5 분위수 반환, 평군과 동일
quantile without(device) (0.5, node_network_receive_bytes_total)
{job="node-exporter", namespace="prometheus", } 129942234
# 0.25 분위수 반환
quantile without(device) (0.5, node_network_receive_bytes_total)
{job="node-exporter", namespace="prometheus", } 28138173
count_values 는 그룹화된 메트릭의 결과값을 기준으로 카운팅한 값을 반환하는 함수
아래와 같은 version 을 출력하는 메트릭이 존재할 때
# envoy data-plane 의 버전들 출력
envoy_server_version
envoy_server_version{instance="172.28.10.135:15090", job="envoy-stats"} 3203603
envoy_server_version{instance="172.28.10.138:15090", job="envoy-stats"} 3203603
envoy_server_version{instance="172.28.10.142:15090", job="envoy-stats"} 3203603
envoy_server_version{instance="172.28.10.147:15090", job="envoy-stats"} 3203603
envoy_server_version{instance="172.28.10.154:15090", job="envoy-stats"} 3203603
envoy_server_version{instance="172.28.10.155:15090", job="envoy-stats"} 3203603
envoy_server_version{instance="172.28.10.157:15090", job="envoy-stats"} 3203603
envoy_server_version{instance="172.28.10.171:15090", job="envoy-stats"} 3203603
envoy_server_version{instance="172.28.10.175:15090", job="envoy-stats"} 3203603
envoy_server_version{instance="172.28.10.182:15090", job="envoy-stats"} 3203603
envoy_server_version{instance="172.28.10.195:15090", job="envoy-stats"} 3203603
envoy_server_version{instance="172.28.10.196:15090", job="envoy-stats"} 3203603
envoy_server_version{instance="172.28.10.197:15090", job="envoy-stats"} 3203603
version 별로 카운팅을 하고 싶다면 아래와 같이 count_values 를 사용.
# 출력된 value 기준으로 카운팅, 속성명은 my_envoy_version 으로
count_values without(instance)("my_envoy_version", envoy_server_version)
# 카운트 결과
{job="envoy-stats", my_envoy_version="3203603"} 13
# 총 몆종류의 my_envoy_version 이 있는지 확인
count without(my_envoy_version) (
count_values without(instance)("my_envoy_version", envoy_server_version)
)
{job="envoy-stats"} 1
산술연산자
지금까지는 프로메테우스의 반환값은 모두 vector 형태였다.
산술연산(사칙연산)을 수행시 scalar 형태의 데이터를 사용하고, PromQL 에서 제공하는 각종 함수 파라미터로 요구하는 경우가 많다.
- vector()
scalar to vector - scalar()
vector to scalar
vector(0)
# {} 0
scalar(vector(1))
# scalar 1
vector 데이터는 아래와 같이 or 연산자와 함께 값이 없을경우 0 을 반환하도록 사용한다.
sum(not_exist_guage) or vector(0)
# {} 0
vector 와 scalar 모두 산술연산과 비교연산을 지원한다.
+덧셈-뺄셈*곱셈/나눗셈%모듈러연산^지수연산==같다!=같지 않다>보다 크다<보다 작다>=보다 크거나 같다<=보다 작거나 같다.
scalar(vector(1)) * 4
# scalar 4
process_resident_memory_bytes / 1024
(process_resident_memory_bytes / 1000) > 1048 * 4
# 4GB 이상 벡터 필터링
Counter 관련 함수
- rate
- irate
- increase
세 함수 모두 증감율을 측정할 수 있는 PromQL 함수, 계속 증가하는 Counter 메트릭을 측정할 때 주로 사용한다.
# k8s node 의 receive bytes 측정
rate(node_network_receive_bytes_total[1m])
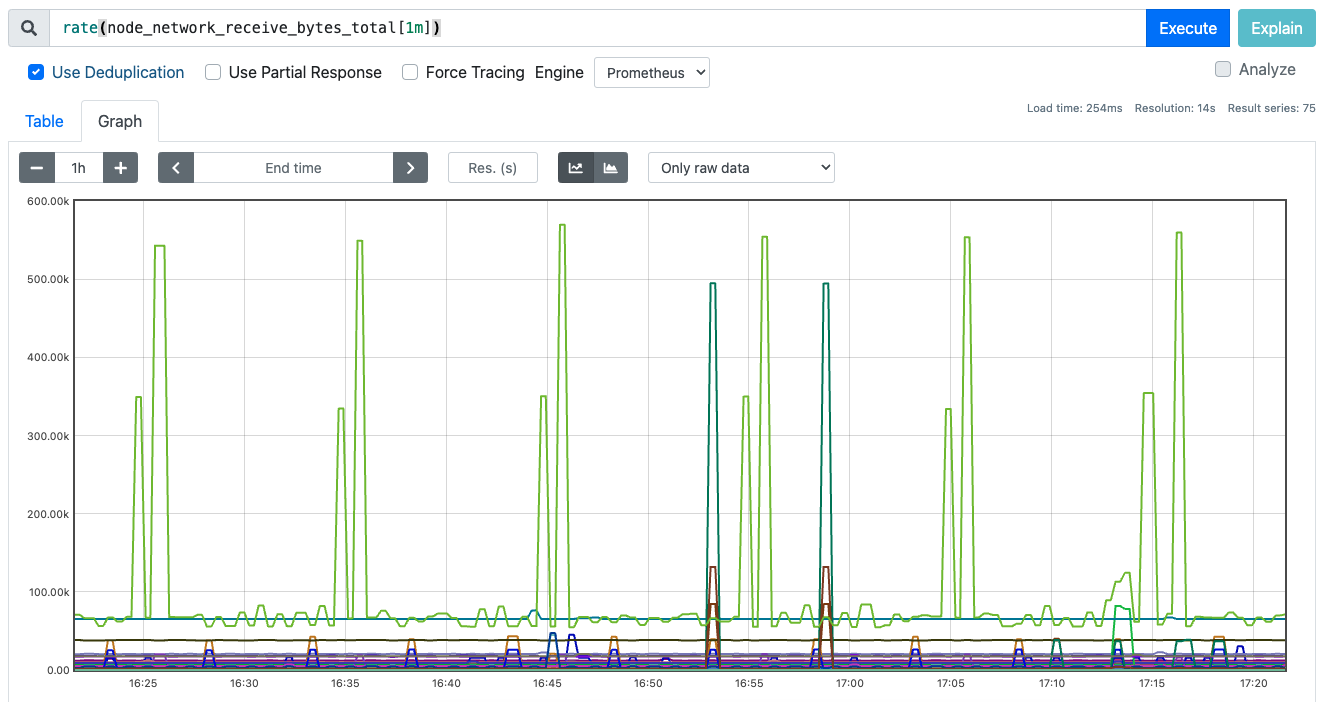
# k8s node 의 receive bytes 측정 후 모드 합하기
sum without(device)(rate(node_network_receive_bytes_total[1m]))
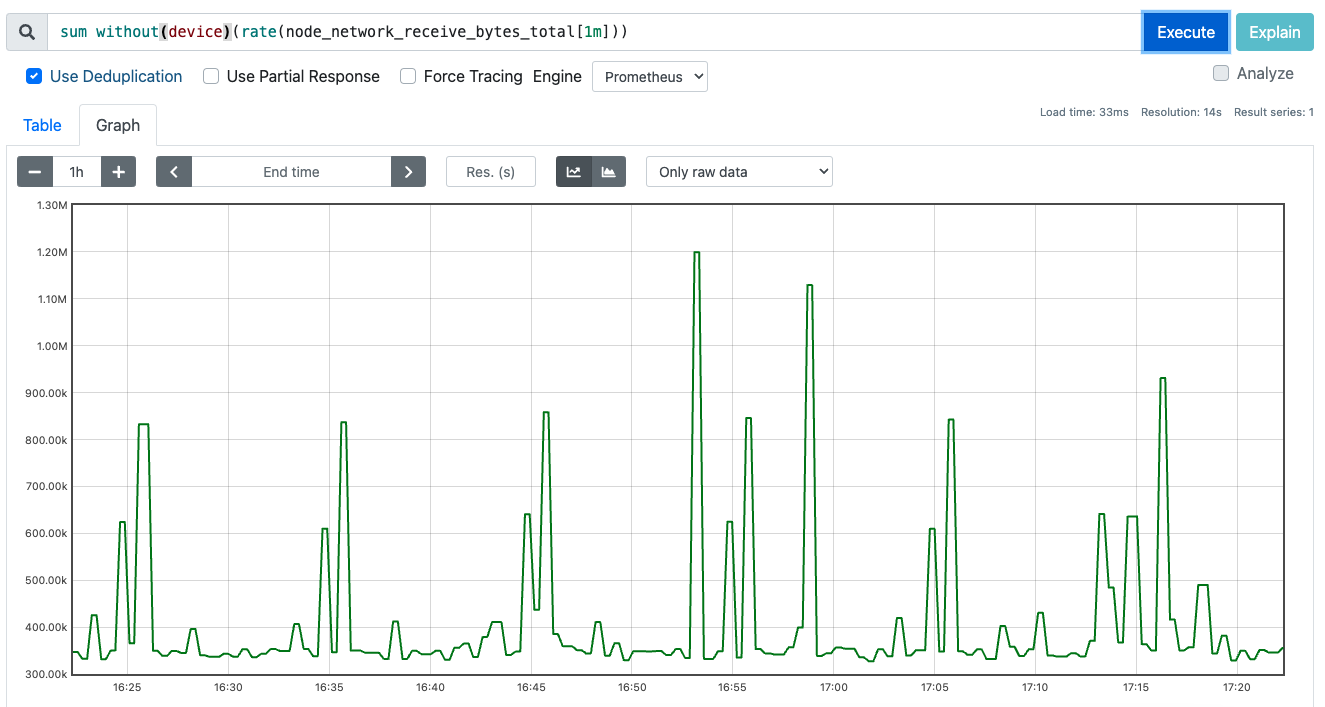
increase 는 rate 의 편의문법으로 rate 결과에 곱하기 300 한것과 동일하다.
irate 는 범위벡터로 출력된 모든값을 사용하지 않고 두 샘플만 사용한다.
Gauge 관련 함수
- changes
- deriv
- predict_linear
- delta
- idelta
- holt_winters
시간함수
- time
- year
- month
- days_in_month
- days_of_month
- days_of_week
- hour
- minute
time 함수만 유일하게 scalar 형태의 데이터를 반환한다.
time()
# scalar 1711428748
year(vector(1711428748))
# {} 2024
수학함수
제공되는 모든 수학함수의 반환값은 vector 형태이다.
입력 파라미터로는 scalar 형태를 요구한다.
- abs
- sqrt
- ln
- log2
- log10
- exp
- ceil
- floor
- round
- clamp_min
- clamp_max
벡터 매칭
두 메트릭의 결과 벡터의 레이블이 정확히 동일하여 1:1 매핑 가능하다면 산술연산이 가능하다.
process_open_fds / process_max_fds
결과 벡터의 레이블이 정확히 동일하지 않더라도 일부 레이블을 무시하고 매칭시킬 수 있다.
# 조회 및 결과
sum without(cpu)(rate(node_cpu_seconds_total{mode="idle"}[5m]))
{job="node-exporter", mode="idle", } 10.27699999999669
# 조회 및 결과
sum without(mode, cpu)(rate(node_cpu_seconds_total[5m]))
{job="node-exporter"} 11.743407407403625
위의 두 집계연산자의 결과 밑의 벡터는 mode 레이블 이 존재하지 않아 서로 일치하지 않지만 mode 레이블 를 제외시켜 매칭시킬 수 있도록 한다.
우측에 일부 레이블이 존재하지 않더라도 ignoring 을 통해 맞지 않는 레이블은 제거하고 매칭시킨다.
sum without(cpu)(rate(node_cpu_seconds_total{mode="idle"}[5m]))
/ ignoring(mode)
sum without(mode, cpu)(rate(node_cpu_seconds_total[5m]))
{job="node-exporter", service="prometheus-prometheus-node-exporter"}
0.8699777650560057
반대로 특정 레이블만 가지고 매칭시키려면 on 을 사용한다.
우측에 해당 레이블이 존재만 한다면 매칭시킨다.
sum without(cpu)(rate(node_cpu_seconds_total{mode="idle"}[5m]))
/ on(cpu)
sum(rate(node_cpu_seconds_total[5m]))
ignoring, on 모두 좌측과 우측에서 출력된 결과 벡터의 개수가 동일해야 매칭된다.
좌측에선 N건, 우측에선 M건 검색될 경우 매칭되지 않는데 이를 위해 두개의 결과 벡터를 조인처리해줄 함수를 사용한다.
sum without(cpu)(rate(node_cpu_seconds_total[5m])) # 검색결과 N건
/ ignoring(mode) group_left
sum without(mode, cpu)(rate(node_cpu_seconds_total[5m])) # 검색셜과 1건
node_hwmon_temp_celsius # 검색결과 N건
* ignoring(label) group_left(label)
node_hwmon_sensor_label # 검색결과 M건, N != M
우측 피연산자 결과 벡터의 개수가 1개라면, 좌측 피연사자의 모든 결과 벡터에 적용시킬 수 있다.
좌측 N, 우측 M, 그리고 N != M 관계일경우 일부 N 의 경우 매칭되는 벡터가 없을것이다.
그땐 좌측의 일부 결과 벡터를 버리고 매칭되는 벡터끼리 연산한 것만 출력한다.
논리연산자 백터 매칭
2개의 결과 벡터를 매칭하는 방법, 아래 논리연산자를 통해 벡터 매칭이 가능.
orandunlsess
# label ignoring 하고 매핑, or 연산자로 레이블이 일치하지 않아도 그냥 출력
node_hwmon_sensor_label
or ignoring(label)
node_hwmon_temp_celsius
# 조회결과 or 로 인해 마지막에 node_hwmon_temp_celsius 가 출력됨
node_hwmon_sensor_label{label="Core 0", namespace="prometheus",sensor="temp2"} 1
node_hwmon_sensor_label{label="Core 1", namespace="prometheus",sensor="temp3"} 1
node_hwmon_sensor_label{label="Core 2", namespace="prometheus",sensor="temp4"} 1
node_hwmon_sensor_label{label="Core 3", namespace="prometheus",sensor="temp5"} 1
node_hwmon_sensor_label{label="Core 4", namespace="prometheus",sensor="temp6"} 1
node_hwmon_sensor_label{label="Core 5", namespace="prometheus",sensor="temp7"} 1
node_hwmon_sensor_label{label="Package id 0", namespace="prometheus",sensor="temp1"} 1
node_hwmon_temp_celsius{sensor="temp1", }
rule files
docker run -d \
--name p8s-demo \
-p 9090:9090 \
-v ./path/to/prometheus.yml:/etc/prometheus/prometheus.yml \
-v ./path/to/rules.yml:/etc/prometheus/rules.yml \
prom/prometheus
규칙을 정의하는 rule file(규칙파일) 을 정의한다.
# prometheus.yml
global:
...
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules.yml"
rule file 에 정의된 내용은 evaluation_interval 마다 실행된다.
record rule
Prometheus 에서 계산한 값들로 대시보드를 구성할 때, record rule 을 사용하면 대량의 메트릭을 먼저 계산해놓고 가져와 사용할 수 있다.
# rules.yml
groups:
- name: spring_boot_rules
rules:
- record: instance:http_server_requests_seconds:avg_rate5m
expr: rate(http_server_requests_seconds_sum{outcome="SUCCESS", job="actuator"}[5m]) / rate(http_server_requests_seconds_count{outcome="SUCCESS", job="actuator"}[5m])
labels:
job: actuator
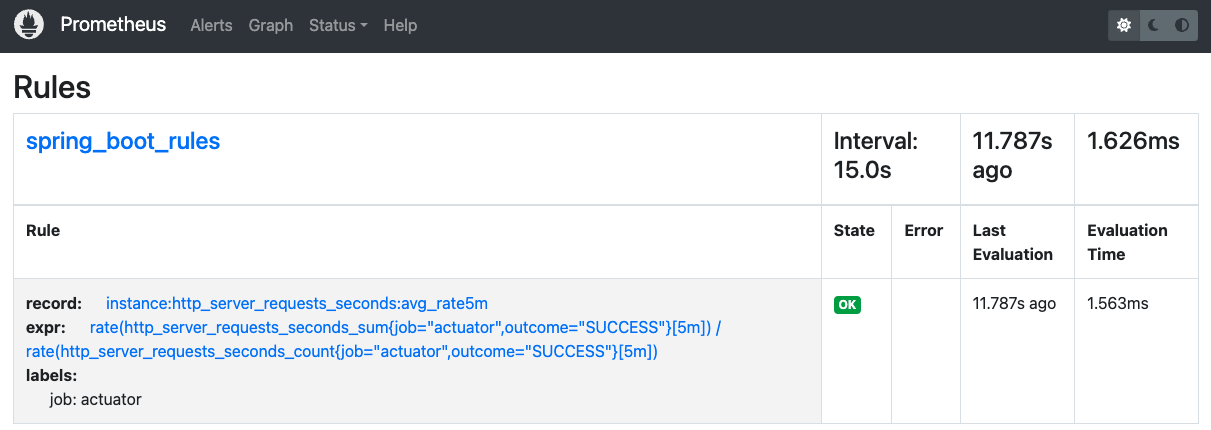
그림과 같이 Rule 목록에 해당 record rule 이 추가되었음을 알 수 있고
record rule 이름을 기반으로 검색도 가능하기 때문에 중간에 record rule 을 검색하여 메트릭의 카디널리티를 줄일 수 있다.
record rule 을 이름이 기존 record rule 이나 메트릭 이름과 중복되면 안된다.
또한 과도한 record rule 생성은 성능을 저하시킨다.
record rule 명명 규칙으로 콜론으로 [레이블, 메트릭명, 연산] 을 구분짖는다.
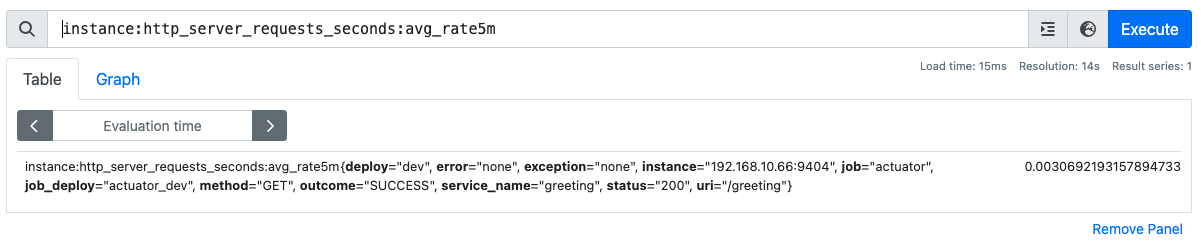
instance:http_server_requests_seconds:avg_rate5m
일부 회사에선 팀의 이름을 메트릭 이름으로 사용하는 경우가 있음.
alert rule
모니터링에서 alert 가 발생했을경우 AlertManager 는 해당 alert 을 받아 이메일,채팅 등으로 전달한다.
groups:
- name: alert_rules
rules:
- record: job:http_request_count:rate1m
expr: rate(http_server_requests_seconds_count[1m])
- alert: AbnormalHttpRequestCount
expr: job:http_request_count:rate1m * 60 > 60 # 분당 호출횟수 60 이상
for: 10s # pending 기간
labels:
severity: page # 심각도
team: devops # 팀명
annotations: # 전달할 메세지
summary: '호출횟수 비정상'
description: >
호출횟수 비정상 알림, 호출 횟수:{{ printf "%.2f" $value }}, 인스턴스 체크 필 {{ .Labels.instance }}
메트릭 값이 조건에 부합하고, for 옵션에 작성한 기간동안 유지될 경우 alert 을 발생시키고(fire), 다시 값이 원상복구 되면 alert 를 없앤다(resolve).
alert rule 에서는 보통 레이블을 사용해 alert 의 심각도와 전달할 팀명을 추가한다. annotations 을 사용해 전달할 내용을 추가할 수 있다.
for기간동안 유지되는alert는pending상태로 대기함.
alert 의 label 설정시 통보자를 특정지어 책임회피가 불가능하도록 구성해야한다.
AlertManager
Prometheus 에서 발생한 alert 를 AlertManager 가 통보하는 방법을 알아본다.
간단하게 아래 3개 파일 설정 후 실제 이메일이 오는지 확인
prometheus.yamlrules.yamlalertmanager.yaml
# prometheus.yaml
global:
scrape_interval: 15s
evaluation_interval: 15s
external_labels:
region: seoul
env: demo
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
rule_files:
- "rules.yml"
scrape_configs:
- job_name: "actuator"
scrape_interval: 1s # 1초 간격으로 스크래핑, default 1m
metrics_path: '/actuator/prometheus'
static_configs:
- targets:
- '192.168.10.66:9404'
# rules.yml
groups:
- name: alert_rules
rules:
- record: job:http_request_count:rate1m
expr: rate(http_server_requests_seconds_count[1m])
- alert: AbnormalHttpRequestCount
expr: job:http_request_count:rate1m * 60 > 60 # 분당 호출횟수 60 이상
for: 5s # pending 기간
labels:
severity: page # 심각도
team: devops # 팀명
annotations: # 전달할 메세지
summary: '호출횟수 비정상'
description: >
호출횟수 비정상 알림, 호출 횟수:, 인스턴스 체크 필
# alertmanager.yaml
global:
smtp_smarthost: 'smtps.hiworks.com:465' # 이메일 서버 주소와 포트
smtp_from: 'alertmanager@demo.com' # 발신자 주소
smtp_auth_username: 'myaddress@demo.com' # SMTP 인증을 위한 사용자 이름
smtp_auth_password: 'xxxxx' # SMTP 인증을 위한 비밀번호
smtp_require_tls: false # TLS 요구 여부
templates:
- '/etc/alertmanager/template/*.tmpl' # 템플릿 파일 경로 추가
route:
receiver: fallback-email
receivers:
- name: fallback-email
email_configs:
- to: 'myaddress@demo.com' # 전송할 이메일
send_resolved: true # 해결된 알림도 보낼지 여부 (true 또는 false)
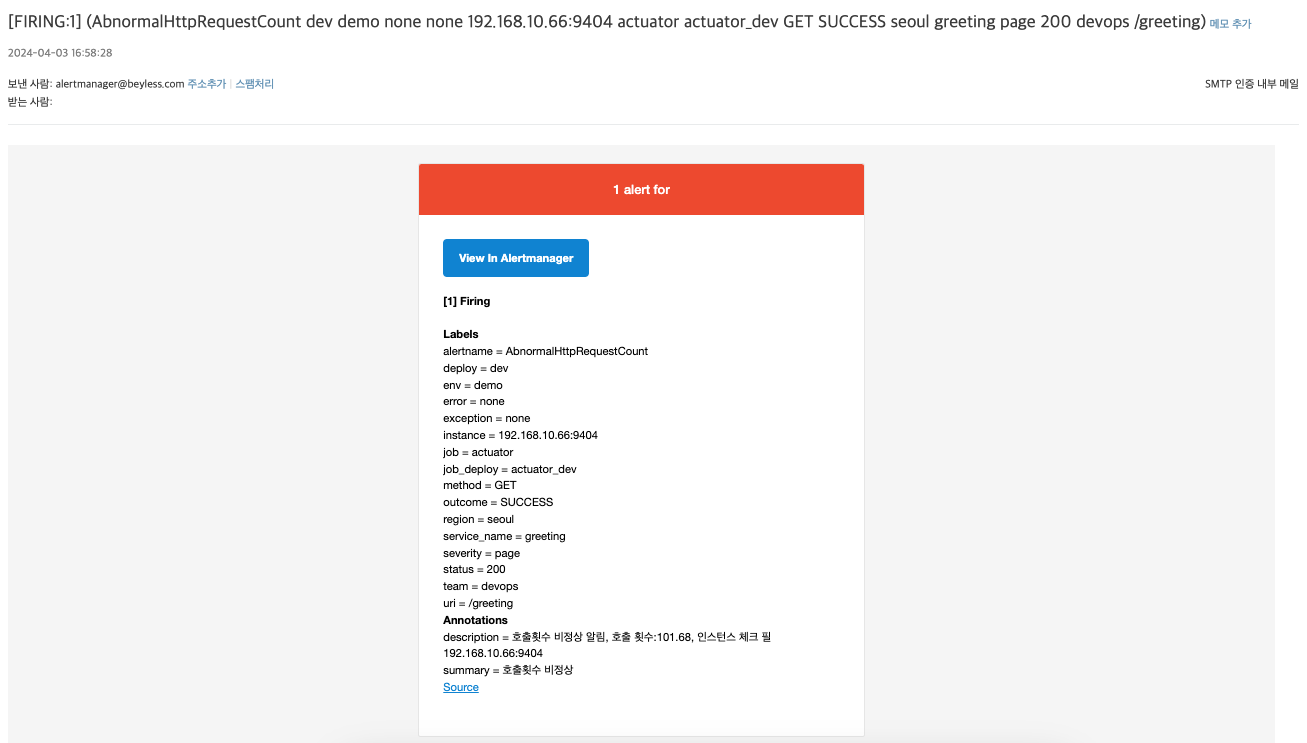
send_resolved: ture 이기 때문에 메트릭값이 다시 정상상태로 돌아오면 RESOLVED 메일도 전송된다.
alertmanager.yaml 파일을 통해 아래 컨셉에 대해 설정이 가능하다.
- inhibition
억제, 중대 장애alert가 발생했을 때, 그로 인해 발생하는 미미한alert들은 무시하기 위한 설정. - silencing
유지보수를 위해 중단한 경우, 일정 시간동안 alert 들을 무시하기 위한 설정. - routing
통보를 분배하기 위한 설정. - grouping
동인한 장애로 인해 발생하는 alert 의 개수를 줄이는 그룹화를 위한 설정. - thortting, repetition
조절, 반복, 그룹에 대한 통보를 조절를 위한 설정. - notification
alert 의 통보 템플릿 설정.
Receiver
alert 의 수신자 이자 통보자 설정을 Receiver 설정에서 할 수 있다.
아래와 같은 통보자 설정이 가능하다.
- Slack
- Webhook
- 위챗 WeChat
- 페이저듀티 PagerDuty
Email Receiver 이외 다른 Receiver 설정엔 URL, token, Key 등이 설정될 수 있다.
여기선 Email Receiver 에 대해서만 알아본다.
https://prometheus.io/docs/alerting/latest/configuration/#email_config
Email Subject 와 html Body 를 설정하기 위해 아래와 같이 설정 후 template 파일 생성
receivers:
- name: fallback-email
email_configs:
- to: 'myaddress@demo.com'
send_resolved: true # resolve 알림도 보낼지 여부 (true 또는 false)
headers:
subject: '{{ template "custom_mail_subject" . }}'
html: '{{ template "custom_mail_html" . }}'
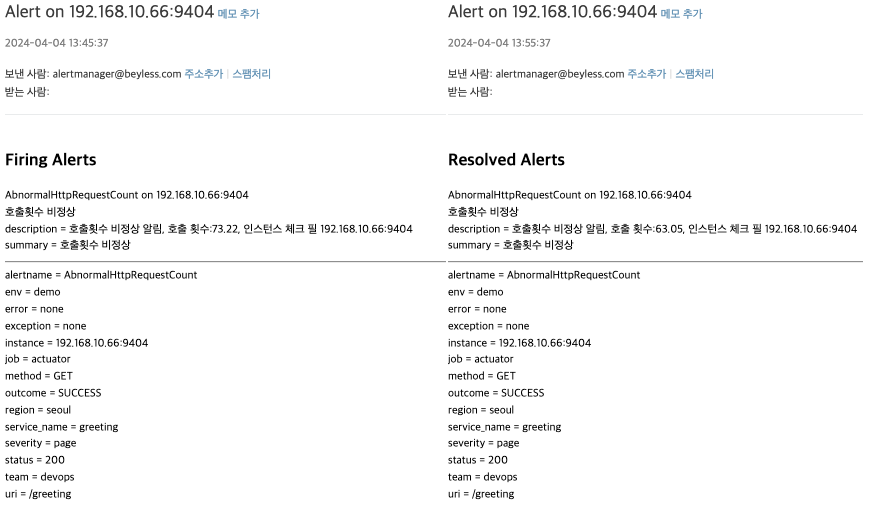
<!-- email.html -->
{{ define "custom_mail_subject" }}
Alert on {{ range .Alerts.Firing }}{{ .Labels.instance }} {{ end }}{{ if gt (len .Alerts.Firing) 0 }}{{ if gt (len .Alerts.Resolved) 0 }} & {{ end }}{{ end }}{{ range .Alerts.Resolved }}{{ .Labels.instance }} {{ end }}
{{ end }}
{{ define "custom_mail_html" }}
<html>
<head>
<title>Alert!</title>
</head>
<body>
{{ if gt (len .Alerts.Firing) 0 }}
<h2>Firing Alerts</h2>
{{ range .Alerts.Firing }}
<p>{{ .Labels.alertname }} on {{ .Labels.instance }}<br/>
{{ if ne .Annotations.summary "" }}{{ .Annotations.summary }}<br/>{{ end }}
{{ range .Annotations.SortedPairs }}{{ .Name }} = {{ .Value }}<br/>{{ end }}</p>
{{ end }}
{{ end }}
{{ if gt (len .Alerts.Resolved) 0 }}
<h2>Resolved Alerts</h2>
{{ range .Alerts.Resolved }}
<p>{{ .Labels.alertname }} on {{ .Labels.instance }}<br/>
{{ if ne .Annotations.summary "" }}{{ .Annotations.summary }}<br/>{{ end }}
{{ range .Annotations.SortedPairs }}{{ .Name }} = {{ .Value }}<br/>{{ end }}</p>
<hr />
{{ end }}
{{ end }}
<hr />
<p>
{{ range $key, $value := .CommonLabels }}
{{ $key }} = {{ $value }}<br/>
{{ end }}
</p>
</body>
</html>
{{ end }}
통보에 사용할 메세지 형식을 template 으로 미리 만들어두고 사용할 수 있으며 go 템플릿 문법을 사용한다.
template 문법은 아래 url 참고.
아래 그림과 같이 이메일이 전송된다.
라우팅 트리
# alertmanager.yaml
global:
smtp_smarthost: 'smtp.hiworks.com:25'
smtp_from: "prometheus@example.com"
# routing tree
route:
receiver: fallback-email # 모든 depth에서 receiver 는 1개이상 있어야함.
group_by: [team] # grouping 을 통해 조절, 반복
routes:
- match:
severity: page
routes:
- match:
team: backend
receiver: backend-pager
- match:
team: frontend
receiver: frontend-pager
receiver: team-pager
group_by: [team]
- match:
secertiy: (ticket|issue|email)
receiver: team-ticket
group_by: [region, env, alertname]
receivers:
- name: fallback-email
email_congis:
- to: "fallback@example.com"
- name: team-pager
# ...
- name: team-ticket
# ...
보다싶이 route 속성은 트리 형태로 구성되며 라우팅 트리 라 부른다.
각 route 별로 기본 receiver 들이 존재하며, 매칭되지 않은 alert 는 기본 receiver 들에게 전달된다.
그룹화
group_by 는 alert 를 그룹화 하기위한 설정
비슷한 원인으로 발생하는 다수의 경고를 하나의 알림으로 요약, 그룹화를 통해 관련된 경고들을 함께 보며 문제의 원인을 보다 쉽게 파악, 통보 프로세스를 더 효율적으로 만들 수 있다.