DB 트랜잭션!
트랜잭션
트랜잭션은 작업의 완전성을 보장한다.
논리적인 작업 셋을 모두 완벽하게 처리하거나, 작업의 일부만 적용되는 현상(Partial update)이 발생하지 않는것을 보장하는 기능이다.
트랜잭션을 상당히 골치아픈 기능으로 생각하지만, 그만큼 애플리케이션 개발에서 고민해야 할 문제를 줄여주는 필수적 DBMS 기능이다.
계좌시스템을 예로 들면 A가 B에게 입금하는 작업을 하나의 트랙잰석(작업단위)로 볼 수 있다.
아래 2작업이 한번에 이루어져야 한다.
1) A가 B에게 돈을 입금하고 A의 보유금을 마이너스
2) B는 A에게 입금받은 돈은 보유금에서 플러스
만약 1번만 성공하고 2번은 실패할 경우 A 계좌에서 돈만 빠져나가는 오류가 발생하게 된다.
트랜잭션이 성공하면 commit 하고 중간에 어떠한 과정이라도 실패한게 있다면 rollback해야 한다.
DML문을 실행하면 해당 트랜젝션에 의해 발생한 데이터가 다른 사용자에 의해 변경이 발생하지 않도록 lock을 발생시킨다.
lock은 commit 또는 rollback 문이 실행되면 해제된다.
오라클 SYS 계정과 SCOTT 계정에 각각 접속하여 트랜잭션 처리를 확인. SYS계정에선 MILLER의 job이 CLERK라 출력된다.
-- SCOTT의 계정에서 실행
UPDATE emp SET job = 'ARTIST' WHERE ename = 'MILLER';
SELECT ename, job FROM emp WHERE ename = 'MILLER';
-- (MILLER, ARTIST) 출력
-- SYS의 계정에서 실행
SELECT ename, job FROM emp WHERE ename = 'MILLER';
-- (MILLER, CLERK) 출력
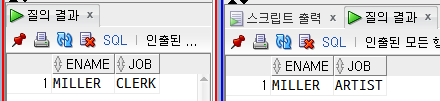
SYS가 빨간색, SCOTT이 파란색.
SCOTT 계정 접속세션에서만 변경되었기 때문에 SYS 계정 세션에선 MILLER의 job은 아직 CLERK이다.
이 상태에서 SYS계정에서 MILLER의 job을 XXXX로 업데이트 진행.
UPDATE scott.emp
SET job = 'XXXXX'
WHERE ename = 'MILLER';
아직 SCOTT 계정 세션에서 update & commit 하지 않았기 때문에 SYS 계정 세션에선 lock 으로 인해 무한로딩된다.
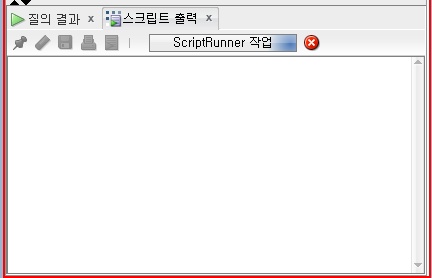
SCOTT 계정세션에서 commit 하는 순간 SYS 계졍세션의 update 도 lock 이 풀리면서 실행된다.
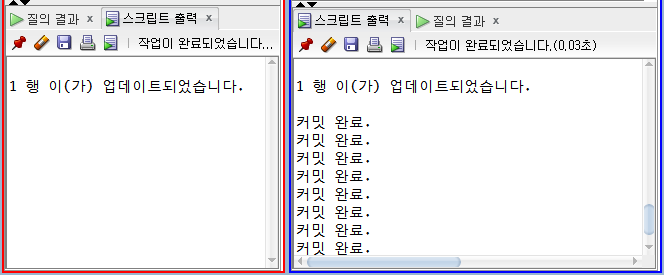
이젠 SYS 계정 세션에서 emp 테이블에 lock 을 걸었고 commit 해주기 전엔 다른 세션에서 해당 데이터를 수정하거나 삭제하지 못한다.
ACID
출처: 위키
ACID(원자성, 일관성, 고립성, 지속성) 는 트랜잭션이 안전하게 수행된다는 것을 보장하기 위한 성질을 가리키는 약어이다.
원자성(Atomicity)
트랜잭션 내 작업들이 부분적으로 실행되다가 중단되지 않는 것을 보장하는, 전체 성공하거나 실패하더라도 모든 내용을 취소하는 어보트 능력(abortability) 이다.
일관성(Consistency)
트랜잭션이 성공적으로 완료하면 설정해둔 무결성 제약 을 포함해 언제나 일관성 있는 데이터베이스 상태로 유지하는 것을 의미한다.
격리성(Isolation)
트랜잭션A 수행 시 다른 트랜잭션B 가 끼어들지 못하도록 보장하는 것을 의미한다.
지속성(Durability)
트랜잭션이 성공적으로 완료하면 영원히 반영되어야 함을 의미한다. 복구/복제 기능을 구현하기 위해 여러가지 기능이 트랜잭션 로그를 사용함.
스케줄 serializable
Serializable 여러개의 트랜잭션이 동일한 시간대에 실행될 경우 read/write 요청이 섞이더라도 모두 동일한 결과값을 요하는 성질이다.
DB 가 트랜잭션을 받게되면 아래 2가지 방식으로 수행될 수 있다.
- Serial Shcedule
- Non-serial Schedule
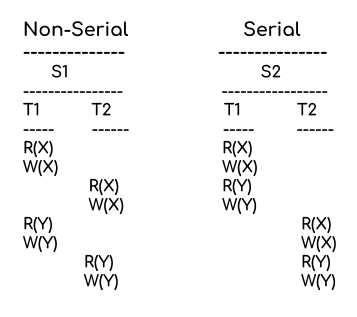
모든 트랜잭션이 Serial shcedule 으로 처리된다면 아래에서 알아볼 [락, 격리] 등은 알필요가 없다.
하지만 대부분 DBMS 에선 성능때문에 트랜잭션을 Non-serial Schedule 으로 처리하면서
ACID 요구사항을 만족시키기 위해 각종 제약조건을 사용한다.
제약조건의 목표는 Non-serial Schedule 의 트랜잭션들이 conflict serializable(충돌직렬화) 조건을 만족하는 것.
conflict serializable 은 Non-serial Schedule 의 트랜잭션들이 하나의 자원을 read/write 하는 순서가
Serial shcedule 에서 하나의 자원을 read/write 하는 순서가 동일함을 뜻한다.
read/write 하는 순서가 동일할 경우 Serial Schedule Non-serial Schedule 상관없이 모두 동일한 결과가 출력된다.
스케줄 recoverability
recoverability 는 스케줄이 rollback 되었을 때 복원성을 의미한다.
여러개의 트랜잭션이 동시에 실행되다 특정 트랜잭션이 rollback 될 경우 정상적으로 복원되지 않을 경우가 있다.
특이한 조건에서 recoverability 가 손상되는 상황을 알아보고
아래 3가지 종류의 스케줄을 사용해 방지하는 방법을 알아본다.
Recoverability ScheduleCascadeless ScheduleStrict Schedule
https://www.geeksforgeeks.org/types-of-schedules-based-recoverability-in-dbms/
Recoverability Schedule
아래 그림처럼 스케줄 내에서 Dirty Read 가 발생하는 경우를 복구하기 위한 스케줄 방법임.
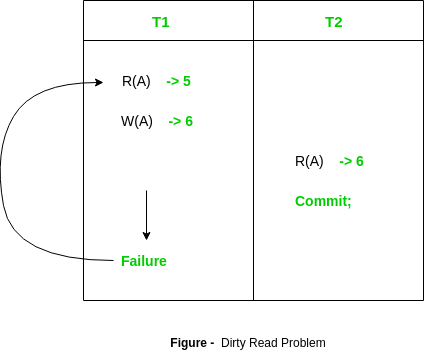
T2 가 commit 되지 않은 값을 read, R(A)=6 하고 T1 이 rollback 하게되면서 부정확한 값이 되어버렸다.
트랜잭션의 의존관계를 파악하고, 부모 트랜잭션이 commit/rollback 되는것을 확인한 후 자식 트랜잭션도 commit/rollback 하는 스케줄을 Recoverability Schedule(보존 스케줄) 이라 한다.
Recoverability Schedule 은 트랜잭션의 의존관계를 파악하고 부모 트랜잭션과 자식 트랜잭션을 연결해서 commit/rollback 해야한다. cacading rollback 이라 하는데 비용이 높아 사용하지 않는다.
그래서 cacading rollback 기술을 사용하지 않으면서도 recoverability 를 확보하기 위해 Cascadeless Schedule 를 사용한다.
Cascadeless Schedule
데이터를 write 한 트랜잭션이 commit/rollback 되기 전까지는 read 를 제한하는 스케줄을 Cascadeless Schedule(비종속 스케줄) 이라 한다.
아래 그림처럼 동일한 자원 X 를 건드리는 트랜잭션 3개가 있을 경우 commit(초록박스) 되기까지는 read 접근을 막아 종속관계를 없엔다.
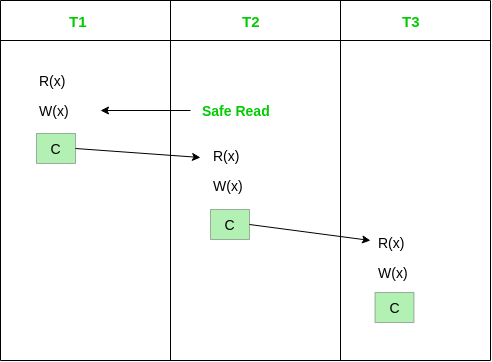
Cascadeless Schedule 는 read 에 대해서만 접근제한하고 wirte 는 별도로 제한하지 않기 때문에,
write 트랜잭션이 연속적으로 일어나는 환경에서 rollback 으로 인해 일부 write 트랜잭션들이 무시될 수 있다.
Strict Schedule
데이터를 write 한 트랜잭션이 commit/rollback 되기 전까지는 read/write 모두 제한하는 스케줄을 Strict Schedule(엄격한 스케줄) 이라 한다.
아래 그림과 같이 스케줄 다이어그램으로 구분할 수 있으며
Strict Schedule 이 공유자원에 대해 가장 엄격하게 관리한다.

앞으로 설명할 [락, 격리레벨] 등은 모두 트랜잭션의 [serializable, recoverability] 속성을 만족시키기 위해서다.
MySQL 트랜잭션
MySQL 은 로그 기반(Undo/Redo Logs)의 트랜잭션 관리를 통해 원자성을 제공한다.
- Undo Log
- 트랜잭션 중에 변경된 데이터를 이전 상태로 되돌릴 수 있게 해주는 로그.
- 만약 트랜잭션 도중 실패하면 Undo 로그를 사용해 변경된 데이터를 원래 상태로 복구.
- Redo Log
- 트랜잭션이 커밋된 후, 시스템 장애가 발생해도 데이터를 복구할 수 있게 해주는 로그.
- 커밋된 데이터를 디스크에 안전하게 기록해주는 역할.
InnoDB 엔진의 경우 디스크쓰기 작업 오류 방지를 위해 첫 번째로 버퍼에 기록하고, 이후 실제 데이터 파일에 기록하는 Doublewrite Buffer 기법을 사용한다.
락(Lock)
락은 동시성을 제어하기 위한 기능
트랜잭션은 데이터의 정합성을 보장하기 위한 기능.
락은 개념적으로는 아래와 같이 두종류로 나눌 수 있다.
- Read Lock
Shared Lock(공유 락)이라고도 하며 다른 트랜잭션이 read 하는것을 허용하고 write 하는것을 비허용한다. - Write Lock
Exclusive Lock(배타적 락)이라고도 하며 다른 트랜잭션이 read/write 하는것을 모두 비허용한다.
락의 호환성은 아래와 같다.
| Read Lock | Write Lock | |
|---|---|---|
| Read Lock | O | X |
| Write Lock | X | X |
MySQL InnoDB Lock
MySQL 에서 기본적으로 제공하는 잠금은 아래와 같다.
- Global Lock: MySQL 서버 전체 잠금을 설정, 백업시에 주로 사용.
- Table Lock: 개별 테이블 단위로 잠금을 설정
- Named Lock:
GET_LOCK()함수를 통해 임의 문자열에 대해 잠금을 설정.
MySQL InnoDB 에서 별도로 레코드 기반 잠금기능을 제공한다.
- Record Lock: 인덱스의 레코드를 잠근다. 기본키, 유니크 인덱스 관련 작업은
Record Lock을 사용한다. - Gap Lock: 레코드와 인접한 위 아래 간격을 잠근다. 레코드 사이 새로운 INSERT 를 제어한다.
- Next-Key Lock:
Record Lock + Gap Lock형태의 잠금.
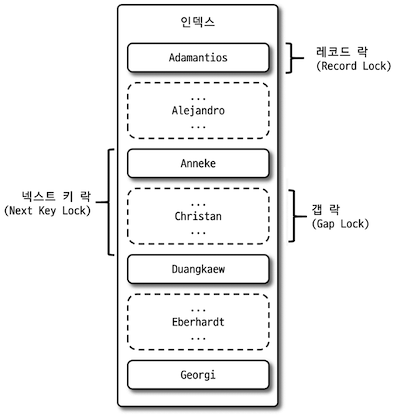
MySQL InnoDB 에서 인덱스 기반으로 SELECT 요청을 할 경우 해당 인덱스의 레코드에 Next-Key Lock 이 발생한다.
FOR SHARE, FOR UPDATE 와 같이 명시적인 잠금을 사용할 때에도 Next-Key Lock 이 발생한다.
기본키나 고유 인덱스를 사용하여 단건 조회시 Next-Key Lock 을 피할 수다.
Next-Key Lock으로 인해 해당 인덱스를 수정/삭제 하거나, Gap 안에 새로운 레코드를 추가할 수 없다.
만약 인덱스가 아닌 필드를 기반으로 SELECT 요청을 할 경우 테이블 전체에 락을 걸게 됨으로 철저한 인덱스 설계가 필요하다.
트랜잭션 격리
트랜잭션 격리 는 트랜잭션 처리 과정에서 두개 이상의 트랜젝션이 동시에 같은 공유 자원 접근시(Race Condition) 발생하는 문제를 처리하기 위한 제약조건이다.
위에서 설명한 트랜잭션의 [serializable, recoverability] 속성을 만족시키기 위한 제약조건이기도 하다.
여러개의 트랜잭션이 하나의 자원에 접근할 때 별도의 제약조건 없이 read/write 할 수 있도록 풀어줄경우 아래와 같은 이상한 상황이 발생할 수 있다.
- Dirty Read
- Nonrepeatable Read
- Phantom Read
격리레벨은 커넥션(세션)마다 고유하게 설정할 수 있으며 아래 명령어로 현재 DB 에서 기본 실행되는 커넥션의 격리레벨 조회가능하다.
-- mysql
-- SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SELECT @@transaction_isolation;
-- REPEATABLE-READ
Dirty Read
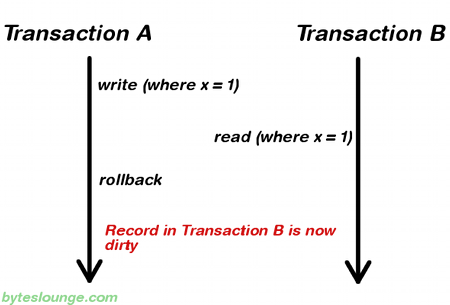
READ_UNCOMMITED 가능할 경우 commit 되기전 정보를 read 할 수 있다.
이 과정에서 오류가 발생되어 읽어온 정보가 rollback 된다면 read 된 정보는 잘못된 정보가 되어버린다.
이렇게 잘못된 정보를 읽는 것을 Dirty read 라 한다.
READ_COMMITTED 으로 설정하면 commit 된 데이터만 read 할 수 있음으로 Dirty Read 가 발생하지 않는다.
Nonrepeatable Read
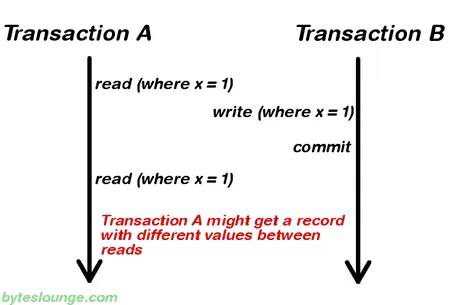
한 트랜잭션에서 별도의 쓰기작업 없이 처음 읽어드린 값과 두번째 읽어드린 값이 다른 상황을 Nonrepeatable Read 이라한다.
Phantom Read

여러개의 레코드를 read 하는 경우에서 발생하는 이슈로 처음 읽었을 때 와의 레코드개수와 두번째 읽었을 때 레코드 개수가 다른 경우를 Phantom Read 라 한다.
격리레벨(isolation level)
위와 같은 문제를 해결하기 위해 하나의 트랜잭션을 격리하기 위한 제약조건을 level 로 표현했다.
| 격리레벨 | Dirty Read | Nonrepeatable Read | Phantom Read |
|---|---|---|---|
| READ_UNCOMMITED | O | O | O |
| READ_COMMITTED | X | O | O |
| REPEATABLE_READ | X | X | O |
| SERIALIZABLE | X | X | X |
- READ_UNCOMMITED
다른 트랜잭션에서 커밋하지 않은 데이터read가능. - READ_COMMITTED
다른 트랜잭션에 의해 커밋된 데이터만read가능. - REPEATABLE_READ
DB 별로 구현방법이 다름, 스냅샷과 같은 방식으로 트랜잭션들을 격리함. - SERIALIZABLE
선점한 트랜잭션이 수행중일 때read/write할 수 없다.
DB 제조사별로 격리레벨에 차이가 있다, MySQL, PostgreSQL 의 경우 MVCC 방식을 사용하기에 READ_COMMITTED 격리레벨만 사용해도 Dirty Read, Nonrepeatable Read 를 방지할 수 있다.
MVCC
출처: Real MySQL
락 기반 Concurrency Control 의 경우 Read Lock 만 공유되기에 성능에서 떨어진다.
특히 [READ_COMMITTED, REPEATABLE_READ] 를 락 기반으로 구현할 경우 다량의 Read Lock 이 발생하고 심한 고립성을 가지게 된다.
그래서 대부분 DBMS 가 락 기반 Concurrency Control 을 하지 않고 MVCC(Multiversion Concurrency Control) 기법을 사용해 REPEATABLE_READ 를 구현한다.
DBMS 별로 다양한 MVCC 구현방법이 있는데, MySQL InnoDB 의 MVCC 는 특정 시점의 변경정보를 version 으로 기록하기 위해 Undo Log 를 사용한다.
아래 그림과 같이 업데이트 이전 값은 Undo Log 에 빼놓고 새로 삽입한 값은 Buffer Pool 에 일정시간 저장되어 있다가 백그라운드 스레드에 의해 디스크에 기록된다.
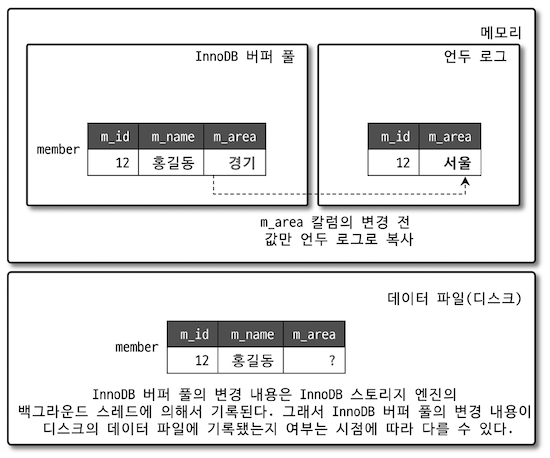
READ_UNCOMMITTED 의 경우 Buffer Pool 에서 데이터를 읽어서 반환하고
READ_COMMITTED 혹은 그 이상의 격리레벨의 경우 Undo Log 에서 데이터를 읽어 반환한다.
Undo Log 에서 락 제한 없이 값을 읽어 Non-Locking Consistent Read(잠금 없는 일관된 읽기) 라 부른다.
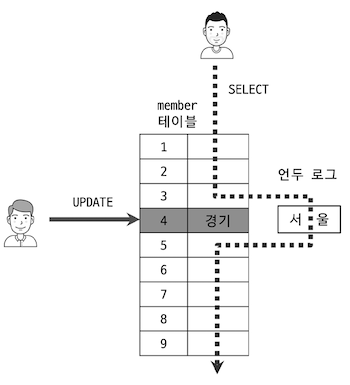
아래 그림처럼 4번 index row 는 Buffer Pool 과 Undo Log 2가지 version 으로 관리된다.
MySQL 격리레벨
MySQL 의 경우 기본 격리레벨이 REPEATABLE_READ
MySQL 의 Undo Log MVCC 기법은 READ_COMMITTED, REPEATABLE_READ 에서 모두 사용된다.
트랜잭션은 접근한 데이터를 Undo Log 를 통해 조회 및 변경하기 때문에 실제 테이블에 바로 데이터를 변경하지 않고 commit 이 완료된 이후, 백그라운드 스레드에 의해 적용된다, 따라서 자연스럽게 Dirty Read 를 방지한다.
또한 모든 트랜잭션이 MVCC 로 동작할 경우 접근한 데이터를 Undo Log 를 통해 관리하기에 타 트랜잭션이 접근한 데이터에 침범하는 Nonrepeatable Read 를 방지할 수 있다.
그리고 MySQL REPEATABLE_READ 격리레벨에선 추가적으로 Next-Key Lock 을 사용하기 때문에 Phantom Read 가 발생하지 않는다.
따라서 엄밀히 말하자면 MySQL 의 READ_COMMITTE 에선 Nonrepeatable Read 까지 방지할 수 있고, REAPEATABLE_READ 에선 Phantom Read 까지 방지할 수 있다.
Next-Key Lock 이 성능저하를 야기함으로 인덱스를 통한 범위조회 사용시 주의해야 하고, 안정성보다 성능을 중요시하고 싶다면 READ_COMMITTED 로 격리레벨을 낮춰 사용해야 한다.
MySQL 에서 SERIALIZABLE 격리레벨을 사용하면 모든 SELECT 가 자동으로 SELECT ... FOR SHARE 로 암묵적 변환된다.
MySQL InnoDB 에선 기본 REAPEATABLE_READ 로 커넥션을 생성한다.
PostgreSQL 격리레벨
PostgreSQL 의 경우 기본 격리레벨이 READ_COMMITTED
PostgreSQL 내부적으로 READ_COMMITTED, REPEATABLE_READ, SERIALIZABLE 3가지 격리레벨만 존재한다.
PostgreSQL 역시 트랜잭션 고유의 txid 를 사용하여 데이터들의 스냅샷을 관리하는 MVCC 방식을 사용한다.
트랜잭션은 자신의 txid 가 반영된 데이터 레코드만 보이기 때문에 READ_COMMITTED 격리레벨만 설정해도 Dirty Read 와 Nonrepeatable Read 가 방지된다. 하지만 Phantom Read 는 발생할 수 있다.
자신보다 큰 txid 가 작성한 row 는 commit 여부 상관없이 질의해도 보이지 않는다.
REPEATABLE_READ격리레벨은 스냅샷 형태로 구현하다 보니Snapshot Isolation이라 부르기도 한다.
각 트랜잭션은 데이터 접근시 자신만의 데이터 스냅샷을 보유하게 되며, 이를 통해 다른 트랜잭션에서의 변경으로 인해 Nonrepeatable Read 가 발생하지 않는다.
또한 Snapshot Isolation 레벨에서 두개의 트랜잭션에서 write 요청 이 발생하면 트랜잭션 매니저가 abort(쓰기 충돌) 를 발생시킨다.
만약 트랜잭션1 start-commit 사이에 트랜잭션2 가 먼저 commit 했다면 후에 트랜잭션1 commit 은 abort 된다. 그래서 First-Committed-Wins 이라는 이름으로 불리기도 한다.
트랜잭션이 abort 되면 그동안의 write 명령 은 모두 무시된다.
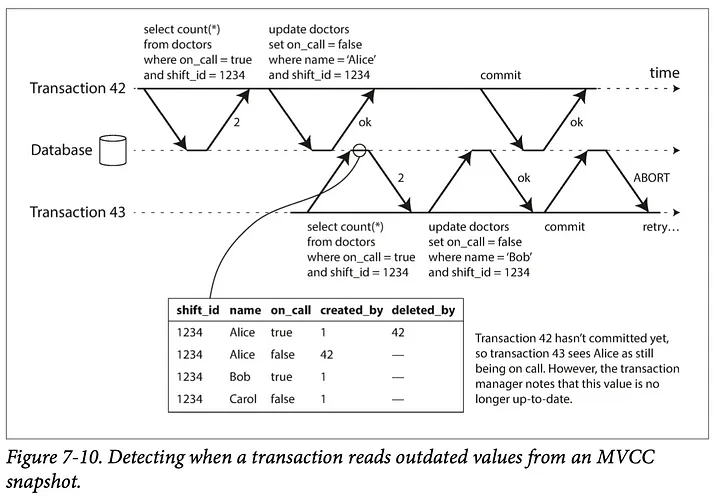
트랜잭션이 직렬적으로 실행되었는지 여부는 commit 발생시 해당 레코드의 version row 를 트랜잭션 매니저가 확인하여 사이에 변화가 일어났는지 확인하여 판단한다.
위 그림에선 트랜잭션43 이 보고있는
Alice true데이터 레코드가deleted by 42처리되었다.
더이상 해당 트랜잭션이 직렬적으로 실행되었다고 볼 수 없게 되었다.
트랜잭션이 commit 되기 전 해당 데이터 레코드의 version row 가 변경되었는지 한번 더 확인하고, 실행중 격리가 되지 않은 트랜잭션은 abort 처리, 직렬적으로 실행된 트랜잭션은 commit 된다.
Snapshot Isolation 은 잠금 없이 트랜잭션들을 실행시키지만 트랜잭션들의 경쟁이 심해지면 직렬로 실행되지 못한 트랜잭션이 많아지면서 abort 비율이 높아져서 Write Lock 을 사용하는 SERIALIZABLE 보다 성능이 떨어질 수 있다.
또한 Snapshot Isolation 레벨에서 인덱스 조회시 모든 version row 를 찾고 필터링 하는 방식으로 운영되다 보니 많이 느리다. 그리고 직렬화 여부를 온전히 트랜잭션 매니저에 의탁하기에 DB 부하가 일어날 수 있다.
그럼에도 Snapshot Isolation 를 사용해야 하는 이유는 락 없이 직렬화 구현이 가능하다는 점, 대부분 쿼리요청이 read 이기에 abort 가 많이 발생하지 않아 효율적이기 때문이다.
SERIALIZABLE 격리레벨은 Serializable Snapshot Isolation(SSI) 이라 불리며, 읽기에 대한 version row 를 추가로 관리한다.
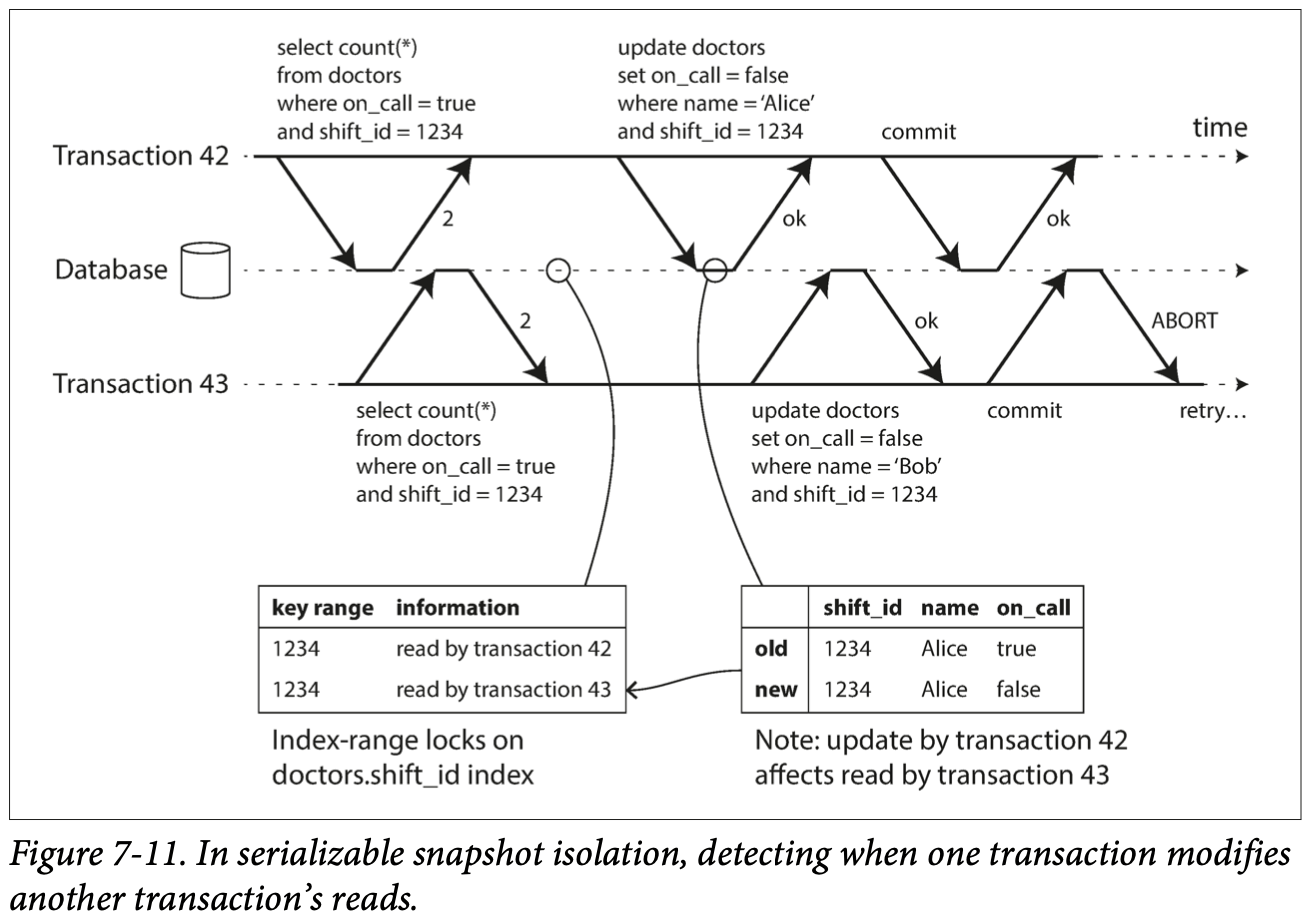
Snapshot Isolation 에서 약간의 변화만 있을 뿐 추가적인 락을 걸지 않고 읽기 충돌 을 추가로 감지할 수 있게 되었다.
만약 트랜잭션42 가 트랜잭션43 이 읽은 key range 사이에 새로운 데이터 레코드를 삽입할 경우 위 그림과 같이 읽기 충돌 을 감지하여 읽은 데이터가 old version 임을 알 수 있게된다.
MySQL MVCC 문제점
Undo Log 를 사용해서 Non-Locking Consistent Read 하는 것은 좋지만, read 에 대해 제약조건 없이 접근을 허용할 경우 Dirty Read 가 발생할 수 밖에 없다.
위 그림만 봐도 실제 값은
경기인데 읽어드린 값은서울이다.
여기서의 Dirty Read 는 위에서 설명한 rollback 으로 인한 Dirty Read 와는 결이 다르다.
순서 차이일 뿐 Undo Log 로부터 정상적으로 read 했기 때문에 Dirty Read 가 아니라고 볼수 있지만,
대다수의 아티클에서 해당 상황도 오류를 야기함으로 Dirty Read 에 포함시켜야 한다고 주장하고 있다.
만약 해당 방식으로 Dirty Read 한 값을 기반으로 write 를 수행하면 Lost Update 까지 이어진다.
물론 여기서 말하는
Lost Update는 2번의 트랜잭션으로 이루어지는 어플리케이션 코드에서 발생하는 오류이다.
MySQL MVCC 에서 기본 격리레벨인 REPEATABLE_READ 는 별도의 락 없이 동작하기 때문에 Dirty Read - Lost Update 가 충분히 발생할 수 있다.
대부분 코드에서 read-modify-write 주기로 DB 에 접근하는 방식으로 문제를 해결하는 경우가 많아 Lost Update 는 자주 발생하는 이슈이다.
PostgreSQL MVCC 문제점
아래는 [Account1, Account2] Entity 에 update 요청 을 MVCC 로 처리하는 과정이다.
모든 트랜잭션은 자신보다 높은 txid 는 읽을 수 없어 Lost Update 가 발생할 수 있다.
txid=12는select 요청진행txid=13는update 요청진행
row 의 write 요청이 일어날 때마다 새로운 version 의 복사본이 생성된다.
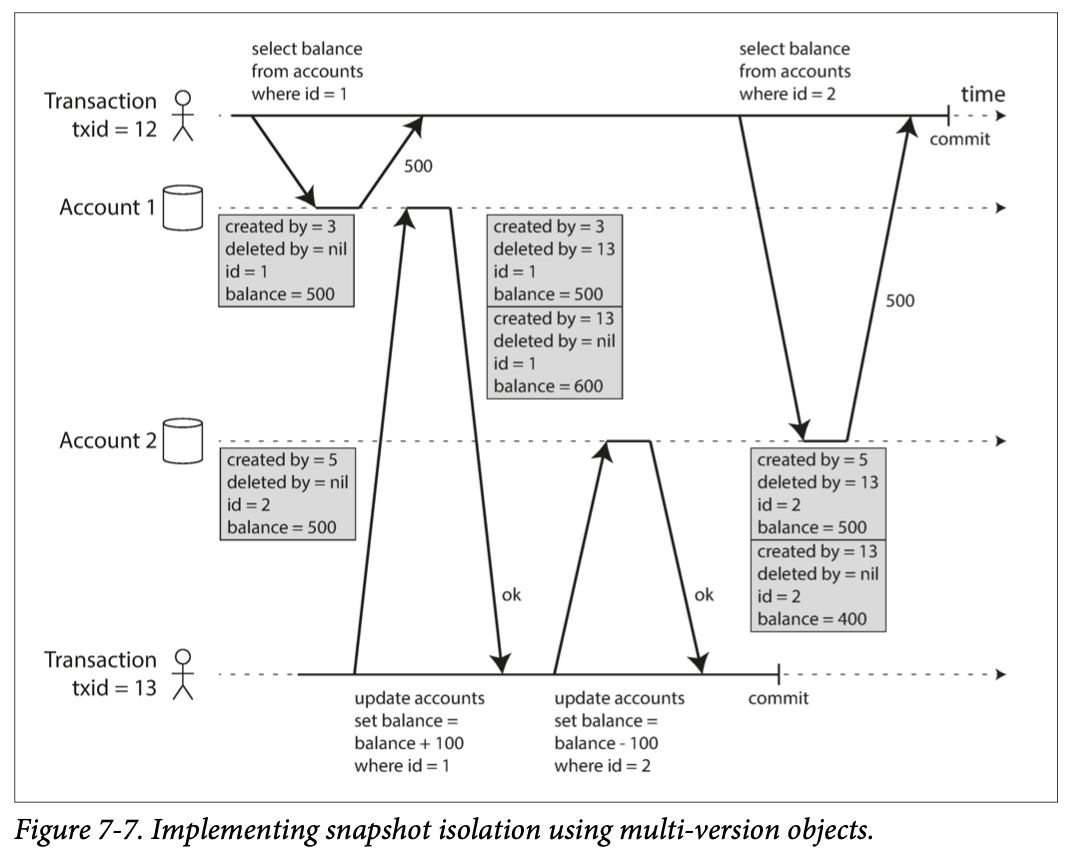
created_by:row를 삽입한txiddeleted_by:row를 삭제한txid
txid=13 는 deleted_by 만 설정할 뿐, 기존 value 는 건드리지 않고 업데이트 사항을 새로 추가한 복사본 version 을 생성한다.
나중에 모든 트랜잭션이 commit 되면 GC 가 deleted_by 표시된 row 들을 삭제한다.
deleted_by 가 활성화 되어 있어도 commit 되지 않았다면 읽기를 실행한다.
PostgreSQL 의 MVCC 에서 별도 Read Lock 을 사용하지 않기 때문에 위에서 설명한 Dirty Read - Lost Update 가 발생할 수 있다.
물론 PostgreSQL 의 트랜잭션 매니저가 이미 deleted_by 표시된 row 업데이트는 abort 하겠지만 읽어들인 500 을 가지고 어떤 작업을 할지는 모르는 일이다.
추가 이상현상
격리레벨에선 3가지 이상현상인 [Dirty Read, Nonrepeatable Read, Phantom Read] 만 소개했는데, 3가지 이외에도 격리레벨마다 추가이상현상이 존재한다.
사실상 위 3가지 이상현상에 의해 파생되는 추가이상현이다.
Dirty Write
READ_UNCOMMITED 에서 발생가능한 이상현상이다.
commit 되지 않는 데이터를 write 할 때 발생한다.
연달아서 write 만 하는 트랜잭션이 트랜잭션 스케줄이 있을 경우, 첫번째 트랜잰셕이 rollback 되면서 두번째 트랜잭션의 반영사항이 무시될 수 있다.
Lost Update
READ_COMMITTED 에서 발생가능한 이상현상이다.
Shared Lock 이 없을 때 read -> modify -> write 형태로 구성된 트랜잭션이 동시에 실행될 때 발생한다. 트랜잭션2 가 트랜잭션1 을 덮어 씌우는 경우이다.
Dirty Read 한 후 해당 데이터로 write 하고 commit 하는 것이다.
Lost Update 를 해결하는 첫번째 방법은 원자적 쓰기연산 이다.
조회와 수정이 동시에 일어나는 write 요청 을 사용하여 로직을 처리할 수 있다면 가장 쉬운 해결책이다.
UPDATE counters SET value = value + 1 WHERE key = 'foo';
Lost Update 를 해결하는 두번째 방법은 명시적인 잠금 이다.
read/write 가 복잡하게 얽힌 비즈니스 로직과 높은 동시성 제어가 필요한 트랜잭션이라면 read 요청에도 베타적 설정을 지정해줘야 한다.
-- Locking Read
SELECT balance FROM account WHERE id = '1' FOR UPDATE; -- WRITE LOCK
이런 형태의 락을 Locking Read 라 하고 read 요청 이지만 Write Lock 을 요구한다.
동시에 실행되는 두 트랜잭션을 Locking Read 로 수행할 경우 read 요청 동시에 실행되지 못하도록 막기 때문에 Dirty Read 가 발생하지 않는다.
사실상 베타적락 기반 으로 실행되는 Concurrency Control 이랑 다름없다.
경쟁 조건이 발생할 수 있지만 동시에 발생하는 트랜잭션의 read-modify-write 가 순서대로 처리되도록 강제한다.
Lost Update 를 해결하는 세번째 방법은 갱신손실 자동감지 이다.
MySQL MVCC에서 지원하지 않음,PostgreSQL MVCC에선 비슷한 형태로 지원함.
DB에서 자체적으로 운영하는 트랜잭션 관리자가 read-modify-write 과정에서 다른 트랜잭션의 deleted_by 설정된 version 이 먼저 commit 되어 Lost Update 를 발견할 경우 현재 트랜잭션을 abort 한다.
PostgreSQL MVCC 의 Snapshot isolation 처럼 version 별 커밋 여부를 파악할 수 있는 DB에서 사용되고 있는 방법이며 어플리케이션에서도 예외처리만 하면 될뿐 별도의 수정을 할 필요가 없다.
Lost Update 를 해결하는 네번째 방법은 Compare & Set 이다.
원자적 쓰기연산 과 유사한 방법으로 수정하며 이전값의 조건문을 통해 갱신을 시도한다.
UPDATE wiki_pages SET content = 'new content'
WHERE id = 1234 AND content = 'old content'; -- 이전 값 기준 필터링
Write Skew
Lost Update 가 일어나지 않는다면 모든 문제가 해결될것 같지만 그렇지 않다.
Write Skew 는 DB 레이어가 아닌 어플리케이션 레이어에서 제한하고 있는 조건을 위배하는 이상현상이다.
예를들어 최소 한명 이상의 경비원이 모니터링해야 하는 시스템에서 경비원이 휴식버튼을 누를때마다 어플리케이션은 다른 경비원이 모니터링중인지 확인하는 로직이 있다 가정하자.
만약 모든 경비원이 동시에 모니터링상태에서 휴식버튼을 누르게 될 경우, 어플리케이션에선 당연히 한명이상 근무중인 경비원이 있다고 판단하고 모든 경비원에게 휴식상태를 부여하게 된다.
최종적으로는 어플리케이션에서 제한하고 있는 조건을 위배하게 될 것이다.
경비원 모두 자신의 레코드에 접근하여 상태값을 변경할 것이기 때문에 Lost Update, Dirty Read 로 발생한 문제도 아니다.
예약 시스템도 마찬가지이다, 해당 시간대에 예약이 없는지 체크하고 예약 레코드를 삽입하는 시스템에서 동시에 동일한 예약시간에 예약을 진행하면 레코드가 2개가 들어가게 된다.
범위 질의를 통해 Phantom Read 가 발생한 이후 write 요청 시에 주로 발생한다.
SERIALIZABLE 격리레벨을 사용하면 막을 수 있다.
SERIALIZABLE 격리레벨 구현 방법
충돌 구체화(materializing conflict)
충돌 구체화는 어플리케이션에서 데이터 모델을 인위적으로 비틀어 해결하는 방법이라 거의 사용하지 않는다.
위의 회의실 예약을 예로 들면, 예약 시간에 대한 row 를 만들고 row 집합에 대한 잠금 충돌로 Write Skew 를 예방하는 방법이다.
대부분 Write Skew 를 피하기 위해 SERIALIZABLE 격리수준을 사용한다.
SERIALIZABLE 격리수준은 발생 가능한 모든 경쟁 조건을 막는 가장 강력한 격리 수준이다.
대부분 DB 은 아래 3가지 기법중 하나를 사용한다.
- 트랜잭션을 순차실행
단일코어, SP 기반으로 트랜잭션을 강제로 순서대로 실행되도록 제어한다. - 2PL(two-phase locking)
- SERIALIZABLE SNAPSHOT
2PL(two-phase locking)
2PL(two-phase locking) 은 트랜잭션에서 모든 locking 명령이 최초의 unlock 명령보다 먼저 수행되도록 하는 방법이다.
락을 통해 트랜잭션의 read/write 순서를 강제하면서 자연스럽게 Serializable 를 만족하게 된다.
하지만 모든 트랜잭션이 자원을 공유하지 않기 위해 락을 흭득하게되면 데드락 상태가 발생하게 된다.
여기서 말하는 잠금의 종류는 아래와 같다.
- 테이블 전체를 잠금
- 색인 범위 잠금(index-range locking, next-key locking)
- 서술 잠금(WHERE 조건을 통해 검색된 row 잠금)
Conservative 2PL
모든 Lock 을 취득한 다음 트랜잭션을 수행한다.
모든 자원을 가져야 트랜잭션이 수행됨으로 데드락이 발생하지 않는다.
하지만 모든 Lock 을 취득하기 위한 시간이 오래 걸림으로 성능이 떨어져 잘 사용하지 않는 방법이다.
read_lock(X)
write_lock(Y)
write_lock(Z)
...
unlock(X)
...
unlock(Y)
unlock(Z)
commit
Strict 2PL
Strict Schedule 을 보장하는 2PL.
Write Lock 은 commit/rollback 이후에 해제한다.
read_lock(X)
write_lock(Y)
write_lock(Z)
...
unlock(X)
...
commit
unlock(Y)
unlock(Z)
Strong Strict 2PL(SS2PL)
Strict Schedule 을 보장하는 2PL.
Write Lock, Read Lock 모두 commit/rollback 이후에 해제한다.
read_lock(X)
write_lock(Y)
write_lock(Z)
...
...
commit
unlock(X)
unlock(Y)
unlock(Z)