MSA 개요!
데이터 오너쉽
출처: https://www.yes24.com/Product/Goods/117189273?pid=123487>
MSA 구조에서 어떤 데이터(테이블)이 어떤 서비스에 관리되는지, 변경이 일어나는지, 트랜잭션은 어떻게 처리되는지 결정해야 한다.
- 장바구니, 재고, 제품 도메인
- 장바구니, 재고, 제품 서비스
위와 같은 도메인 데이터와 서비스의 관계는 N:M 이다,
서비스는 여러개의 도메인을 필요로 하고, 도메인 데이터는 여러 서비스로 인해 구성된다.
이때 어떤 서비스가 어떤 데이터(테이블)를 관리할지, 데이터 오너쉽을 어떻게 관리하는지 결정해야한다.
- 단독 오너쉽(single owenership)
- 가장 단순한 구조, 데이터와 서비스가 1:1 매칭될 때 사용 가능.
- 공통 오너쉽(common ownership)
- 매우 많은 서비스가 하나의 데이터 테이블에 접근하는 경우.
감사, 권한같은 전체 서비스 공통 도메인 데이터에 접근하는 경우.- 보통 도메인 데이터 전담 서비스를 생성하여 서비스간 비동기 이벤트 기반 통신하는 경우가 일반적.
- 공동 오너쉽(joint ownership)
- 여러개의 서비스가 하나의 데이터 테이블에 접근하는 경우.
재고, 제품데이터의 연계를 통해주문이 생성될 경우,재고 서비스와제품 서비스가주문 테이블에 동시에 접근한다 할 수 있다.- 데이터의 일관성, 가용성에 대해 생각할 거리가 가장 많고 상황에 따른 기법을 사용해야 함.
공동 오너쉽은 MSA 구조에서 가장 많은 생각을 하게 하는 트레이드 오프 지점이다.
아래와 같은 기법을 사용해 공동 오너쉽을 관리한다.
- 공유 데이터 도메인 기법
- 각 서비스가 직접 도메인 데이터 테이블에 접근하여 변경.
- MSA 에서 잘 사용하지 않음.
- 하나의 도메인 데이터 테이블에 의존성이 생기지만 일관성, 가용성에 대해 이점이 생긴다.
- 테이블 분할 기법
- 도메인 데이터의 테이블을 쪼개서 각 서비스가 각자의 테이블을 단독 오너쉽으로 관리되도록 분할.
- 서비스간 복잡도가 올라가고 일관성 문제가 발생할 수 있다.
- 도메인 데이터의 분리가 확실하기 때문에 MSA 에서 주로 사용함.
- 대리자 기법
- 만약
제품, 재고도메인 데이터가 하나의 테이블로 구성되어 있고 분할할 수 없을 경우, 하지만 복잡도로 인해 서비스는 나눠야 하는 경우 사용 제품 서비스,재고 서비스 둘중 어떤 서비스가 해당 도메인 데이터 오너쉽을 가져야 하는지대리자 기법을 통해 결정할 수 있다.대리자 기법사용시 서비스간 커플링이 발생하는 하나의 테이블에 온전히 접근하기 때문에 트랜잭션 처리가 가능하다.- 주 도메인 우선(primary domain priority)
재고는제품에 종속적인 데이터이기 때문에제품 서비스가 데이터 오너쉽을 가져감.재고 서비스는제품 서비스의 API 를 통해 재고 데이터를 관리.
- 운영 특성 우선(operational characteristics priority)
- 가장 도메인 데이터를 많이 사용하는 서비스가 도메인 데이터 관리를 하는것.
- API 호출이 적어지기에 성능적으로 우수함.
- 실제
제품데이터를 가장 많이 사용하는 서비스가재고 서비스라면 데이터 테이블을재고 서비스에서 관리하는것. 물품 서비스는 물품정보 변경때만제품 서비스에 API 를 통해물품데이터를 관리한다.
- 보통
주 도메인 우선방법을 권장, 성능은 캐시를 통해 해결할 수 있다.
- 만약
- 서비스 통합 기법
- 일부 결합도가 큰 도메인 데이터의 경우 하나의 서비스로 합치는 방법.
재고, 제품도메인 데이터를카탈로그도메인으로 합쳐카탈로그 서비스하나로 관리하는 방법
공동 오너쉽의 여러 기법을 통해 최종적으로 단독 오너쉽 형태의 서비스로 발전시키거나, 처리량과 가용성을 높이는 것을 목표로 한다.
어떤 기법을 사용할 지는 상황에 따라 다르며 정답은 없다.
MSA
출처: https://m.blog.naver.com/PostList.naver?blogId=wharup&tab=1
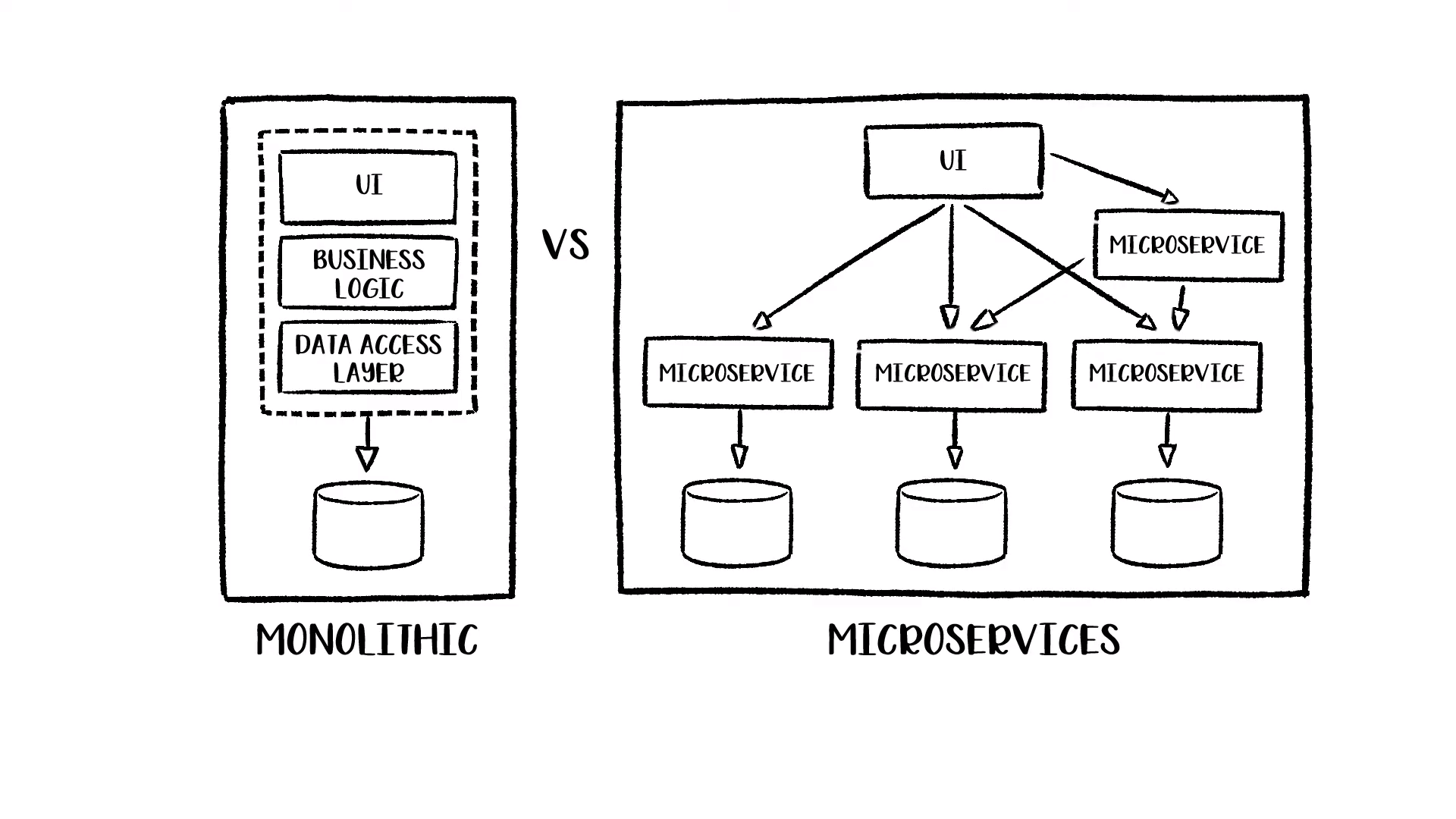
2012년 MSA(Microservice Architecture) 가 소개되고 Cloud 사업이 활성화 되면서 국내외로 많은 기업에서 MSA 형식으로 서비스를 운영중이다.
10년이 지났지만 마이크로서비스 아키텍처를 적용하는 목표가 명확하지 않다.
서비스 크기가 어느정도로 늘어났을 때 MSA 를 사용해야 하는지 기준이 없다는 뜻이다.
기존 모놀리식에 비해 아래와 같은 이점을 얻는다.
- 시스템을 빠르게 변경할 수 있다.
- 독립적인 배포가 가능하다.
- 업무 단위로 장애를 차단하고 확장할 수 있다.
시스템이 커질수록 해당 장점들이 부각된다.
DB 물리적 분리
논리적 분리만으로 충분하다 생각할 수 있지만 DB 종속적인 서비스가 되어버린다.
DB 장애가 모든 서비스의 장애로 전파되어 버리기 때문에 물리적 분리를 권장한다.
아키텍트는 데이터 분해원인, 데이터 통합원인 을 분석하고 서비스별 데이터 분리를 진행해야한다.
커넥션 관리 하나의 DB 에서 여러개의 어플리케이션 커넥션 풀을 관리하는 것은 불가능
변경관리
DDL 로 인한 변경이 어플리케이션에 영향을 끼치는 것을 물리적으로 분리, 주로 경계 컨텍스트 를 기준으로 분리함.
재사용 패턴
MSA 에서 두 원칙은 각각의 이유로 대립중이다.
- DRY(Don’t Repeat Yourself)
- 코드 중복을 피하고, 재사용성을 높이는 데 중요한 원칙
- 공유를 통해 코드 버저닝 가능
- 공유코드 변경시 전체 서비스 업데이트 필요
- WET(Write Every Time)
- 공유코드 의존성을 피하기 위해 매번 작성한다.
- 서비스간 완벽한 독립성 지원, 경계 콘텍스트가 확실함.
- 중복 코드 반영 어려움, 지속적인 수정으로 인해 코드 불일치 가능성.
보안, 로깅, 메트릭 같은 공통 인프라 기능은 사용하는 코드를 라이브러리로 만들어 서비스 코드에 적용시킨다.
기능단위로 라이브러리를 나누기 보단 변경 빈도에 따라 라이브러리를 나누는것을 권장한다.
보안, 로깅, 메트릭 같은 라이브러리를 변경할일이 거의 없는 정적인 라이브러리 임으로 하나의 라이브러리로 관리하는 것을 권장한다.
공통 서비스
재사용 패턴중 라이브러리가 아닌 서비스로 분리해서 관리하는 기법이다.
공통 서비스만 변경해도 다른 서비스에 변경된 내용이 적용되기 때문에 배포가 효율적이고 확장성이 좋다.
하지만 의존성이 생겨 전체 장애가 발생 가능하고 관리해야 할 서비스가 추가된다.
보통 로깅, 메트릭, 서비스 디스커버리, 인증, 인가 같은 운영 커플링 기능은 라이브러리로 관리하고,
그외의 프로젝트에 특화된 도메인을 서비스로 관리한다.
운영 커플링 기능의 경우 사이드카를 사용하는 경우도 있음.
성능을 위해 gRPC 프로토콜을 사용하는 경우도 있다.
[Redis, Kafka] 는 성능과 비즈니스 로직상 어쩔 수 없이 사용해야 하는 SPoF 이지만, 공통 서비스는 SPoF 를 피하도록 설계해야한다.
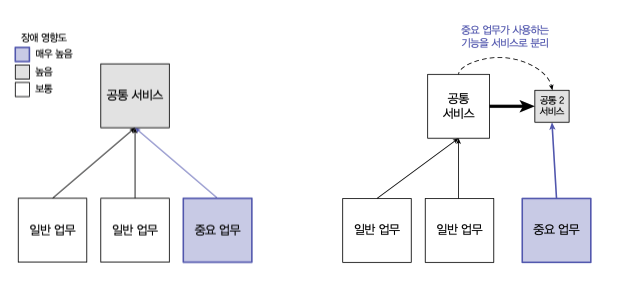
보통
공통 서비스로 거론되는 서비스는고객, 물품과 같은 큼지막한 도메인을 다루는 서비스들이다.
일반 업무 로 인해 공통 서비스 가 영향을 받아 중요 업무 에도 장애가 전파될수 있다.
우측 그림과 같이 공통 서비스 를 최대한 분리하여 SPoF 를 없애도록 설계해야한다.
완벽하진 못하더라도 공통서비스의 기능분리를 통해 최대한 장애발생 가능성을 낮추는것이 중요하다.
공통서비스를 도메인별로 최대한 분리한다 하더라도 다른 서비스에 비해 의존도가 높고 SPoF 로 취급된다.
이런 특성때문에 공통서비스가 다른 서비스를 의존할 경우 전체 시스템 장애 전파로 이어질 수 있음으로 다른 서비스 의존하면 안된다.
API 하위호환 레벨 정의
공통서비스, 공유서비스 의 API 를 설계할 땐 타 서비스의 의존성 문제가 발생할 가능성이 높음으로 versioning 사용을 권장한다.
MSA 에서 정의된 REST API 가 여러개의 클라이언트에게 의존된다. API 는 공유 정도에 따라 아래 3가지 종류로 나눌 수 있고, 공유 정도가 높을수록 높은 하위호환을 필요로한다.
- OpenAPI: 네이버 지도 API, 구글 맵 API 와 같이 공개된 API.
- InternalAPI: 기업간, 부서간 공유하는 API.
- PrivateAPI: 하나의 시스템 내에서만 공유하는 API.
처음 API 를 설계할 때 어떤 API 인지에 따라 보수적으로, 진보적으로 개발해야한다.
코드 레이어별 의존성 분리
레이어별 의존성 분리는 MSA 뿐 아니라 모놀리식 아키텍처에서도 중요하다, 클린 아키텍처의 기본인 DIP 에 해당하는 내용이다.
OpenAPI 를 설계할 경우 하위호환을 유지하기 위해서 API URL 에 versioning 정보를 포함시킨다.
보통 년단위로 versioning 이 변경되고, 구버전 유지기간도 년단위이다.
이때 레이어별로 의존성을 제대로 분리하지 않았을경우 versioning 별로 중복코드가 발생하거나, versioning 이 추가되고 나서야 의존성 분리를 하게될 수 있다.
입력 참조매개변수나 반환값이 레이어를 넘나들며 반환되거나, 필수 도메인 로직이 다른 레이어에 포함되는 등의 의존성 유착은 기피해야 한다, 추상화 레벨을 높이고 변화를 최대한 줄이는 방법을 통해 리스크를 줄여야한다.
인터페이스를 통해 내부구현과 외부공개의 의존성을 분리하고, 내부 변화에 의해 외부호출에 문제가 생길만한 변경을 하지 않아야 한다.
서비스별 의존성 분리
서비스별로 의존관계를 맺지않는것이 가장 좋고 의존관계가 약할수록 좋다.
서비스의 의존도와 도메인의 의존도를 별도로 생각해야한다.
아래 그림은 [고객, 상담, 융자] 서비스 를 도메인 기준으로 테이블을 나눈 그림이다.
도메인관점으론 [신용등급, 상담유의사항] 데이터는 고객 테이블 에 저장되는 것이 맞다.
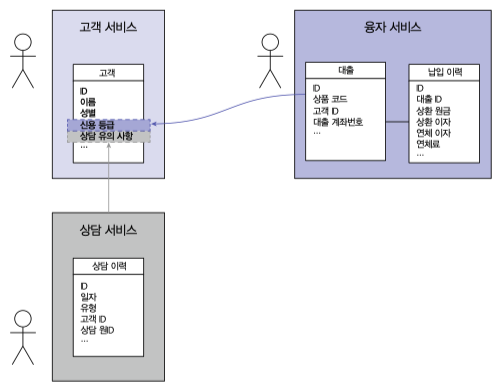
하지만 [신용등급, 상담유의사항] 데이터를 사용하는건 [융자, 상담] 서비스이다.
도메인 기준으로 테이블을 나눌경우 [융자, 상담] 서비스 요청 마다 고객 서비스로부터 값을 조회해와야 한다.
[융자, 상담] 서비스 요청이 많아질수록 고객서비스의 부하가 심해진다.
따라서 아래 그림처럼 서비스 기준으로 테이블을 구성하여 운영해야 한다.
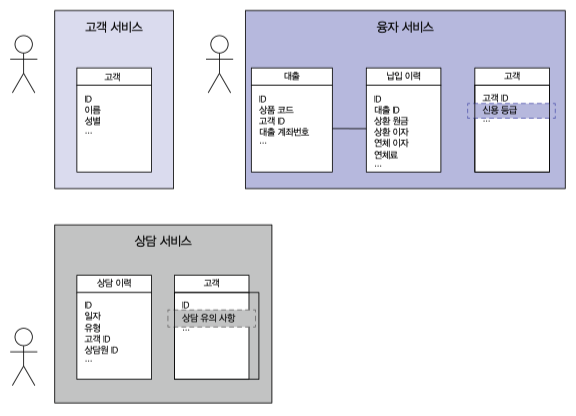
도메인 바운더리에 걸쳐있는 데이터의 경우 오너십을 가지는 서비스가 상세 데이터를 관리하는 것을 권장한다.
MSA 에서 문제거리가 되는 API 호출 delay, ACID 트랜잭션 고민사항도 사라진다.
서비스 의존성 분리를 위해 API 분리를 진행할 수 있다.
아래 그림처럼 하나의 API 가 연계되어 두개 이상의 서비스 CRUD 를 진행하면 의존성이 생기기 때문에 2개의 별도의 요청으로 나누는것을 추천한다.
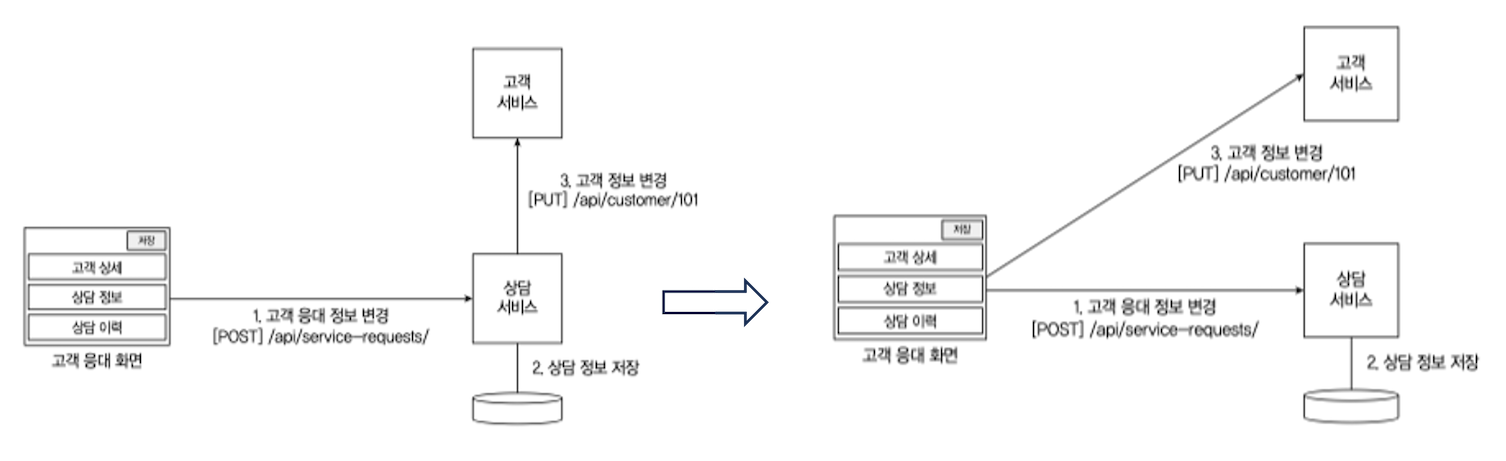
서비스별 장애, 트랜잭션 오류 문제에서 쉽게 빠져나올 수 있다.
물론 프론트엔드의 협력이 필요하기 때문에 UI 의 제약, 협력이 발생할 수 있다.
프론트엔드에서도 서비스별로 모듈화하여 각각의 팀에서 개발하는 경우가 많다보니 협업 과정에서 충분히 해결 할 수 있는 문제이다.
stateless 설계
예를들어 멀티 인스턴스의 세션관리로 Redis 를 사용했을 때, 인스턴스가 폭발적으로 늘어났을 때 Redis 가 부하를 견디지 못하면 전체서비스 장애로 이뤄진다.
이런 의존성을 줄이려면 stateless 설계방식을 통해 외부의존성, 외부서비스의 의존관계를 끊어내는 방식이 필요하다.
보통 token 을 사용한 state 를 클라이언트가 가지는 방식을 많이 사용하는데, 이로인해 기존 세션기반으로 View 레이어에서 접근제어하던 방식에서 API 서버에서 접근제어 하는 방식으로 변경되었다.
데이터 참조 튜닝
물품서비스, 재고서비스가 따로 존재하는 경우 아래와 같은 스키마가 있을 것이다.
CREATE TABLE Inventory (
itemId VARCHAR(255) PRIMARY KEY, -- 물품의 고유 식별자
quantity INT NOT NULL, -- 재고 수량
location VARCHAR(255) NOT NULL, -- 재고 위치
lastUpdated TIMESTAMP NOT NULL -- 마지막 재고 업데이트 시간
);
CREATE TABLE Product (
productId VARCHAR(255) PRIMARY KEY, -- 제품의 고유 식별자
productName VARCHAR(255) NOT NULL, -- 제품명
description TEXT -- 제품 설명
);
만약 물품서비스에서 물품정보 + 재고정보 를 같이 보여줘야 하는 상황에서 어떻게 분리된 서비스의 도메인 데이터를 합칠지 결정해야한다.
- 서비스 간 통신 패턴
- API 를 통해 데이터를 달라고 요청하는 방식으로 가장 일반적이고 구현하기 쉬움.
- 서비스간 성능과 도메인 코드에서 커플링이 발생한다.
- 컬럼 스키마 복제 패턴
- 데이터 중복을 감수하고 관련 데이터가 필요한 테이블에 같이 저장하는 방법.
- 데이터 변경 발생시 동기화로 인한 일관성 문제가 발생한다.
- 데이터 오너쉽과 경게 컨텍스트가 모호해지는 문제도 있다.
- 캐싱 패턴
- 로컬, 복제, 분산 캐시 젼략을 사용하여 서비스 호출 대신 캐시에 업근하여 데이터를 가져오는 방법.
- 캐시를 위한 별도의 저장공간, 캐시 라이브러리에 대한 의존성이 발생한다.
- 분산 캐시 서버를 사용한다면
SPoF가 추가된다. - 내고장성, 확장성 측명에서
복제 캐시 전략을 자주 사용한다. - Hazelcast, Apache Ignite 등의 오픈소스에서 복제 캐시를 지원한다.
- 데이터 도메인 패턴
- 두개의 도메인 테이블을 서비스에서 모두 접근할 수 있는 방법.
- 테이블이 같은공간에 있기에 조인과 트랜잭션을 통해 원자성, 일관성 문제가 해결된다.
- 네트워크 리소스로 인한 부하문제가 발생하지 않는다.
- 서비스대신 테이블에 대한 의존성이 생겨 테이블 변경에 의해 연관된 모든 서비스 코드가 변경될 수 있다.
MSA 에선 서비스가 커질경우 확장성을 고려해야 한다.
외부의존성을 모두 제거할순 없다. 특히 DB 나 중요서비스의 경우 어쩔수 없는 단일 장애 지점으로 구성되는 경우가 많다.
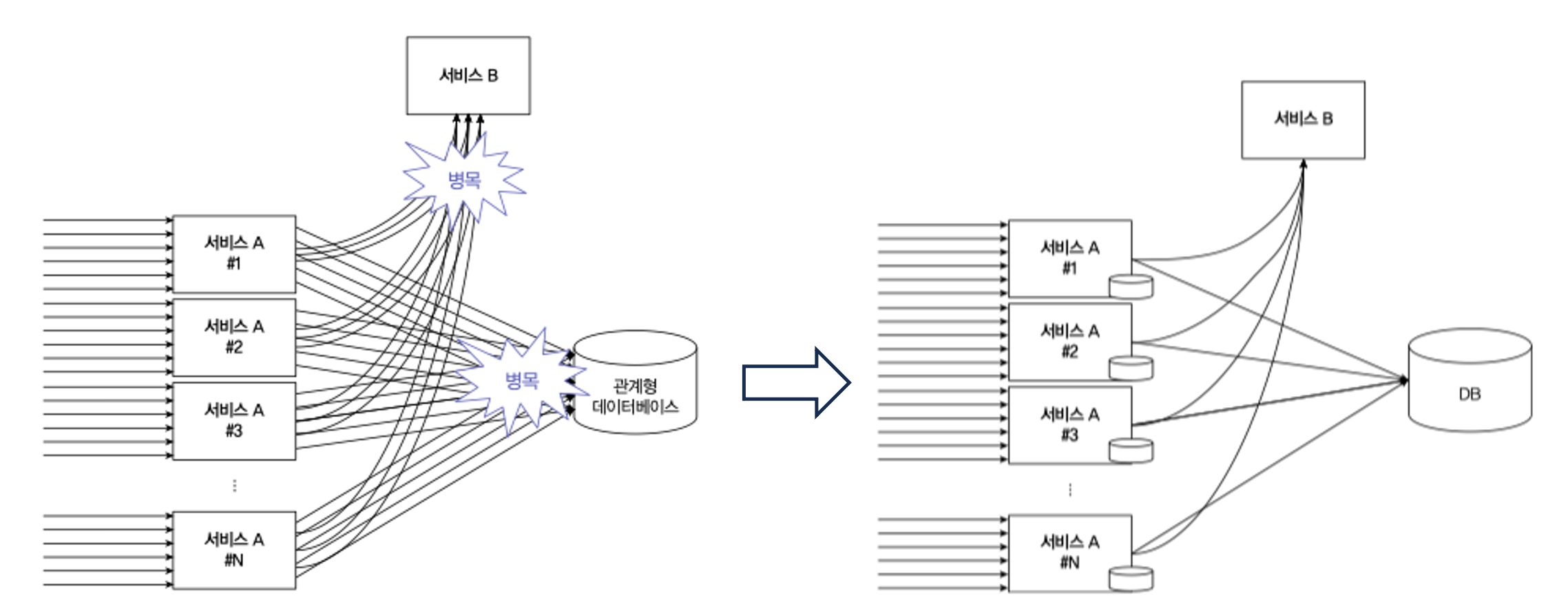
다량의 서비스간 통신이 서버 delay 를 야기함으로 최대한 서비스간 통신을 줄이는 방법을 찾아야 한다.
우측 그림처럼 인스턴스별로 로컬캐시를 운용하는 방법이 대표적인 해결책이다.
모놀리식에선 하나의 DB 로부터 데이터를 JOIN 쿼리를 조합해서 반환하는 반면 MSA 에선 각 서비스로부터 데이터를 조합해서 반환한다.
이부분에서 delay 가 발생하는데 아래와 같이 4.API 일괄요청 & 로컬캐시 방식을 사용하면 오히려 DB 로부터 검색해오는 절대적인 데이터 양이 모놀리식보다 적을 수 있다.
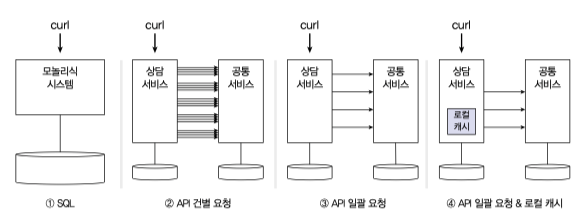
자주 변하지 않는 사용자정보와 같은 데이터는 캐시에 저장되어 관리되다보니 기존 모놀리식 JOIN 쿼리보다 빠르게 동작할 수 도 있다.
구현방법은 아래와 같다.
상담 서비스 에서 그림에 있는 테이블처럼 화면을 구성하기 위해 [고객(이름)정보, 코드(유형)정보, 관리자(상담원, VOC)정보, 부서정보] 를 각 서비스들로부터 가져와야 하는데
각 서비스별 데이터를 로컬캐시로 관리하고 캐시에 없는 데이터만 가져온다.
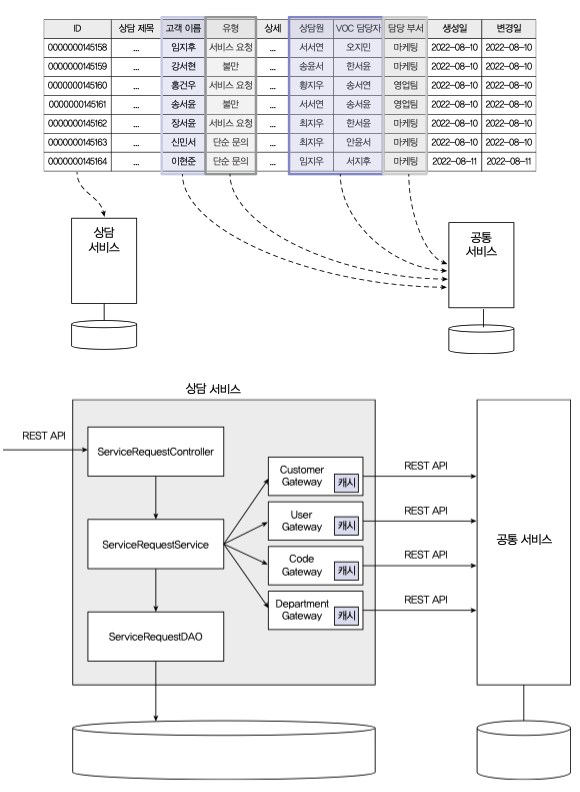
캐시에 데이터가 건별로 있는지 체크하기 위해 키값들 iterator 를 돌면서 한건씩 캐시로부터 데이터를 가져온다, 그리고 가져오지 못한 키값을 따로 저장해두고 있다가 서비스에 일괄요청한다.
[고객정보, 관리자정보] 는 고정값이 아닌 지속적으로 늘어나는 값이기에 위에서 말한 방식대로 건별로 조회 후 일괄요청하면 된다.
[코드정보, 부서정보] 는 데이터 개수가 1000개 가 안되고 변화가 거의 없는 데이터이다.
요청마다 캐시검색 후 일괄요청 하는것이 아니라, 내부 스레드에서 일정 주기마다 캐시에 저장하고 있다 반환해도 크게 문제가 없다.
마지막 변경일자값을 같이 전달하여 해당 시간 이후의 데이터만 업데이트하면 더 좋다.
단순 데이터 참조가 아닌 공통서비스로부터 데이터 동기화 기능이 필요할 경우,
아래 그림과 같이 데이터를 필요로 하는 서비스가 직접 데이터를 긁어오는 형식으로 구성해야 데이터 제약 없이 작성하기 쉽고, 각 서비스별로 자유로운 변경이 가능하다.
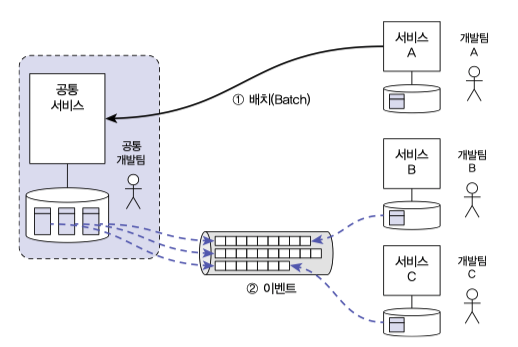
MSA 에서 이벤트 기반 구조를 사용할 경우 At-least-once 를 제공하는 메세지 서비스를 채택해야 한다.
Kafka 와 같이 신뢰성 높은 메세징 서드파티를 사용하여 동기화 하는 것을 권장한다.
- At-most-once(최대 한번): 최대 한 번만 전송한다.
- At-least-once(최소 한번): 메시지를 전송하고 상대방이 메시지는 받았는지 확인한다.
- Exatly-once(정확히 한번): 메시지를 정확히 한번만 전송한다.
At-least-once 는 메세지를 중복해서 수신받을 수 있기 때문에 메세지 수신처리를 멱등적으로 처리해야한다.
캐시전략
MSA 에서 부하를 줄이기 위해 캐시를 사용하는 것은 필수이다.
상위 20% 가 전체 생산의 80% 를 해낸다는 파레토 법칙 이 있다.
데이터저장공간에서도 전체데이터중 20% 가 중점적으로 쓰이기에 DB 에서 자주 나오는 용어이다.
파레토 법칙때문에 DB 샤딩을 구성할 때에도
Row Range Sharding보단Modifying Sharding을 권장한다.
좀더 효율적인 데이터 참조 튜닝을 위해 캐시 전략을 다양하게 설정할 수 있다.
그림처럼 3가지 캐시전략을 사용할 수 있다.
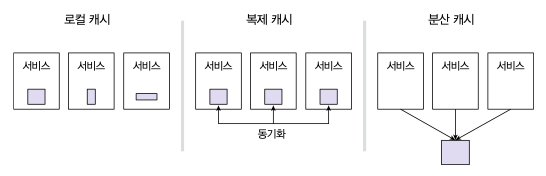
로컬캐시는 동기화가 되지 않아 동일한 종류의 WAS 노드에서 중복연산이 발생한다.
복제캐시는 중복연산은 발생하진 않지만 동기화, 스케일 아웃 사용 시 부하가 발생한다.
분산캐시는 외부에 있다보니 네트워크 비용이 발생하고 모든 부하를 캐시가 받는 SPoF 형식이다.
또한 로컬캐시와 복제캐시는 메모리 공간에 너무 많은 저장공간을 사용하게 될 경우 GC 에서 문제가 발생할 수 있다.
어떤 캐시전략을 사용하든 따라야하는 원칙이 있는데, 변경되지 않은 데이터를 업데이트를 위해 캐시에 덮어 씌우는 행위는 피해야 한다.
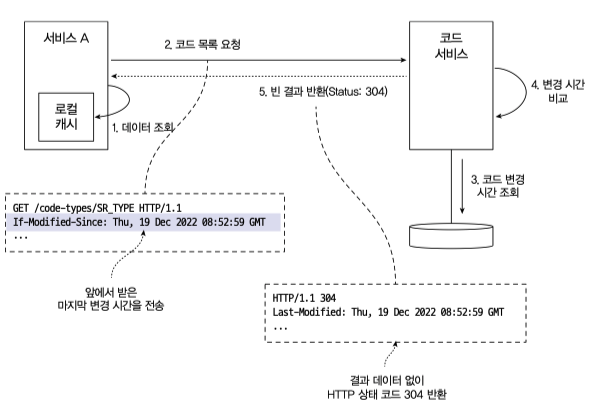
서비스간 데이터 수신을 통해 캐시를 업데이트 하는 방법을 사용중이라면 HTTP 캐시 프로토콜 을 사용해 캐시전략 원칙을 지킬 수 있다.
서비스A 가 코드정보 를 가져와 로컬캐시에 저장하기 위해 요청할 때 마지막 변경시간을 같이 전달한다.
데이터 제공자가 해당 마지막 변경시간 이후에 변경된 데이터가 없다면 HTTP Status 304 를 반환한다.
세션기반, 토큰기반
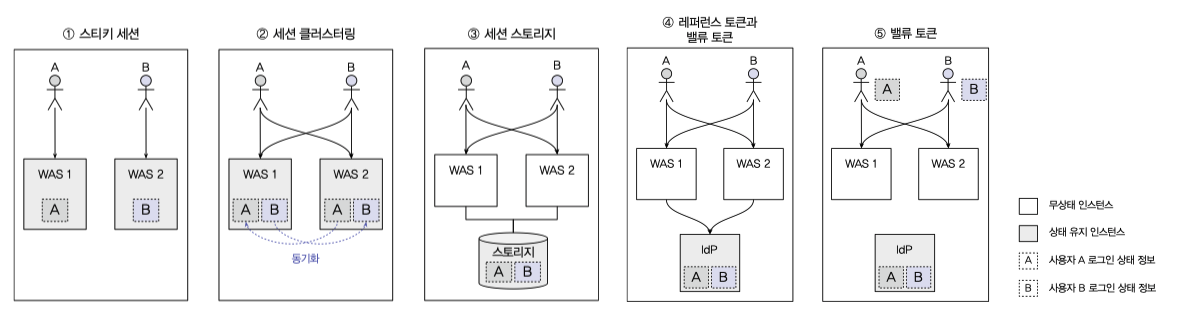
- 스키티 세션
WAS 별로 각자의 세션 공간에 로그인 정보를 저장한다. 사용자별로 WAS 를 지정해야 한다. - 세션 클러스터링
동기화를 통해 모든 WAS 가 동일한 세션정보를 가진다. EhCache 와 같은 기술을 사용해 구현 가능하다. - 세션 스토리지
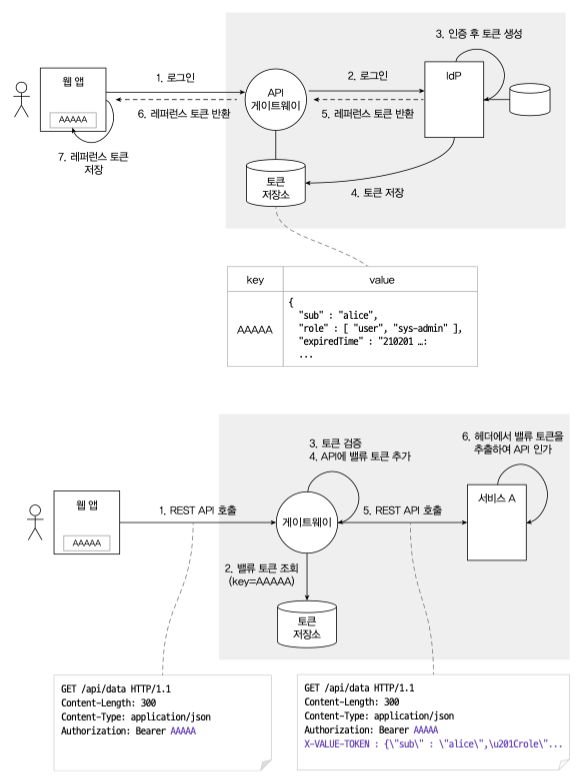
별도 외부공간에 로그인 상태정보를 저장한다. - 레퍼런스/벨류 토큰
레퍼런스 토큰은 벨류 토큰을 찾기위한 토큰,
벨류 토큰은 로그인 정보를 가지고 있는 토큰,
WAS 는 stateless 이지만IdP(Identity Provider)에 부하가 집중될 수 있다.
대신 마지막 사용시간에 의한 토큰 유효기간 연장, 강제 로그아웃 등과 같은 처리를 쉽게 할 수 있다. - 벨류 토큰
벨류 토큰만 취급, 발급한 토큰의 회수가 불가능해 강제 로그아웃 등이 불가능하다.
여기서 토큰은 JWT 와 같은 의미있는 토큰이 아닌 단순 랜덤 난수 토큰일 수 도 있다.
세션 스토리지, 레퍼런스/벨류 토큰 방식은 SPoF 방식으로 부하와 장애발생이 전체 시스템에 영향을 줄 수 있다.
확장성을 고려해서 각 서비스별 로컬캐시를 두어 IdP 의 부하를 줄이는 방법을 사용해야한다.
특히 레퍼런스/벨류 토큰 방식은 IdP 내의 벨류토큰을 비활성화 한다던지, 권한을 변경한다던지, 로컬캐시 토큰의 마지막 사용시간을 IdP 에 업데이트 해야 하는 등, 정보를 항상 동기화 시켜야 함으로 내부적으로 스케줄링 스레드를 이용해야한다.
레퍼런스/벨류 토큰 의 경우 게이트웨이에서 토큰을 검증하는 방식도 자주 쓰인다.
첫번째 그림은 API 게이트웨이 토큰저장소 에 key-value 형식으로 레퍼런스 토큰-벨류 토큰 을 저장하는 과정이다.
토큰저장소 로 Redis 를 주로 사용한다.
두번째 그림은 전달받은 레퍼런스 토큰 으로 API 를 호출하는 그림이다.
API 게이트웨이 만 통과했다면 그 이후로는 토큰의 권한 인가(role) 만 검증하면 된다.
API 게이트웨이 또한 SPoF 이긴 하지만, 애초부터 API 게이트웨이 가 SPoF 로 설계되었다.
요청이 늘어날경우 수평확장을 통해 모든 요청을 처리할 수 있도록 해야한다.
대부분 API 게이트웨이 는 HTTP 요청의 분배만 해줄뿐 인증/인가 기능은 지원하지 않는다.
위와 같은 환경을 구성하려면 커스텀한 API 게이트웨이 를 개발해야한다.
MSA 트랜잭션
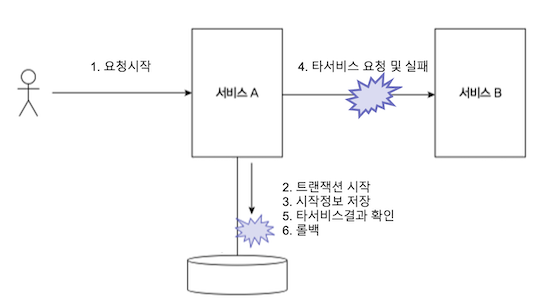
MSA 에선 ACID 트랜잭션이 보장되지 않는다.
물리적으로 분배되어 있는 DB 에 대해선 한번에 트랜잭션처리가 불가능하다 보니 원자성을 보장하지 않는다.
비지니스로직이 간단하다면 아래 그림과 같이 트랜잭션 사이에 타 서비스 요청 구문을 껴 넣어 ACID 보장을 처리할 수 도 있다.
비지니스로직이 복잡해 서비스들이 번갈아 가면서 DB에 데이터를 저장해야 할 경우 원자성을 유지하기 위해 보상트랜잭션을 위한 통신을 추가적으로 해야할 수 도 있다.
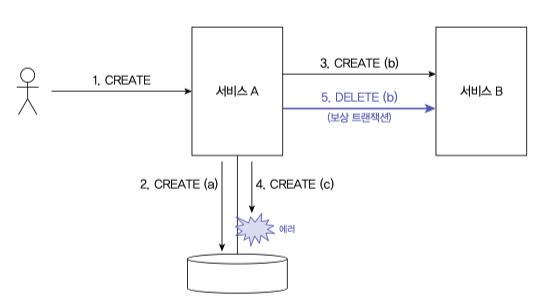
만약 보상트랜잭션 마저 실패하게 될 경우 데이터 일관성을 유지할 수 있는 방법이 없다.
관리자에게 알리기 위해 별도의 로깅, 알람 처리를 해야한다.
@Transactional
public void createCourse(CourseDto course) {
// 1 . 과정정보 생성
Course entity = courseMapper.toEntity(course);
entity = courseRepository.save(entity);
String courseId = entity.getId();
// 2 . [멤버서비스]에 생성자를 과정 담당자로 등록 w / courseId
memberGateway.addManager(courseId, loginUser);
//---- 여기까지는 에러가 발생하더라도 기존 트랜잭션 내부에서 일관성 유지 가능
// 3 . [게시판서비스]에 게시판 생성 w / courseId
try {
boardGateway.addBoard();
} catch (Exception originException) {
try {
// 보상 트랜잭션
memberGateway.removeManager(courseId, loginUser);
} catch (Exception compensationException) {
// TODO 관리자 로깅, 알람
log.error("COMPENSATION TRANSACTION ERROR! {}", compensationException);
}
throw originException;
}
}
비관적 락을 사용하면 예외가 바로바로 발생해서 즉시 MSA 트랜잭션을 처리하면 되지만
낙관적 락 의 경우 commit 시점에서
만약 낙관적 락 을 사용 중이라면 보상트랜잭션은 조금 더 불편해진다.
마지막 commit 과정에서 버전체크를 통해 성공/실패 여부를 경정하기 보상트랜잭션 위치를 아랫부분인 commit 위치에 작성해야 한다.
try {
// 낙관적 lock 커밋 실행
transactionManager.commit(txStatus);
} catch (Exception originalException) {
// 보상트랜잭션1
try {
boardGateway.removeBoard(courseId, loginUser);
} catch (RuntimeException compensationExcention) {
log.error("COMPENSATION TRANSACTION ERROR! {}",
compensationExcention);
}
// 보상트랜잭션2
try {
memberGateway.removeManager(courseId, loginUser);
} catch (RuntimeException compensationExcention1) {
log.error("COMPENSATION TRANSACTION ERROR! {}",
compensationExcention1);
}
// 보상트랜잭션3
try {
transactionManager.rollback(txStatus);
} catch (RuntimeException compensationExcention) {
log.error("COMPENSATION TRANSACTION ERROR! {}",
compensationExcention);
}
throw new RuntimeException("Failed to create a course",
originalException);
}
비관적 락 이 보다 깔끔한 보상트랜잭션 구문을 작성할 수 있지만,
낙관적 락 은 별도의 Write Lock 을 사용하지 않기 때문에 스레드 블록킹 시간을 줄일 수 있다.
스레드 블록킹은 MSA 구축시 특히 신경써야 할 자원이다.
보상트랜잭션이 불가능한 [SMS, Email, 메세징] 과 같은 작업은 가장 마지막으로 처리하는 것이 좋다.
MSA 를 구축하다보면 생각보다 데이터 응집도가 높아 보상트랜잭션 처리를 거의 하지 않는다.
서비스 설계시 의도적으로 응집도를 높여 보상트랜잭션이 일어나지 않도록 할 수 도 있다.
이벤트 기반 트랜잰셕
만약 클라이언트가 웹소켓이나 SSE 형식의 비동기 연결을 지원한다면,
REST API 대신 메세지 형식으로 트랜잭션처리를 대체가능하다.
이벤트 기반 트랜잭션은 처리하려면 전반적으로 복잡하다.
보상트랜잭션을 위한 메세지와 페이로드가 REST API 에 비해 많다.
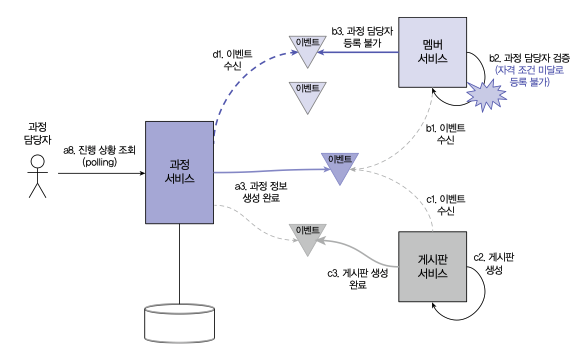
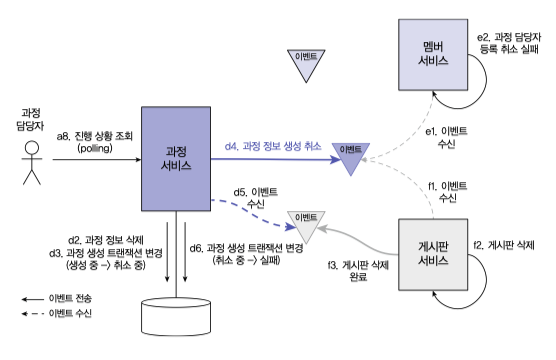
그림처럼 과정 정보 와 연관된 멤버, 게시판 서비스가 정상적으로 동작할 경우 이벤트 송신과 수신을 조합하여 과정 상태값을 완료로 처리하여 트랜잭션처리를 할 수 있다.
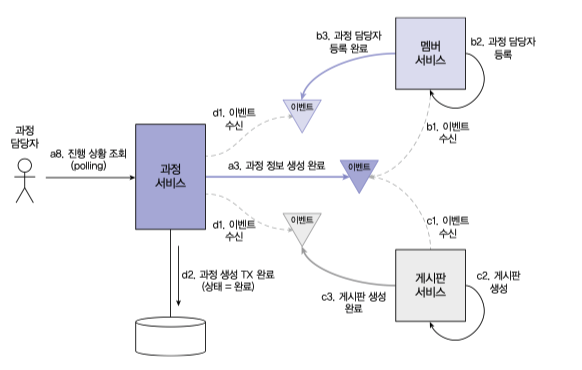
만약 특정 서비스에서 해당 트랜잭션이 실패할 경우 상위 서비스에게 실패 이벤트를 전달하고 보상트랜잭션으로 이어지도록 해야한다.
데이터 일관성
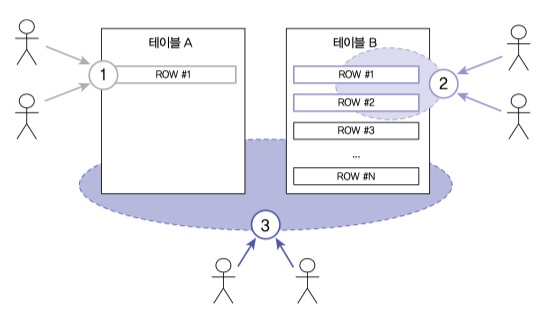
2개의 서비스의 DB을 변경할 때, 제3자가 두 서비스로부터 조회쿼리를 날릴 경우 일관성이 보장되지 않는다.
3번 요청에서 테이블A 의 데이터가 없을수도 있고 테이블B 의 데이터가 없을수도 있다.
즉 서비스간의 Dirty Read 가 발생하는 것이다.
대부분의 시스템에서 일시적인 오차 정도는 큰 문제가 되지 않는다.
하지만 결산 시스템같이 해당 시점의 정확한 데이터를 필요로 하는 서비스라면 위와 같은 관측 불일치가 발생하면 안된다.
일관성을 꼭 유지해야하는 데이터라면 응집도를 높여 하나의 서비스로 관리하던가,
시간 데이터와 같은 값을 사용해 관측 불일치가 발생하지 않도록 비즈니스 로직을 구성해야 한다.
(10분 전 구매까지만 결산처리하는 등)
MSA 용어
CBD/SOA
기능별 모듈화를 통해 컴포넌트를 생성, 컴포넌트들을 보다 의미있는 서비스 지향 아키텍처 로 발전시키는 방식을 CBD/SOA(Component Based Development/Service Oriented Architecture) 라 한다.
MSA 와 개발이념은 같으며 클라우드 플랫폼에서 해당 이념을 구축하고 성공사례로 공유한 것이 MSA 이다.
물리적인 인프라 차이도 약간 있는데, CBD/SOA 는 물리적으로 DB 분리하지 않으나 MSA 의 경우 DB 까지 나눌 수 있다.
API 호출을 통해서만 다른 Service 의 데이터에 접근할 수 있도록 결합도를 낮추고 모듈화를 강화시켰다.
CRDT
CRDT(Conflict-free Replicated Data Types: 충돌없는 복제 데이터 타입)
마이크로 서비스라 할지라도 기능이 추가되면 다뤄야하는 데이터도 추가된다.
트랜잭션의 일관성을 유지하기 힘들어지면서 확장성이 나빠진다.
데이터 분권화
과거 DB 모델링시 중복없는 정규화 과정을 꼭 거쳤지만 스토리지와 네트워크 대역폭 상승으로 정규화를 진행하지 않는 방식도 사용중이다.
폴리글랏 환경에서 일부 데이터의 중복과 복제는 허용한다.
어느정도 일관성 처리를 하기는 한다. two phase commit, 비동기 이벤트 처리 등
two phase commit 경우 서비스간 결합도가 상승하기에 주로 비동기 이벤트 처리를 사용함
위와 같은 방식을 사용하면 특징 시점에 데이터 일관성이 일그러지는 상황이 한번이상 분명히 오지만 카프카와 같은 강력한 메세지 큐 시스템을 통해 MSA 환경에선 어느정도 허용하는 편
리액티브
백, 프론트, 앱, IoT 등 현대 어플리케이션이 가춰야할 필수 요소가 Reactive 이며 아래 4요소를 가진다.
응답성(Responsive) - 신뢰성있는 응답
탄력성(Resilient) - 장애전파 x, 빠르게 복구
유연성(Elastic) - 사용량 변화에 맞춰 자원 확장
메세지기반(Message Driven) - 비동기 기반, 느슨한 결합
리액티브 완경을 구성하려면 [IaaS, PaaS, SaaS] 개념을 사용해서 서비스를 배포해야한다.
Infrastructure as a Service - 인프라를 가상으로 제공
Platform as a Service - 인프라 + 개발환경(platform) 까지 가상으로 제공
Software as a Service - 인프라 + 개발환경 + 어플리케이션(software) 까지 가상으로 제공
베어메탈(물리적 서버)에 직접 PaaS 혹은 Saas 를 구축해도 되지만 리액티브의 유연성 요소를 포기하게 된다.