Spring Boot - DynamoDB!
Spring with DynamoDB
DynamoDB 의 가장 큰 단점은 다른 DB 밴더보다 유용한 라이브러리가 적다는 것.
다행이 Spring Boot 에선 DynamoDB 사용을 위한 SDK, 그리고 해당 SDK 를 보다 쉽게 사용할 수 있도록 비공식 라이브러리인 Spring Data DynamoDB 를 사용할 수 있다.
# local 에서 DynamoDB 를 실행
docker run -d -p 8000:8000 amazon/dynamodb-local
# application.properties
spring.data.dynamodb.entity2ddl.auto=create-only
// @Bean
// public AWSCredentialsProvider awsCredentialsProvider() {
// return new DefaultAWSCredentialsProviderChain();
// }
// local-dynamodb 사용을 위한 설정
@Bean(name = "amazonDynamoDB")
public AmazonDynamoDB amazonDynamoDb(AWSCredentialsProvider awsCredentialsProvider) {
AmazonDynamoDB amazonDynamoDb = AmazonDynamoDBClientBuilder.standard()
.withCredentials(awsCredentialsProvider)
.withEndpointConfiguration(new AwsClientBuilder.EndpointConfiguration("http://localhost:8000", "ap-northeast-2"))
.build();
return amazonDynamoDb;
}
DynamoDB 테이블 설정을 위한 주석은 아래 url 을 참조
가장 중요한건 DynamoDBIndexHashKey, DynamoDBIndexRangeKey 어노테이션일 것인데
각각 보조 인덱스를 만들기 위한 파티션키와 정렬키를 설정하는 어노테이션이다.
해당 어노테이션이 설정된 후 findBy... 과 같은 함수로 호출시 자동으로 인덱스를 찾아 객체를 매핑한다.
트랜잭션
DynamoDB 에서는 트랜잭션 기능을 제공하지만 안타깝게도 Srping Data DynamoDB 프로젝트에서 @Transaction 어노테이션은 작동하지 않는다.
Srping Data DynamoDB 라이브러리 또한 DynamoDBMapper 라는 내부 매퍼 클래스를 구현하여 작성한 라이브러리, DynamoDBMapper 의 자세한 내용은 아래 url 참고
https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/DynamoDBMapper.Methods.html https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/DynamoDBMapper.Transactions.html
위 url 에 작성된 데모코드와 같이 DynamoDBMapper 을 사용하면 트랜잭션 기능을 사용할 수 있기는 하다.
TransactionLoadRequest 를 작성하고 아래와 같이 매퍼에 전달하면 된다.
loadedObjects = mapper.transactionLoad(transactionLoadRequest);
DyanamoDB Java Client
https://docs.aws.amazon.com/ko_kr/sdk-for-java/latest/developer-guide/java_ec2_code_examples.html
비공식 Spring Data DyanamoDB 를 사용하기보다 AWS 에서 제공하는 DyanamoDB Java Client 라이브러리를 사용하는것도 좋은 방법이다.
또한 Dynamic Query 지원을 위해서는 AWS 에서 제공하는 DyanamoDB Java Client 의 DynamoDBMapper 의 scan, query 기능을 사용할 수 밖에 없다.
DynamoDB scan vs query: https://dynobase.dev/dynamodb-scan-vs-query/
scan,query모두 테이블에서 컬렉션을 읽어오기 위한 메서드이지만,query가파티션 키를 사용하기 때문에 성능이 더 뛰어나며 문서 역시query메서드 사용을 권장한다.
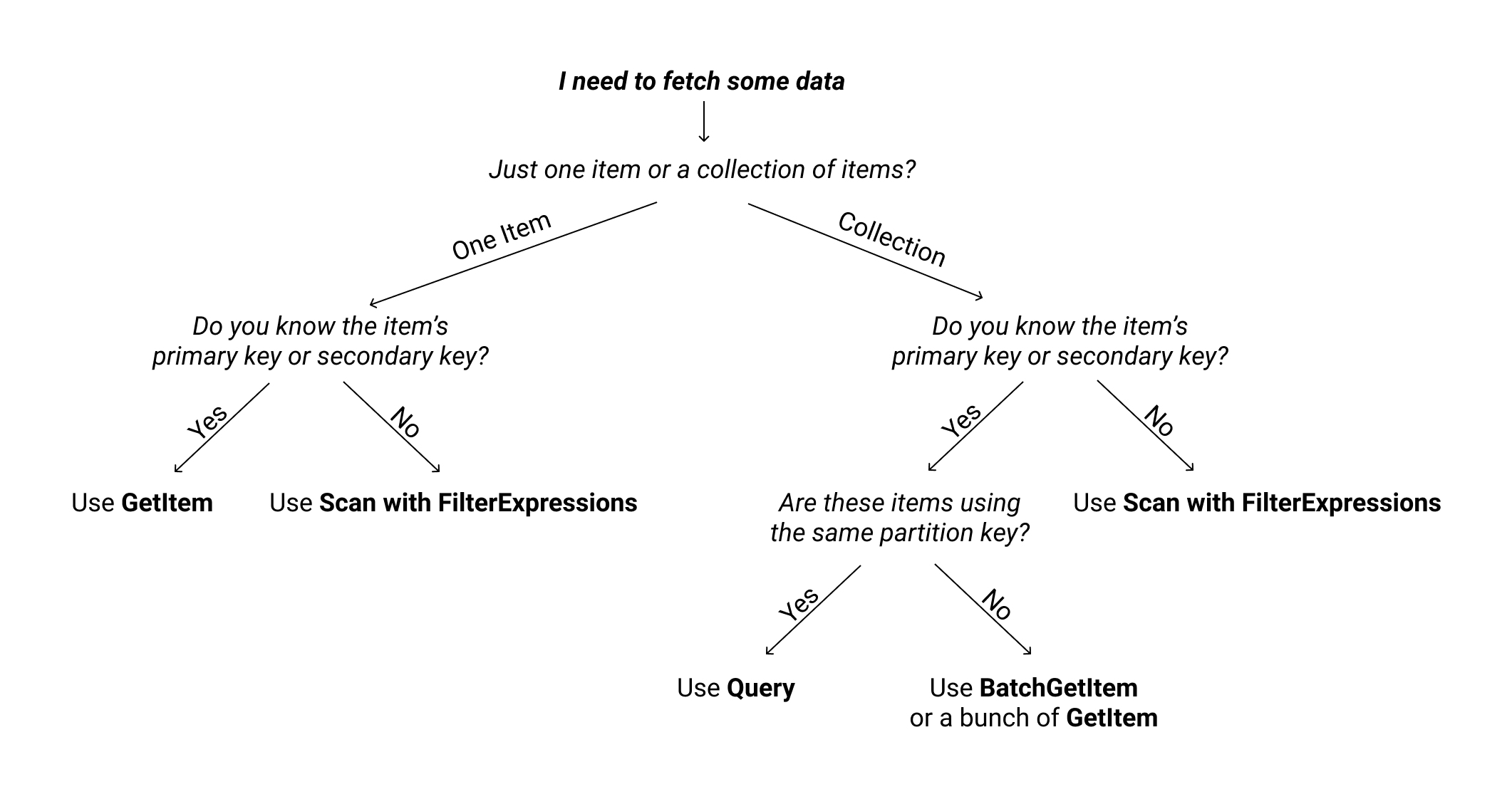
일단 아래처럼 Filter Condition 을 생성하는 코드를 작성할 수 있다.
private Map<String, Condition> generateFilter(GetCustomerRequestDto requestDto) {
Map<String, Condition> filter = new HashMap<>();
if (StringUtils.hasLength(requestDto.getName())) {
filter.put("name", new Condition()
.withComparisonOperator(ComparisonOperator.CONTAINS)
.withAttributeValueList(new AttributeValue(requestDto.getName())));
}
if (StringUtils.hasLength(requestDto.getType())) {
CustomerType type = CustomerType.forValue(requestDto.getType());
if (type != null) {
filter.put("type", new Condition()
.withComparisonOperator(ComparisonOperator.EQ)
.withAttributeValueList(new AttributeValue()));
}
}
if (requestDto.getBeginDate() != null && requestDto.getEndingDate() != null) {
if (requestDto.getEndingDate().isBefore(requestDto.getBeginDate())) {
throw new IllegalArgumentException("being date is after then ending date");
}
filter.put("create", new Condition()
.withComparisonOperator(ComparisonOperator.BETWEEN)
.withAttributeValueList(
new AttributeValue(CustomTimeUtil.getUTCString(requestDto.getBeginDate())),
new AttributeValue(CustomTimeUtil.getUTCString(requestDto.getEndingDate()))
// zone date time to UTC Time String
)
);
}
return filter;
}
타입에 따라 사용할 수 있는 ComparisonOperator 가 있으며 자세한 사항은 공식 문서 확인
https://docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_Condition.html
위의 경우 name, type, create 필드에 따라 dynamic 하게 쿼리를 생성할 수 있도록 설정하였다.
public List<Customer> findAllByUmidAndContractCdAndPortNo(String group, GetCustomerRequestDto requestDto) {
Customer forHash = new Customer();
forHash.setGroup(group);
Map<String, Condition> queryFilter = generateFilter(requestDto);
DynamoDBQueryExpression expression = new DynamoDBQueryExpression()
.withHashKeyValues(forHash)
.withConsistentRead(false)
.withQueryFilter(queryFilter);
return dynamoDBMapper.query(Customer.class, expression);
}
Customer 객체의 경우 group 문자열 필드를 GSI 로 설정하여 HashKeyValue 데이터로 사용하였다.
GSI 를 사용하다 보니 일관적인 읽기지원이 불가능함으로 withConsistentRead(false) 를 설정해주어야 한다.
scan 의 경우 아래처럼 진행해야 하는데 id 리스트를 기반으로 검색을 진행하려면 어쩔수 없이 scan 요청을 해야한다.
public List<Customer> findAllByIdIn(List<String> customerIds, GetCustomerRequestDto requestDto) {
Map<String, Condition> scanFilter = generateFilter(requestDto);
List<AttributeValue> attList = customerIds.stream().map(id -> new AttributeValue(id)).collect(Collectors.toList());
scanFilter.put("id", new Condition()
.withComparisonOperator(ComparisonOperator.IN)
.withAttributeValueList(attList));
DynamoDBScanExpression expression = new DynamoDBScanExpression()
.withScanFilter(scanFilter);
return dynamoDBMapper.scan(Customer.class, expression);
}
RCU 를 낮추기 위해 HashKey 를 사용하는데, 아쉽게도 동시에 여러개의 HashKey 를 사용하여 쿼리하는 것은 불가능하다.
queryFilter 를 사용해 전체읽기를 사용하거나, 두번 읽은다음 어플리케이션 레이어에서 조인해야한다.
여담
테이블 생성시 LSI 을 생성하려면 RangeKey 를 설정해야 한다.
그런데 이 RangeKey 를 Spring Data DynamoDB 와 같이 사용하기가 쉽지 않다.
Spring Data DynamoDB 에서 제공하는 Repository 객체들이 RangeKey 와 HashKey 중 어떤 값을 키값(Id)로 설정해야 하는지 혼동되어 아래와 같은 에러가 발생한다.
no field or method annotated with interface org.springframework.data.annotation.id found
그렇다고 @Id 어노테이션을 추가하면 아래 에러가 발생하게 되는데
No method or field annotated by @DynamoDBHashKey within type java.lang.String!
모두 Repository 인터페이스에서 제공하는 에러들이다.
RangeKey 를 써야한다면 Repository 객체를 사용하지 않고 DynamoDBMapper 를 이용해 쿼리를 작성하면 된다.
혹은 Spring Data DynamoDB 에서 제공하는 Custom Key Class 를 별도로 작성하면 된다.
https://github.com/derjust/spring-data-dynamodb/wiki/Use-Hash-Range-keys
DynamoDBMapper만을 사용하는것을 추천
만약 두개의 칼럼을 기반으로 필터링해야할 경우 칼럼1#칼럼2 형태로 2개의 칼럼을 하나의 칼럼에 우겨넣어 LSI 로 설정해야 한다.
DynamoDB 는 단순한 CRUD 에선 최적이라할 수 있지만 복잡한 쿼리식은 아예 설계불가능할 수 있기에 충분한 요구분석후에 사용을 결정해야 한다.
데모코드
https://github.com/Kouzie/spring-boot-demo/tree/main/dynamodb-demo