Spring Boot - JPA!
JPA(Java Persisitence API)
참고
https://docs.jboss.org/hibernate/orm/current/userguide/html_single/Hibernate_User_Guide.html https://www.datanucleus.org/products/accessplatform/index.html https://www.datanucleus.org/products/accessplatform/jpa/annotations.html
데이터를 유지하고 관리하기위해 DB를 사용하고 java프로그램에서 DB와 연동하는 JDBC를 사용하였다.
일반적으로 DB 연동시 데이터베이스의 종속적인 클래스를 정의하는 코딩을 하는데
(테이블에 해당하는 vo객체를 정의하고 매핑)
반대로 정의한 클래스에 코드에 종속적인 ORM(Object Relation Mapping) 시스템이 있다.
JPA는 java 진영에서 ORM 시스템을 구축하기위한 표준 라이브러리
여러 기업에서 JPA를 구현한 라이브러리를 제공하는데 Hibernate가 가장 유명하다.
(이외에도
EclipseLink,DataNuclues등이 있음)
Spring Data JPA, JPA, Hibernate
3가지 라이브러리 사용시 쉽게 혼동할 만한 내용을 잘 정리해둔 블로그
출처: https://suhwan.dev/2019/02/24/jpa-vs-hibernate-vs-spring-data-jpa
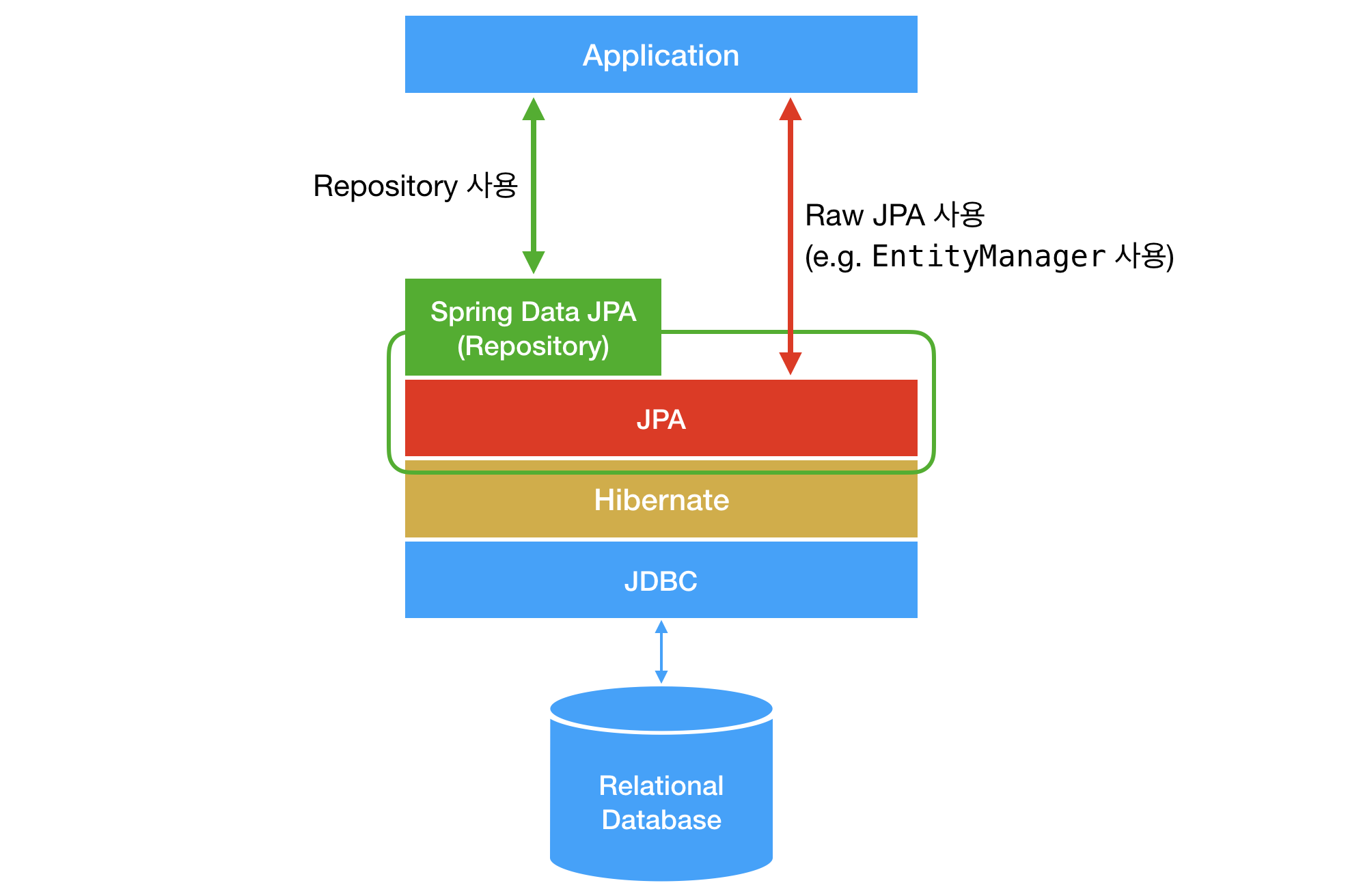
JPA 의 구현체가 Hibernate 임으로 동일선상에 있거나 위치가 변경되어도 무방
DIP 에 익숙해진 사용자를 위해 위 그림처럼 표현한듯
Spring 사용시 단순 Hibernate를 사용해 개발할 일이 거의 없다.
대부분 Hibernate 를 덮어씌운 Spring Data JPA 를 사용하며 특수한 경우에만 Hibernate 전용 함수를 사용한다.
Spring 이 아닌 다른 java 기반 프레임워크로 개발한다면
Hibernate를 사용해 개발해야 할것
엔티티 매니저
Hibernate에서 여러 엔티티를 관리하는 객체
Spring Data JPA 를 사용하면 엔티티 매니저를 직접적으로 사용할 일은 없지만
Spring Data JPA 내부적으로 Hibernate 규약과 엔티티 매니저를 통해 데이터를 관리하기에 알아두어야함
엔티티는 DB 테이블을 만들기위한 객체로 만든 테이블 명세서(클래스) 혹은 생성된 객체(인스턴스), 둘다 혼용하여 말함
Spring 에서 지원하는 기능으로 엔티티와 DB가 연동되어 데이터를 가져오고 수정되고 저장되고 삭제되는 과정을 담당하는 객체이다.
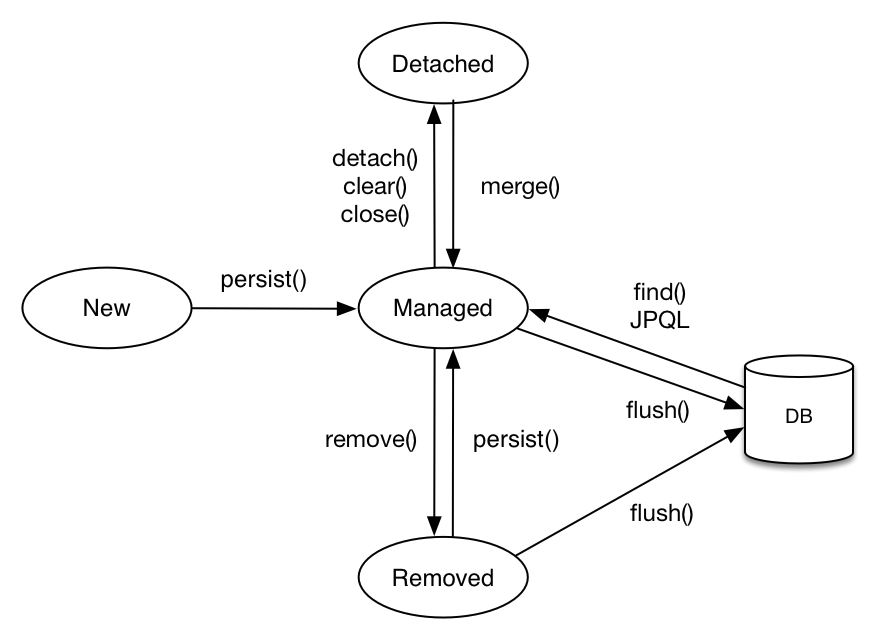
엔티티 매니저가 위 사진에 있는 여러 기능을 호출하면서 엔티티와 DB 간 CRUD를 처리한다.
New: 실제 DB와 연동되지 않은 새로 생성된 엔티티
Managed(영속): 엔티티의 정보가 DB에 저장되어있고 메모리도 이와 같은 상태로 존재하는 상태(실제 데이터와 메모리상의 테이터가 일치), 이 공간은 영속 컨텍스트라 한다.
Detached(준영속): 영속 컨텍스트에서 엔티티를 꺼내와 각종 CRUD를 사용하는 상태, 아직 DB와는 연동되지 않아 같은상태로 존재하지 않는다.
준영속 상태에 있는 객체들은 1차 캐시에서 검색되지도 않는다.
merge 메서드는 1차캐시 혹은 DB 에서 다시 엔티티를 검색 한 후 준영속 엔티티의 정보로 채워넣는 과정이다.
Removed: 더이상 사용하지 않아 삭제되고 영속 컨텍스트에서도 쫓겨난 상태
위의 각 상태에서 실제 DB에서 데이터를 검색, 연동, 수정/삭제 작업을 하기위해 수많은 메서드를 호출하는 것이 사진에 보인다.
Spring Data JPA 에선 어노테이션 몇개로 웬만한 작업은 처리 가능하다.
JPA Query
JPA 에서 각종 SQL 쿼리들을 어떻게 생성하는지 알아본다.
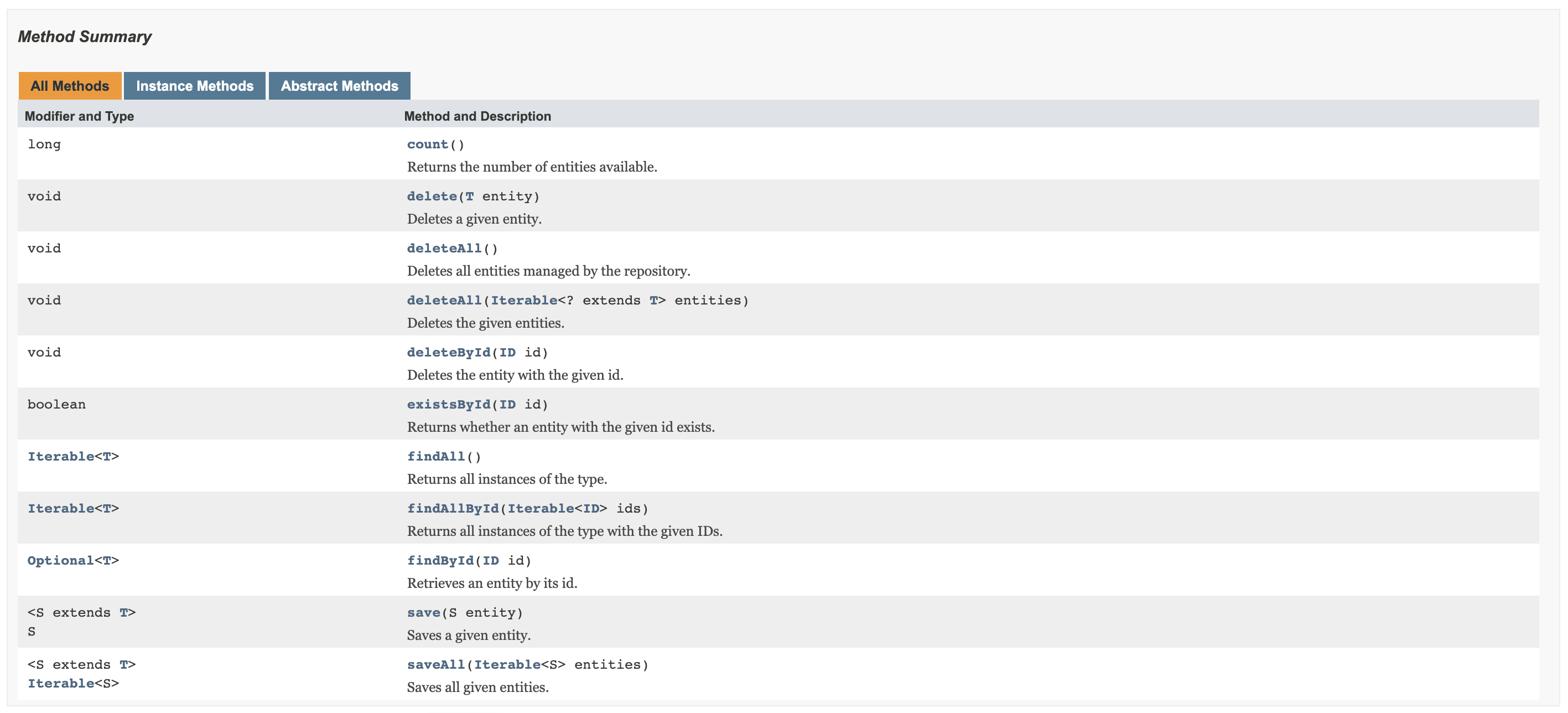
CrudRepository
각종 Spring Data 프로젝트들은(redis, jdbc, mongo 등) 이 Repository 패턴을 사용한다
Spring Data JPA 에서는 CrudRepository 를 주로 사용
아래와 같이 엔티티를 정의하고 CRUD 작업을 처리할 Repository 인터페이스를 정의하는 패턴을 가진다.
@Getter
@Setter
@ToString
@Entity
@Table(name="tbl_boards")
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long bno;
private String title;
private String writer;
private String content;
@CreationTimestamp
private Timestamp regdate;
@UpdateTimestamp
private Timestamp updatedate;
}
public interface BoardRepository extends CrudRepository<Board, Long> {
}
CrudRepository에는 기본적인CRUD를 위한 가상메서드가 정의되어 있다.
save메서드를 통해update,insert가 가능하다.
Spring Data JPA 가 DB 에 맞춰 알맞은 쿼리를 정의한 구현체를 동적으로 생성해준다.
간단한 CRUD 작업은 CrudRepository
각종 조건문이 들어간 복잡한 쿼리는 JPA Query Methods 로 수행한다
find..by..
read..by..
query..by..
get..by..
count..by..
위와같은 패턴으로 JPA가 자동으로 만들어주는 쿼리메서드를 사용해 여러가지 조건문을 추가한다.
JPA는 refelection 이 극한까지 사용된 프로젝트 라 할 수 있다.
참고: https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#jpa.query-methods.query-creation
Keyword |
Sample |
JPQL snippet |
|---|---|---|
And |
findByLastnameAndFirstname |
… where x.lastname = ?1 and x.firstname = ?2 |
Or |
findByLastnameOrFirstname |
… where x.lastname = ?1 or x.firstname = ?2 |
Is,Equals |
findByFirstname,findByFirstnameIs,findByFirstnameEquals |
… where x.firstname = ?1 |
Between |
findByStartDateBetween |
… where x.startDate between ?1 and ?2 |
LessThan |
findByAgeLessThan |
… where x.age < ?1 |
LessThanEqual |
findByAgeLessThanEqual |
… where x.age <= ?1 |
GreaterThan |
findByAgeGreaterThan |
… where x.age > ?1 |
GreaterThanEqual |
findByAgeGreaterThanEqual |
… where x.age >= ?1 |
After |
findByStartDateAfter |
… where x.startDate > ?1 |
Before |
findByStartDateBefore |
… where x.startDate < ?1 |
IsNull |
findByAgeIsNull |
… where x.age is null |
IsNotNull,NotNull |
findByAge(Is)NotNull |
… where x.age not null |
Like |
findByFirstnameLike |
… where x.firstname like ?1 |
NotLike |
findByFirstnameNotLike |
… where x.firstname not like ?1 |
StartingWith |
findByFirstnameStartingWith |
… where x.firstname like ?1 (parameter bound with appended %) |
EndingWith |
findByFirstnameEndingWith |
… where x.firstname like ?1 (parameter bound with prepended %) |
Containing |
findByFirstnameContaining |
… where x.firstname like ?1 (parameter bound wrapped in %) |
OrderBy |
findByAgeOrderByLastnameDesc |
… where x.age = ?1 order by x.lastname desc |
Not |
findByLastnameNot |
… where x.lastname <> ?1 |
In |
findByAgeIn(Collection<Age> ages) |
… where x.age in ?1 |
NotIn |
findByAgeNotIn(Collection<Age> ages) |
… where x.age not in ?1 |
True |
findByActiveTrue() |
… where x.active = true |
False |
findByActiveFalse() |
… where x.active = false |
IgnoreCase |
findByFirstnameIgnoreCase |
… where UPPER(x.firstame) = UPPER(?1) |
페이징 처리, 정렬 처리 - Pageable, Sort
페이징 처리시 위의 CrudRepository 와 쿼리메서드에 org.springframework.data.domain.Pageable 클래스를 사용 가능하다.
위의 쿼리메서드 마지막필드에 Pageable 객체를 추가한다.
public interface BoardRepository extends CrudRepository<Board, Long> {
//bno를 기준으로 내림차순 정렬 - bno > ? ORDER BY bno & paging
List<Board> findByBnoGreaterThanOrderByBnoDesc(Long bno, Pageable paging);
}
Pageable객체는 PageRequest.of() 메서드의 2가지 방법으로 생성 가능
PageRequest.of(int page, int size)
PageRequest.of(int page, int size, Sort.Direction direction, String ..props)
Pageable paging1 = PageRequest.of(0, 10);
List<Board> list1 = repo.findByBnoGreaterThanOrderByBnoDesc(0L, paging1);
list1.forEach(board->{
System.out.println(board);
});
Pageable paging2 = PageRequest.of(0, 10, Sort.Direction.DESC, "bno");
List<Board> list2 = repo.findByBnoGreaterThan(0L, paging2);
list2.forEach(board->{
System.out.println(board);
});
쿼리메서드를 통해서 정렬할 수 있고 Pageable를 사용해서 쿼리메서드에 정렬기능을 추가할 수 도 있다.
페이징에서 정렬은 필수이니 어떤 방식을 사용하건 정렬기능을 추가해야한다.
thymleaf 와 같이 HTML템플릿 까지 지원하는 경우
서버에서 페이징 처리까지 모두 해주는 Page 클래스를 사용하면 템플릿 뷰에서 페이지를 출력하기 편하다.
| 메서드 | 설명 |
|---|---|
int getNumber(); |
현제 페이지 넘버 |
int getSize(); |
한 페이지 출력 데이터 크기 |
int getTotalPages(); |
총 페이지 수 |
int getNumberOfElements(); |
실제 페이지에 출력할 데이터 수 |
long getTotalElements(); |
총 데이터 수 |
boolean hasPreviousPage(); |
이전페이지 유무 |
boolean hasNextPage(); |
이후페이지 유무 |
boolean isFirst(); |
현제 페이지 첫 페이지인지 |
boolean isLast(); |
현제 페이지가 마지막 페이지인지 |
Pageable previousPageable |
이전 페이지 객체 |
Pageable nextPageable(); |
다음 페이지 객체 |
List<T> getContent(); |
조회된 데이터 리스트 |
boolean hasContent(); |
결과 데이터 존재 유무 |
Sort getSort(); |
검색시 사용된 sort정보 |
반환값을 List<Board> 에서 아래처럼 Page<Board> 로 변경
Pageable paging = PageRequest.of(0, 10, Sort.Direction.DESC, "bno");
Page<Board> result = repo.findByBnoGreaterThan(0L, paging);
result.forEach(board->{
System.out.println(board);
});
System.out.println("-------------------------------------------");
System.out.println("result.getTotalElements(): " + result.getTotalElements());
System.out.println("result.getTotalPages(): " + result.getTotalPages());
System.out.println("result.getContent(): " + result.getContent());
System.out.println("result.getNumber(): " + result.getNumber());
System.out.println("result.getNumberOfElements(): " + result.getNumberOfElements());
System.out.println("result.getPageable(): " + result.getPageable());
System.out.println("result.getSize(): " + result.getSize());
System.out.println("result.getSort(): " + result.getSort());
System.out.println("result.get(): " + result.get());
System.out.println("result.hasContent(): " + result.hasContent());
System.out.println("result.isLast(): " + result.isLast());
System.out.println("result.isFirst(): " + result.isFirst());
System.out.println("result.hasNext(): " + result.hasNext());
System.out.println("result.hasPrevious(): " + result.hasPrevious());
System.out.println("result.nextPageable(): " + result.nextPageable());
System.out.println("result.previousPageable(): " + result.previousPageable());
Hibernate: select board0_.bno as bno1_0_, board0_.content as content2_0_, board0_.regdate as regdate3_0_, board0_.title as title4_0_, board0_.updatedate as updateda5_0_, board0_.writer as writer6_0_ from tbl_boards board0_ where board0_.bno>? order by board0_.bno desc limit ?
Hibernate: select count(board0_.bno) as col_0_0_ from tbl_boards board0_ where board0_.bno>?
Board(bno=200, title=제목...199, writer=user09, content=내용...199채우기, regdate=2019-08-08 17:01:36.0, updatedate=2019-08-08 17:01:36.0)
...
...
Board(bno=191, title=제목...190, writer=user00, content=내용...190채우기, regdate=2019-08-08 17:01:36.0, updatedate=2019-08-08 17:01:36.0)
-------------------------------------------
result.getTotalElements(): 199
result.getTotalPages(): 20
result.getContent(): [생략...]
result.getNumber(): 0
result.getNumberOfElements(): 10
result.getPageable(): Page request [number: 0, size 10, sort: bno: DESC]
result.getSize(): 10
result.getSort(): bno: DESC
result.get(): java.util.stream.ReferencePipeline$Head@1cc9bd9b
result.hasContent(): true
result.isLast(): false
result.isFirst(): true
result.hasNext(): true
result.hasPrevious(): false
result.nextPageable(): Page request [number: 1, size 10, sort: bno: DESC]
result.previousPageable(): INSTANCE
Iterable 구현 객체가 반환되며 여러가지 편리한 함수들도 포함되어 있다.
알아서 Count까지 해서 Page 객체에 데이터를 넣어준다.
편리한 만큼 오버헤드가 발생하여 REST 환경에선 잘 사용하지 않음
JPQL
복잡한 구조 (각종 join, 여러 조건문 등) 을 가질 경우 자동생성되는 쿼리메서드로는 한계가 있다.
@Query어노테이션을 사용하면 각종 요청에 대처가능하다.
JPQL: 유사 SQL 문법으로 DB 종속을 피하면서 익숙한 쿼리문 작성이 가능.
@Query("SELECT b FROM Board b WHERE b.title LIKE %?1% AND b.bno > 0 ORDER BY b.bno DESC")
public List<Board> findByTitle(String title);
@Query("SELECT b FROM Board b WHERE b.content LIKE %:content% AND b.bno > 0 ORDER BY b.bno DESC")
public List<Board> findByContent(@Param("content") String content);
?1을 통해 첫번째 매개변수를 지정해 동적으로 검색조건을 변경 가능하고 @Param을 사용하면 변수 이름으로 지정가능하다.
@Query("SELECT b FROM #{#entityName} b WHERE b.content LIKE %:content% AND b.bno > 0 ORDER BY b.bno DESC")
public List<Board> findByContent(@Param("content") String content);
#{#entityName}을 사용하면 혹시라도 테이블을 참조할 객체명이 변경되어도 대처가능하다.
@Query("SELECT b FROM #{#entityName} b WHERE b.content LIKE %:content% AND b.bno > 0 ORDER BY b.bno DESC")
public List<Board> findByContent(@Param("content") String content, Pageable paging);
페이징의 경우 @Query 어노테이션 상관 없이 페이징 처리 가능하다.
@Query(value = "SELECT b FROM tbl_board b WHERE b.content LIKE %:content% AND b.bno > 0 ORDER BY b.bno DESC"
nativeQuery=true)
public List<Board> findByContent(@Param("content") String content);
nativeQuery 속성을 사용하면 지정한 DB고유 문법을 사용할 수 있다.
단 JPA의 장점인 DB 독립성은 사용할 수 없게된다.
public interface PDSBoardRepository extends CrudRepository<PDSBoard, Long> {
@Modifying
@Transactional
@Query("UPDATE PDSFile f SET f.pdsfile = ?2 WHERE f.fno = ?1")
public int updatePDSFile(Long fno, String newFileName);
}
@Query는 기본적으로 SELECT구문만을 지원하지만 @Modifying 어노테이션으로 UPDATE, DELETE구현이 가능하다.
@Modifying 으로 변경된 값은 자동으로 영속성에 업데이트 된 정보가 들어가지 않는다.
아래 옵션으로 쿼리 실행후 영속성을 비우거나 쿼리 실행전 flush 작업을 진행할 수 있다.
flushAutomatically: 쿼리 실행 전 쓰기 지연 저장소의 쿼리를 flush 하는 옵션clearAutomatically: 쿼리 실행 후 영속성 컨텍스트를 비우는 옵션
JPA Custom DTO
엔티티 클래스가 아닌 직접 정의한 클래스에에 DB에서 읽어온 값을 삽입, 반환하고 싶다면 아래코드 참고
@Getter
@Setter
@AllArgsConstructor
public class SurveyAnswerStatistics {
private String answer;
private Long cnt;
}
...
...
public interface SurveyRepository extends CrudRepository<Survey, Long> {
@Query( "SELECT new com.path.to.SurveyAnswerStatistics(v.answer, COUNT(v)) " +
"FROM Survey v " +
"GROUP BY v.answer")
List<SurveyAnswerStatistics> findSurveyCount();
}
클래스 풀 네임을 사용해 반환할 수 있다.
nativeQuery 를 사용해야 한다면 아래처럼 적용 가능, 단 getter, setter 메서드를 모두 정의해주어야 한다.
public interface SurveyRepository extends CrudRepository<Survey, Long> {
@Query(value =
"SELECT v.answer AS answer, COUNT(v) AS cnt " +
"FROM Survey v " +
"GROUP BY v.answer", nativeQuery = true)
List<SurveyAnswerStatistics> findSurveyCount();
}
1차 캐시, 2차 캐시
-
1차 캐시(First Level Cache, L1 Cache)
트랜잭션 단위에서 공유하는 캐시, 영속성 컨텍스트 내부에 존재하여 엔티티 매니저로 조회하는 모든 엔티티는 1차캐시에서 값을 확인하고 가져온다.
영속성 컨택스트는 JPA 를 사용한다면 자동으로 설정된다. -
2차 캐시(Second Level Cache, L2 Cache)
어플리케이션 단위에서 공유하는 캐시, 애플리케이션을 종료할 때까지 유지된다.
대부분 API 단의 캐시(Redis, EhCache 등) 을 사용하고 hibernate 의 2차캐시는 사용하지 않는다.
hibernate 에서 2차 캐시 연동을 위한 설정을 제공, 아래 url 과 @javax.persistence.Cacheable, @org.hibernate.annotations.Cache 설정을 통해 각종 추가설정이 가능하다.
https://docs.jboss.org/hibernate/orm/6.2/userguide/html_single/Hibernate_User_Guide.html#caching
영속성 concurrency
멀티 스레드 환경에서 JPA를 사용하다 보면 1차 캐시(영속성 컨택스트)의 동시성 문제가 발생한다.
Thread1이DeviceRestartLog생성Thread.sleep으로 5초 후 DB에서findByLogid실행하여 재실행결과 확인Thread2는Device로부터 재실행 결과 수신, 재실행 결과 로그를DeviceRestartLog에 업데이트
// Thread2의 코드, 기기 재부팅 메세지 수신시 동작
Integer status = message.getStatus(); // 기기 재부팅 결과
Long logid = message.getLogid(); // 기기 재부팅 로그아이디
DeviceRestartLog deviceRestartLog = deviceRestartLogRepository.findByLogId(logid);
deviceRestartLog.setStatus(1);
deviceRestartLogRepository.saveAndFlush(deviceRestartLog);
// Thread1의 코드
Long logid = curruntTimeMills();
DeviceRestartLog deviceRestartLog = new DeviceRestartLog()
deviceRestartLog.setId(logid);
deviceRestartLog.setDeviceId(deviceId);
deviceRestartLog.status(0); //0=restart 안됨
deviceRestartLogRepository.save(deviceRestartLog);
messageSender.sendMessage(new RestartMessage(logid, deviceId)); // 기기 재부팅 진행
// 5초후 재실행 결과 확인, 5초 동안 Thread2 코드가 실행됨
Thread.sleep(1000 * 5);
deviceRestartLog = deviceRestartLogRepository.findByLogId(String.valueOf(logid));
restartStatus = deviceRestartLog.getStatus();
if (restartStatus = 1) {
logger.info("재시작 성공!");
} else {
logger.error("재시작 실패!");
}
재시작이 성공해 DB에 정상적으로 Update 되었다 하더라도
Thread1 이 sleep 후 가져온 값은 기존의 old data 이다.
(JPA 영속성 개념으로 인해 select 쿼리가 발생하지 않는다)
영속 컨텍스트에 저장된 기존 Entity 캐시를 비우고 DB에서 새로 값을 가져와 채워넣어줄 필요가 있다.
이를 위해선 EntityManager의 refresh 메서드를 사용해야 하는데
Spring Data JPA 에선 별도의 커스터마이징을 통해 호출이 가능하다.
참고: https://www.javacodegeeks.com/2017/10/access-entitymanager-spring-data-jpa.html
public interface DeviceRestartCustomRepository {
void refresh(DeviceRestartLog deviceRestartLog);
}
import org.springframework.transaction.annotation.Transactional;
public class DeviceRestartCustomRepositoryImpl implements DeviceRestartCustomRepository {
@PersistenceContext
private EntityManager em;
@Override
@Transactional
public void refresh(DeviceRestartLog deviceRestartLog) {
em.refresh(deviceRestartLog);
}
}
public interface DeviceRestartLogRepository extends JpaRepository<DeviceRestartLog, Long>,
DeviceRestartCustomRepository {
DeviceRestartLog findByMessageId(String messageId);
}
그리고 검색해온 값을 refresh 해주기만 하면 끝!
// 5초후 재실행 결과 확인
Thread.sleep(1000 * 5);
deviceRestartLog = deviceRestartLogRepository.findByMessageId(String.valueOf(msgId));
deviceRestartLogRepository.refresh(deviceRestartLog);
restartStatus = deviceRestartLog.getStatus();
...
public interface UserRepository extends JpaRepository<User, Long> {
@Modifying
@Transactional
@Query("UPDATE User u SET u.status = 'INACTIVE' WHERE u.lastLogin < :cutoffDate")
void deactivateOldUsers(LocalDateTime cutoffDate);
@Modifying(clearAutomatically = true)
@Transactional
@Query("DELETE FROM User u WHERE u.lastLogin < :cutoffDate")
void deleteOldUsers(LocalDateTime cutoffDate);
}
####
연관관계 어노테이션
https://www.datanucleus.org/products/accessplatform/jpa/annotations.html
위에선 하나의 테이블을 예제로 객체를 정의하였지만 실제 서비스를 구성할때에는 거미줄처럼 테이블간의 연관관계가 구성되어있다.
총 4가지로 엔티티간의 관계를 구성한다.
@OneToOne@OneToMany@ManyToOne@ManyToMany
이런 참조관계는 유동적으로 지정할 수 있다.
Board, Reply 엔티티가 있을때 당연히 게시글당 N 개의 댓글이 달리니 N:1 관계가 구성된다.
게시글 입장에선 @OneToMany이고
댓글 입장에선 @ManyToOne 이다.
그렇다 해서 무조건 두 클래스다 서로를 가리키고 있을 필요는 없다, 오히려 단방향 매핑을 권장함
일반적으로@OneToMany의 양방향 혹은 단방향 참조관계가 대부분이다.
@Getter
@Setter
@Entity
@Table(name = "tbl_boards")
@EqualsAndHashCode(of = "bno")
@ToString(exclude = "replies")
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long bno;
private String title;
private String writer;
private String content;
@CreationTimestamp
private Timestamp regdate;
@UpdateTimestamp
private Timestamp updatedate;
@OneToMany(mappedBy = "board", fetch = FetchType.LAZY)
private List<Reply> replies;
}
@Getter
@Setter
@Entity
@Table(name = "tbl_replies")
@EqualsAndHashCode
@ToString(exclude = "board")
public class Reply {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long rno;
private String replyText;
private String replyer;
@CreationTimestamp
private Timestamp regdate;
@UpdateTimestamp
private Timestamp updatedate;
// 양방향 매핑, @JsonIgnore 로 서로간 serialize 제한
@JsonIgnore
@ManyToOne(fetch = FetchType.LAZY)
private Board board;
}
/*
create table tbl_replies
(
rno bigint not null auto_increment,
regdate datetime,
reply_text varchar(255),
replyer varchar(255),
updatedate datetime,
board_bno bigint,
primary key (rno)
) engine = InnoDB
*/
replies 의 DDL 에 board_bno 필드가 지정된것 확인
일반적으로 Board 를 부모엔티티, Reply 를 자식엔티티 라 칭한다.
Board 는 존재하더라도 Reply 는 없을 수 있음으로
FK 각 생성되는 쪽을 자식엔티티라 함
추가 테이블 생성이슈
...ToMany 어노테이션을 별도의 설정없이 사용시 관계를 표시하기 위한 추가 테이블이 생성된다
자식테이블의 외래키 설정없이 생성되기에 추가테이블이 생성됨
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Setter
private Long bno;
...
/*
아래 ddl 이 추가됨
create table tbl_boards_replies
(
board_bno bigint not null,
replies_rno bigint not null
) engine = InnoDB
*/
@OneToMany
private List<Reply> replies;
}
아래 방법으로 추가테이블 생성문제를 막을 수 있다.
...ToOne에서@JoinColumn...ToMany에서@JoinColumn...ToManywith mappedBy
일반적으로 DDD 나 객체지향 관점에서 개발을 많이하기에 주로 부모 -> 자식 기준으로 개발을 진행함
2, 3 방법이 주로 사용된다.
@JoinColumn 은 단방향 매핑에서 사용하고
@OneToMany(with mappedBy) 은 양방향 매핑에서 사용한다.
…ToOne 에서 @JoinColumn
...ToOne 은 기본적으로 자식엔티티에서 사용됨
FK 역시 자식엔티티에 생성됨
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Setter
private Long bno;
...
// 별도 어노테이션 필요없음
}
public class Reply {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long rno;
private String replyText;
private String replyer;
@CreationTimestamp
private LocalDateTime regdate;
@UpdateTimestamp
private LocalDateTime updatedate;
// 양방향 매핑, @JsonIgnore 로 서로간 serialize 제한
@JsonIgnore
@ManyToOne
@JoinColumn(name = "my_bno")
private Board board;
}
Board 의 PK 를 가져와 my_bno 필드명으로 FK 설정한다.
…ToMany 에서 @JoinColumn
...ToMany 는 기본적으로 부모엔티티에서 사용됨
FK 는 설정한 자식엔티티에 생성됨
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Setter
private Long bno;
...
@OneToMany
@JoinColumn(name = "my_bno")
private List<Reply> replies;
}
public class Reply {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long rno;
// 별도 어노테이션 필요없음
...
}
@OneToMany with mappedBy
기존 방식대로 @OneToMany 에 mappedBy 속성 사용
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long bno;
...
@OneToMany(mappedBy = "board")
private List<Reply> replies;
}
public class Reply {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long rno;
...
@JsonIgnore
@ManyToOne
private Board board;
}
테이블 생성처리 - @JoinTable
역으로 테이블을 생성이 필요하고 추가설정을 해야한다면 @JoinTable 사용
@OneToMany
@JoinTable(name = "b_r_table",
joinColumns = @JoinColumn(name = "bno"),
inverseJoinColumns = @JoinColumn(name = "rno"))
private List<Reply> replies;
주의사항
양방향 매핑 관계에선 @ToString, json 변환같이 serialize 코드에서 무한루프가 발생할 수 있다.
@JoinColumn 으로 부모 -> 자식 관계만을 사용하는것을 권장하며
반드시 양방향 연관관계로 엔티티를 구성해야할 경우 아래와 같이 serialize 제외설정 필수
@ToString(exclude = "board")@JsonIgnore private Board board;
@OneToOne 관계매핑
@OneToOne사용 자체를 권장하지 않는다.
@OneToOne 은 관계 특성상 양방향 매핑일 수 밖에 없다, 부모객체와 자식객체에 모두 @OneToOne 필드를 정의해야 한다.
이떄 아무런 설정을 하지 않을경우 두 엔티티에 서로 FK 가 생성된다.
mappedBy 속성을 사용하면 양방향 매핑,
@JoinColumn 을 사용하면 단방향 매핑이 가능하다.
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long bno;
...
@OneToOne(mappedBy = "board", cascade = {CascadeType.PERSIST, CascadeType.REMOVE})
private Thumbnail thumbnail;
}
public class Thumbnail {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long tno;
...
@OneToOne
@JoinColumn(name = "my_bno")
private Board board;
}
@JoinColumn 을 사용하는 엔티티가 자식엔티티가 된다.
@OneToOne 사용시 부모엔티티에서 단방향 매핑하는 방법은 없다.
자신 엔티티에만 [@JoinColumn, @OneToOne] 어노테이션을 지정하면 단방향 매핑이 된다고 생각할 수 있지만 @ManyToOne 처럼 동작하기에 @OneToOne 이라 할 수 없다.
FetchMod, N + 1 문제
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long bno;
...
@OneToMany(mappedBy = "board", fetch = FetchType.EAGER)
private List<Reply> replies;
}
public class Reply {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long rno;
...
@JsonIgnore
@ManyToOne
private Board board;
}
지연로딩, 즉시로딩을 지정할 수 있으며 default 설정은 아래와 같다.
@OneToOne- EAGER@ManyToOne- EAGER@OneToMany- LAZY@ManyToMany- LAZY
...ToOne, ...ToMany, EAGER, LAZY 조합에 따라 N+1 이슈가 발생 가능하다.
LAZY 로 설정하더라도 참조가 이루어지는 코드, serialize 과정에서 N+1 이슈가 발생할 수 있다.
Cartessian Product 이슈
...ToMany(fetch = FetchType.EAGER) 을 사용할 때 LEFT OUTER JOIN 을 통해 1:N 관계 엔티티를 조회하기에 N개의 row 를 검색하는 쿼리를 수행한다.
...ToMany(fetch = FetchType.EAGER) 필드가 2개 이상일경우 Cartesian Product 이슈가 발생 가능하다.
N+1 이슈
기본적으로 ...ToOne 등을 가진 엔티티에서 리스트 조회 할 경우 N+1 문제가 발생한다.
자동으로 조인쿼리가 발생할것 같지만 JPA 가 알아서 조인쿼리를 생성하진 않는다.
아래와 같이 JPQL 과 FETCH JOIN 을 사용하는것을 권장한다.
@Query("SELECT b FROM Book b LEFT JOIN FETCH b.author")
List<Book> findAllWithFetch();
Book 의 경우 ManyToOne 관계이기 때문에 Pageable 객체와 같이 동작시켜도 정상적으로 동작한다.
@Query("SELECT b FROM Book b LEFT JOIN FETCH b.author")
List<Book> findAllWithPageable(Pageable pageable); // 이건 동작함
// select book0_.bno as bno1_5_0_,
// ...
// author1_.ano as ano1_3_1_,
// ...
// from tbl_book book0_
// left outer join tbl_author author1_ on book0_.author_id = author1_.ano
// limit ? offset ?
하지만 Page 객체를 반환하는 JPQL 은 동작하지 않는다.
@Query("SELECT b FROM Book b LEFT JOIN FETCH b.author")
Page<Book> findAllWithPageableResult(Pageable pageable); // 이건 컴파일에러
Fetch join + Paging 에선 CountQuery 를 별도로 만들어 줘야한다.
@Query(value = "SELECT b FROM Book b LEFT JOIN FETCH b.author",
countQuery = "SELECT COUNT(b.bno) FROM Book b")
Page<Book> findAllWithPageableResult(Pageable pageable);
테이블 풀스캔 이슈
이번엔 반대로 OneToMany 관계 주인인 Author 에서 FETCH JOIN 과 pageable 을 사용해보자.
@Query("SELECT a FROM Author a LEFT JOIN FETCH a.books")
List<Author> findAllWithPageable(Pageable pageable);
동작하긴 하지만 마법같은 SQL 문이 발생하는 것이 아니라, 테이블 풀스캔 쿼리 실행 후 List 에서 상위 size개수를 가져오는 방식으로 동작한다.
영속성, cascade(전이전략)
참고: https://www.baeldung.com/jpa-cascade-types
Oracle,Mysql등 DDL 에서on delete cascade편의기능과는 관련없다.
EntityManager 가 제공하는 [New, Managed, Detached, Removed] 상태의 전이를 [OneToMany, ManyToOne] 관계 객체에게 적용하기 위한 설정.
- New: 엔티티를 생성자를 통해 생성만 한 상태
- Managed:
persist()를 통해 영속 컨텍스트에 저장해둔 상태,
트랜잭션이 완료(flush)되면 DB 에 쿼리가 발생한다. - Removed:
remove()를 통해 영속 컨텍스트에서 삭제된 상태, - 트랜잭션이 완료(flush)되면 DB 에 쿼리가 발생한다.
- Detached:
detached(), clear()를 통해 준영속(영속 컨텍스트에서 분리)된 상태,
merge()를 통해 준영속에서 업데이트된 객체를 영속 컨텍스트에서 찾아 병합시킨다.
default cacade 는 빈 배열 형태, 아래 설정을 진행할 수 있음.
- CascadeType.PERSIST: 부모 엔티티 영속화시 때 연관된 자식들도 함께 영속화.
- CascadeType.MERGE: 부모 엔티티 병합시 연관된 자식들도 함께 병합.
- CascadeType.REMOVE: 부모 객체 삭제시 연관된 자식들도 함께 삭제.
- CascadeType.REFRESH: 엔티티 매니저의
refresh()호출시 전이. - CascadeType.DETACH: 부모 객체 detach() 함수 호출시 연관객체도 준영속 진행.
- CascadeType.ALL: 위의 모든 사항을 포함, 가장 일반적으로 사용됨.
CascadeType defaults to the empty array
Board 와 단방향으로 설정된 Reply 등의 자식엔티티를 같이 insert, delete 해야하는 경우
//편하지만 jpa 관점에 위배되는 코드
public void insertReply() {
Board board = new Board();
board.setBno(1L);
Reply reply = new Reply();
reply.setReply("댓글1");
reply.setReplyer("홍길동");
reply.setBoard(board);
replyRepo.save(reply);
}
orphanRemoval
CascadeType.REMOVE와 같은 거의 같은 기능, 부모객체가 삭제되면 orphanRemoval 또한 같이 삭제된다.
차이점은 자식엔티티를 null로 설정하고 저장했을 때 orphanRemoval는 삭제하고
CascadeType.REMOVE는 삭제하지 않는다.
부모 엔티티에서 의도적으로 연결관계를 끊었을 때 고아 객체로 인식되어
orphanRemoval된다.
다음과 같이 하나는 REMOVE, 하나는 orphanRemoval 를 설정해서 테스트
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long bno;
@OneToMany(cascade = {CascadeType.PERSIST, CascadeType.REMOVE})
@JoinColumn(name = "bno")
private List<Reply> replies;
@OneToMany(cascade = {CascadeType.PERSIST}, orphanRemoval = true)
@JoinColumn(name = "bno")
private List<Attachment> attachments; // 첨부파일
public void testOrphan() {
this.replies.clear();
this.attachments.clear();
}
}
deleteById 로 삭제 진행시 아래와 같이 update & delete 쿼리가 진행된다.
update attachment set bno=null where bno=?
update tbl_replies set bno=null where bno=?
delete from attachment where ano=?
delete from attachment where ano=?
delete from tbl_replies where rno=?
delete from tbl_replies where rno=?
delete from tbl_boards where bno=?
아래와 같이 List clear 후 저장진행시 replies 는 update 만,
attachments 는 update & delete 쿼리가 진행된다.
clear()함수로 같은 참조에 데이터가 지워져야 정상동작함을 주의
@PatchMapping("/test/orphan/{id}")
public Board testOrphan(@PathVariable Long id) {
Board board = boardService.findById(id);
board.testOrphan();
board = boardService.save(board);
return board;
}
update attachment set bno=null where bno=?
update tbl_replies set bno=null where bno=?
delete from attachment where ano=?
delete from attachment where ano=?
replies 도 update 로 인해 board 와 연결이 끊겼기 때문에 더이상 조인쿼리를 통해 검색되지 않는다.
@OrderColumn
...ToMany 를 사용할경우 필드로 List 와 같은 컬렉션을 사용하는데
@OrderColumn 을 추가하면 순서가 있는 객체로 인식한다(DB에 순서값을 저장)
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long bno;
@OneToMany(cascade = CascadeType.PERSIST, fetch = FetchType.EAGER)
@JoinColumn(name = "bno")
@OrderColumn // replies_order 로 Order 필드 생성됨
private List<Reply> replies;
}
name 속성으로 이름 지정 가능, 인덱스는 0부터 시작한다.
밸류 매핑 어노테이션
엔티티 클래스 내부에서 사용자정의 클래스를 멤버변수로 사용할경우
반드시 연관된 엔티티일 필요는 없다.
필요에 따라 사용자정의 클래스를 단순 밸류타입으로 원시타입처럼 엔티티에서 사용 가능하다.
@Convert
아래 인터페이스의 구현체로 DB 에 저장될 원시타입과 Object 를 변환해줌
X 타입이 Object
Y 타입이 원시타입
public interface AttributeConverter<X,Y> {
public Y convertToDatabaseColumn (X attribute);
public X convertToEntityAttribute (Y dbData);
}
구현체에 @Converter(autoApply = true) 지정시 엔티티 property에 @Convert 어노테이션 없이도 자동으로 변환설정됨
@Converter(autoApply = true)
public class MoneyConverter implements AttributeConverter<Money, Integer> {
@Override
public Integer convertToDatabaseColumn(Money money) {
return money == null ? null : money.getValue();
}
@Override
public Money convertToEntityAttribute(Integer value) {
return value == null ? null : new Money(value);
}
}
@EmbeddedId
단일키를 가독성을 높이기 위해 클래스화시키거나 복합키를 구현해야할 때 사용
@Embeddable 과 함께 Serializable 의 구현체여야함
@Entity
@Table(name = "purchase_order")
public class Order {
@EmbeddedId
private OrderId number;
}
@Embeddable
public class OrderId implements Serializable {
@Column(name = "order_number")
private String number;
}
/*
create table purchase_order
(
order_number varchar(255) not null,
primary key (order_number)
) engine = InnoDB
*/
아래처럼 복합키를 사용해야할 경우에도 사용할 수 있다.
@Entity
@Table(name = "purchase_order")
public class Order {
@EmbeddedId
private OrderId number;
}
@Embeddable
public class OrderId implements Serializable {
@Column(name = "order_number")
private String number;
@Column(name = "order_date")
private String date;
}
/*
create table purchase_order
(
order_date varchar(255) not null,
order_number varchar(255) not null,
primary key (order_date, order_number)
) engine = InnoDB
*/
public interface OrderRepository extends JpaRepository<Order, OrderId> {
List<Order> findByOrderIdIn(List<OrderId> ids);
// SELECT * FROM purchase_order
// WHERE (number, date) IN (("1", "20230918"), ("1", "20230714"));
}
@Embedded
벨류객체를 사용해야할 때 사용
@Embeddable 어노테이션과 함께 사용하여
order 내의 각종 사용자정의 클래스를 DB 테이블에 평탄화시킬 수 있음
@Entity
@Table(name = "purchase_order")
public class Order {
@EmbeddedId
private OrderNo number;
@Embedded
private ShippingInfo shippingInfo;
}
@Embeddable
public class ShippingInfo {
@Embedded
private Address address;
@Embedded
private Receiver receiver;
@Column(name = "shipping_message")
private String message;
}
@Embeddable
public class Address {
@Column(name = "zip_code")
private String zipCode;
@Column(name = "address1")
private String address1;
@Column(name = "address2")
private String address2;
}
@Embeddable
public class Receiver {
@Column(name = "receiver_name")
private String name;
@Column(name = "receiver_phone")
private String phone;
}
/*
create table purchase_order
(
order_number varchar(255) not null,
address1 varchar(255),
address2 varchar(255),
zip_code varchar(255),
shipping_message varchar(255),
receiver_name varchar(255),
receiver_phone varchar(255),
primary key (order_number)
) engine = InnoDB
*/
@AttributeOverrides 를 사용하면 엔티티에서 DDL 필드명을 별도로 지정가능하다
@Embeddable
public class ShippingInfo {
@Embedded
@AttributeOverrides({
@AttributeOverride(name = "zipCode", column = @Column(name = "shipping_zip_code")),
@AttributeOverride(name = "address1", column = @Column(name = "shipping_addr1")),
@AttributeOverride(name = "address2", column = @Column(name = "shipping_addr2"))
})
private Address address;
@Embedded
private Receiver receiver;
@Column(name = "shipping_message")
private String message;
}
여러 엔티티클래스에서 동일한
@Embeddable객체를 사용할 때 필드명 헷갈림 방지용으로 사용
@CollectionTable, @ElementCollection
@Embeddable 을 사용하는 벨류타입이지만 1:N, M:N 매핑을 구성할 때
@Convert 사용하기에는 데이터가 너무 많을때 별도의 테이블로 나눠야 한다.
벨류타입에서 @OneToMany, @ManyToMany 방식보단 @CollectionTable 을 사용하는게 간결할 수 있다.
사용법은
...ToMany와 비슷함
@Embeddable
public class OrderLine {
@Embedded
private ProductId productId;
@Column(name = "price")
private Integer price;
@Column(name = "quantity")
private int quantity;
}
@Entity
@Table(name = "purchase_order")
public class Order {
@EmbeddedId
private OrderId number;
@ElementCollection(fetch = FetchType.LAZY)
@CollectionTable(name = "order_line", joinColumns = @JoinColumn(name = "order_number"))
private List<OrderLine> orderLines;
}
/*
create table order_line
(
order_number varchar(255) not null,
price integer,
product_id varchar(255),
quantity integer
) engine = InnoDB
create table purchase_order
(
order_number varchar(255) not null,
primary key (order_number)
) engine = InnoDB
*/
order_line 에는 별도의 primary key 가 생기지 않음으로 벨류타입 정의에 합리적이다.
@Enumerated
enum 타입저장시 지정하여 사용가능.
지정하지 않을경우 enum 객체의 정의 순서에 따라 int 값이 저장됨.
public class MemberEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long uid;
private String uname;
private String upw;
@Enumerated(EnumType.STRING)
private MemberRole role;
}
기본 어노테이션
JPA 가장 기본적인 어노테이션의 속성들 설명
@Table
| 속성 | type | 설명 |
|---|---|---|
name |
String |
테이블 이름 지정 |
catalog |
String |
테이블 카테고리 지정 |
schema |
String |
스키마 지정 |
uniqueConstraints |
UniqueConstraints[] |
칼럼값 유니크 제약 조건 |
indexes |
Index[] |
인덱스 생성 |
DB 예약어의 경우 테이블명으로 사용할 수 없는데 아래처럼 name 속성으로 문자열로 처리할 수 있다.
웬만하면 예약어는 피하는것을 권장
@Table(name = "[order]")
@Column
| 속성 | type | 설명 | 허용값 |
|---|---|---|---|
unique |
boolean |
유니크 여부 | default false |
nullable |
boolean |
널 허용 여부 | default true |
insertable |
boolean |
insert 가능여부 |
default true |
updateable |
boolean |
update 가능여부 |
default true |
name |
String |
칼럼 이름 지정 | |
table |
String |
연관 테이블 이름 지정 | |
length |
int |
칼럼 사이즈 지정 | 255 |
precision |
int |
소수 정밀도 | 0 |
scale |
int |
소수 자리수 지정 | 0 |
@CreationTimestamp, @UpdateTimestamp, @CreatedDate, @LastModifiedDate
@CreationTimestamp, @UpdateTimestamp 의 경우 org.hibernate에서 지원하는 어노테이션, VM date 의 시간값을 사용해 값을 기록한다.
VM date: 어플리케이션 서버 시간이지만, 추가적으로 동기화 가능.
@CreationTimestamp
private LocalDateTime createTime;
@UpdateTimestamp
private LocalDateTime updateTime;
// Hibernate 6.0.0 부터 SourceType 지정 가능
@CreationTimestamp(source = SourceType.DB)
private Instant createdOn;
@UpdateTimestamp(source = SourceType.DB)
private Instant lastUpdatedOn;
@CreatedDate, @LastModifiedDate 의 경우 spring data 에서 지원하는 어노테이션, 어플리케이션 서버의 시간값을 사용해 값을 기록한다.
spring data 에서 제공하는 어노테이션이 좀 더 범용적이지만 @EnableJpaAuditing, @EntityListeners(AuditingEntityListener.class) 설정이 필요함으로 편한거 사용하면 된다.
MySQL 의 경우 Instant, ZoneDateTime 같은 offset 관련 시간객체의 경우 TIMESTAMP 로 저장하며, LocalDateTime 같은 경우 DATETIM 형태로 저장한다.
- DATETIME
시간대 정보 없이 날짜와 시간을 저장. Hibernate는 UTC 시간 값을 저장하지만 변환은 서버가 아닌 애플리케이션에서 처리. - TIMESTAMP
UTC로 저장되며, MySQL이 서버 시간대를 기준으로 변환 처리. 조회 시 서버의 시간대 설정에 따라 시간 반환. MySQL 의 TIMEZONE 설정을 변경하면 결과값이 다르게 나올 수 있다.
@Inheritance, @DiscriminatorValue, @DiscriminatorColumn
상속관계에 있는 객체를 DB에서 사용하기위한 어노테이션
InheritanceType.SINGLE_TABLE[default]InheritanceType.JOINEDInheritanceType.TABLE_PER_CLASS
부모클레스에 @DiscriminatorColumn(name = "image_type"), 정의하지 않으면 필드 기본이름은 DTYPE
하위클레스에 @DiscriminatorValue("value") 지정, 부모클래스 구분 컬럼에 저장할 값을 지정
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "image_type")
@Table(name = "image")
public abstract class Image {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "image_id")
private Long id;
@Column(name = "image_path")
private String path;
@Column(name = "upload_time")
private LocalDateTime uploadTime;
}
@Entity
@DiscriminatorValue("II")
public class InternalImage extends Image {
...
}
create table image
(
image_id int auto_increment primary key,
image_path varchar(255) null,
product_id varchar(50) null,
upload_time datetime null
image_type varchar(10) null,
)
@Access
@Access 어노테이션 사용하면 DB데이터 매핑전력을 지정할 수 있다.
필드에 접근시킬 지 getter 를 통해 접근시킬 지 지정할 수 있다.
@Access(AccessType.FIELD)
필드에 직접 접근, Class 위에 선언, private field 접근 가능@Access(AccessType.PROPERTY)
getter 를 통해 접근
별도로 정의하지 않았을 경우 @Id 어노테이션이 필드에 정의되어 있는지, getter 메서드에 정의되어 있는지에 따라 매핑전략이 결정된다.
대부분 필드에 @Id 를 지정하기에 @Access(AccessType.FIELD) 를 사용한다.
@Entity
public class Member {
// 기본적으로 @Access(AccessType.FIELD) 전략 사용
@Id
private String id;
@Transient
private String firstName;
@Transient
private String lastName;
@Access(AccessType.PROPERTY)
public String getFullName() {
return firstName + lastName;
}
}
getFullName 에 의해 DB 에 fulle_name 칼럼이 생성되고 매핑된다.
@Id, @GeneratedValue, @GenericGenerator
식별키 생성 방법을 지정한다.
| 속성값 | 설명 |
|---|---|
AUTO |
아래 3개중 DB에 맞게 자동으로 생성 |
TABLE |
기본키 생성방식 자체를 DB에 위임 |
SEQUENCE |
시퀀스를 사용해서 식별키 생성, Oracle에서 자주 사용 |
IDENTITY |
별도의 키를 생성해주는 채번 테이블 사용, MySQL에서 자주 사용 |
같은 DB 더라도 버전별로 시퀀스 식별키 생성방법이 달라 GenerationType.AUTO 는 혼란을 야기할수 있어 사용을 권장하지 않는다.
실제 MySQL 8.0 이상버전에 AUTO 사용시 아래와 같은 시퀀스용 테이블을 만들어 insert, select, update 를 반복한다.
create table hibernate_sequence
(
next_val bigint
) engine = InnoDB;
insert into hibernate_sequence values (1)
select next_val as id_val from hibernate_sequence for update
update hibernate_sequence set next_val= ? where next_val=?
보통 @GeneratedValue(strategy = GenerationType.IDENTITY) 를 사용하여 Id 생성전략을 DataSource 에 맡긴다.
MySQL 의 경우 테이블의 auto increment 기능을 사용한다.
@Getter
@Entity(name = "t_account")
public class AccountEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "account_id")
private Long accountId;
private String userName;
private OffsetDateTime createTime;
}
strategy값이 TABLE SEQUENCE 일 경우 별도의 테이블을 생성해야 함으로
@SequenceGenerator혹은 @TableGenerator 를 엔티티클래스 위에 정의한다.
@Entity
@TableGenerator(name="my_seq_table", table="SEQTB_USER", pkColumnValue="user_seq", allocationSize=1)
public class User{
@Id
@GeneratedValue(strategy=GenerationType.TABLE, generator="my_seq_table")
private Long uid;
private String uname;
}
@Entity
@SequenceGenerator(name = "my_seq", sequnceName = "SEQ_BOARD", initialValue = 1, allocationSize = 1)
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "my_seq")
private Long id;
}
이외에도 @GeneratedValue 를 사용해서 UUID, Sequence ID 등을 사용할 수 있다.
@Entity
class Reservation {
@Id
@GeneratedValue(strategy = GenerationType.UUID)
private UUID id;
private String status;
private String number;
}
직접 커스텀한 ID 생성방식이 있다면 아래와 같이 @GenericGenerator 를 사용하면 된다.
@Getter
@Entity(name = "t_account")
public class AccountEntity {
@Id
@GeneratedValue(generator = "customIdGenerator") // @GenericGenerator의 name modifier 에 지정한 이름
@GenericGenerator(name = "customIdGenerator",
type = CustomIdGenerator.class)
@Column(name = "account_id")
private Long accountId;
private String userName;
private OffsetDateTime createTime;
}
public class CustomIdGenerator implements IdentifierGenerator {
// snowflake 는 @Bean 으로 등록
private final Snowflake snowflake;
public CustomIdGenerator(Snowflake snowflake) {
this.snowflake = snowflake;
}
@Override
public Serializable generate(SharedSessionContractImplementor session, Object object) {
// 원하는 ID 생성 로직을 구현합니다.
// 여기서는 UUID를 예로 사용합니다.
return snowflake.nextId();
}
}
Persistable
Persistable 인터페이스는 @GeneratedValue 를 통해 Id 를 생성할 수 없을 때 사용할만하다.
@Id 어노테이션은 객체의 영속성 역할에도 영향을 끼친다, @GeneratedValue 로 생성된 Id 라면 INSERT 쿼리가 호출되겠지만, 아래처럼 @Id 어노테이션만 설정하고 초기화 했을 때 INSERT 요청일지 UPDATE 요청일지 구분할 수 없다.
@Entity
public class CustomEntity {
@Id
private Long id;
...
}
managed 영역에 이미 persist(영속)되어 있다면 UPDATE 요청을 하겠지만,
new 연산자를 통해 생성한 상태라면 INSERT 해야할지 UPDATE 해야할 지 모르기 때문에 SELECT 를 먼저 한번 수행한다.
@GeneratedValue 를 사용하는 것이 정석이지만 Persistable 인터페이스를 구현시켜 isNew 속성을 지정해주어 영속화 되지 않는 객체도 INSERT, UPDATE 구분할 수 있다.
import org.springframework.data.domain.Persistable;
@Getter
@Entity
public class CustomEntity implements Persistable<Long> {
@Id
private Long id;
@Setter
private boolean isNew;
public CustomEntity(Long id) {
this.id = id;
this.isNew = true; // 새로운 엔티티임을 명시적으로 설정
}
}
트랜잭션
논리적인 하나의 작업단위가 트랜잭션이다.
위의 Order 와 OrderLine 이 같이 insert 되는 것도 하나의 작업단위이기에 하나의 트랜잭션이라 할 수 있다.
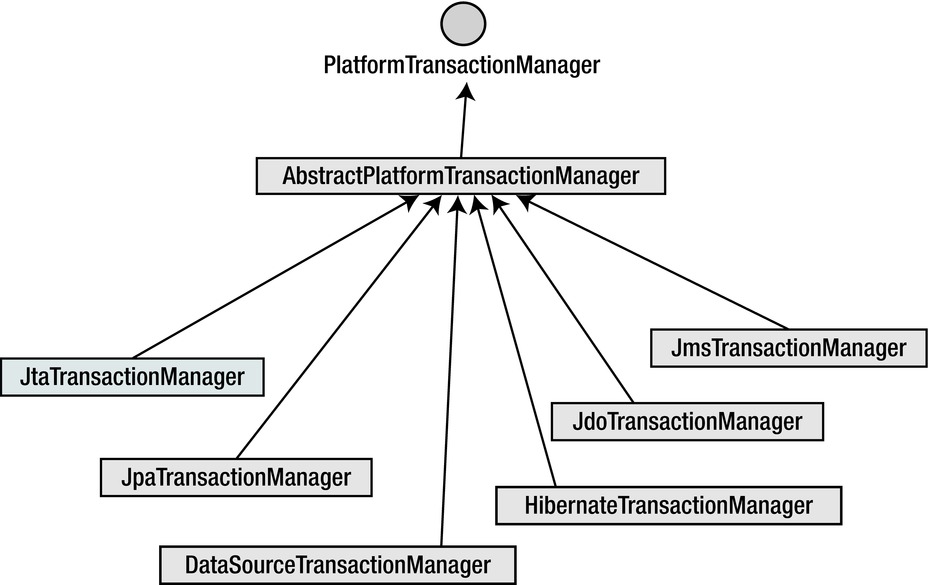
구현체별로 다르겠지만 JPA 사용시 JpaTransactionManager 을 사용할 것
TransactionManager 을 직접사용할 경우는 없지만 내부적으로 결국 TransactionManager commit(), rollback() 을 사용해 트랜잭션 처리가 진행되는 구조이다.
Connection conn = null;
try {
conn = ConnectionProvider.getConncection();
conn.setAutoCommit(false);
// TODO Somthing
conn.commit();
} catch (Exception e) {
JdbcUtil.rollback(conn);
throw new RuntimeException(e);
} finally {
JdbcUtil.close(conn);
}
트랜잭션 전파
트랜잭션 전파란 특정 A프랜잭션이 처리되는 과정 안에서 또다른 B트랜잭션 이 처리되는 경우 에러가 발생할 경우 각 트랜잭션에 에러전파 하는것을 뜻한다.
| 전파방식 | 의미 |
|---|---|
REQUIRED(default) |
트랜잭션 상황에서 실행되어야 한다. 진행 중인 트랜잭션이 있다면 이 트랜잭션에서 실행된다. 없는 경우에는 트랜잭션이 새로 시작된다. |
MANDATORY |
호출 전에 반드시 진행 중인 트랜잭션이 존재해야 한다. 진행 중인 트랜잭션이 존재하지 않을 경우 예외 발생 |
REQUIRED_NEW |
자신만의 트랜잭션 상황에서 실행되어야 한다. 이미 진행 중인 트랜잭션이 있으면 그 트랜잭션은 해당 메소드가 반환되기 전에 잠시 중단된다. |
SUPPORTS |
진행 중인 트랜잭션이 없더라도 실행 가능하고, 트랜잭션이 있는 경우에는 이 트랜잭션 상황에서 실행된다. |
NOT_SUPPORTED |
트랜잭션이 없는 상황에서 실행 만약 진행 중인 트랜잭션이 있다면 해당 메소드가 반환되기 전까지 잠시 중단한다. |
NEVER |
트랜잭션 진행 상황에서 실행 될 수 없다. 만약 이미 진행 중인 트랜잭션이 존재하면 예외 발생 |
NESTED |
이미 진행 중인 트랜잭션이 존재하면 중첩된 트랜잭션에서 실행되어야 함을 나타낸다. 중첩된 트랜잭션은 본 트랜잭션과 독립적으로 커밋되거나 롤백될 수 있다. 만약 본 트랜잭션이 없는 상황이라면 이는 REQUIRED와 동일하게 작동한다. 그러나 이 전파방식은 DB 벤더 의존적이며, 지원이 안되는 경우도 많다. |
트랜잭션 전파방삭에 따라 A, B 의 rollback 결정이 달라진다.
@Transactional
@Transactional 어노테이션이 있으면 Spring AOP 가 알아서 TransactionManager 기반으로 commit, rollback 을 진행한다.
@Transactional 어노테이션을 사용하는 메서드에서 데이터 소스에 접근하는 쿼리를 실행할 때 락이 걸린다.
rollbackFor: 특정Exception발생 시rollback하도록 설정noRollbackFor: 특정Exception발생 시rollback하지 않도록 설정
@Transactional 은 모든 예외발생시 rollback 하지 않고 RuntimeException, Error 를 상속한 예외 발생시에만 rollback 한다.
위 전제조건을 토대로 상황에 맞게 rollbackFor, noRollbackFor 을 사용한다.
propagation: 위 트랜잭션 전파 참고하여 설정,Propagation.REQUIRED가 defaultisolation: 트랜잭션 격리레벨 설정,Isolation.DEFAULT가 default
Isolation.DEFAULT는 DBMS 에 설정된 격리수준을 사용한다는 뜻
TransactionManager
TransactionManager 는 DB 영역에서 트랜잭션 기능을 추상화 시킨 클래스이다.
JPA 의 경우 EntityManager 의 begin, commit 를 통해 트랜잭션을 진행하고,
JDBC 의 경우 dataSource.getConnection 의 setAutoCommit(false), commit 을 통해 트랜잭션을 진행한다.
스프링에선 이를 아래와 같은 TransactionManager 인터페이스로 트랜잭션 과정을 추상화 시켰다.
public interface TransactionManager {}
public interface PlatformTransactionManager extends TransactionManager {
TransactionStatus getTransaction(@Nullable TransactionDefinition definition) throws TransactionException;
void commit(TransactionStatus status) throws TransactionException;
void rollback(TransactionStatus status) throws TransactionException;
}
public abstract class AbstractPlatformTransactionManager
implements PlatformTransactionManager, ConfigurableTransactionManager, Serializable {
...
}
// 아래와 같은 AbstractPlatformTransactionManager 구현체들이 있음.
// JpaTransactionManager
// DataSourceTransactionManager
// JmsTransactionManager - java message system 을 같이 사용할 경우 이용
JpaTransactionManager 를 사용하는 상황에서 @Transactional 어노테이션을 만나면 Spring AOP 가 알아서 추상화 처리된 AbstractPlatformTransactionManager 의 동작대로 DB 와의 연결 및 트랜잭션 작업을 수행한다.
- 트랜잭션 시작, 하래 함수를 순서대로 호출
TransactionAspectSupport.createTransactionIfNecessary
AbstractPlatformTransactionManager.getTransaction
AbstractPlatformTransactionManager.startTransaction DataSource로부터Connection흭득 및ThreadLocal에 등록AbstractPlatformTransactionManager.doBeginTransactionSynchronizationManager.bindResource - ThreadLocal 등록- 트랜잭션 내부에서 수행되는
Repository메서드들은ThreadLocal로부터Connection을 가져와서 쿼리를 실행 - 트랜잭션 종료(commit or rollback)
TransactionAspectSupport.cleanupTransactionInfo DataSource에Connection반환
readOnly = true 가 특별한 유형의 연결을 생성하지는 않지만, 읽기 전용 트랜잭션의 이점을 활용하여 ORM의 성능을 최적화할 수 있다.
수정요청시 에러를 발생시키도록 하거나 Hibernate 의 영속성 플러시 작업을 추가적으로 하지않아 성능을 최적화 할 수 있다.
이를 통해 데이터 일관성을 보장하고, 읽기 전용 작업의 성능을 극대화할 수 있다.
DataSourceTransactionManager 를 JPA 에서 사용하면 간단한 쿼리는 정상동작 하겠지만 영속성 관리, Lazy loading 등에서 문제가 발생할 수 있음으로 JpaTransactionManager 사용을 권장한다.
트랜잭션 general_log
JpaTransactionManager 가 트랜잭션을 위해 호출하는 SQL 쿼리를 general_log 를 통해 확인가능하다.
기존에 FILE 에 출력되는 로그를 mysql.general_log 테이블에 출력되도록 변경.
SHOW VARIABLES LIKE 'log_output';
-- +-------------+-----+
-- |Variable_name|Value|
-- +-------------+-----+
-- |log_output |FILE |
-- +-------------+-----+
SET GLOBAL general_log = 'ON';
SET GLOBAL log_output = 'TABLE';
SELECT * FROM mysql.general_log
위와같이 설정하고 spring.jpa.open-in-view=false 상태에서 기본 DataSource 를 사용해서 @Transaction 설정별로 mysql.general_log 의 출력 결과를 확인하면 아래와 같다.
@Beans
public DataSource dataSource() {
HikariDataSource dataSource = new HikariDataSource();
dataSource.setJdbcUrl("jdbc:mysql://localhost:3306/demo?useUnicode=true&serverTimezone=Asia/Seoul");
dataSource.setUsername("root");
dataSource.setPassword("root");
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
return dataSource;
}
// @Transaction 이 없을 때
public List<Board> findAll() {
return repository.findAll();
}
@Transactional(readOnly = true)
public List<Board> findAll() {
return repository.findAll();
}
위와 같이 @Transactional(readOnly = true) 있는것과 없는 메서드 실행시 아래 6개의 general_log 가 출력된다.
- set session transaction read only
세션의 읽기 전용 지정 - SET autocommit=0
세션에서 호출될 쿼리들이 자동커밋되지 않고 트랜잭션으로 묶이는 것을 의미, 트랜잭션 시작을 의미. - select b1_0.bno,… from tbl_boards b1_0
쿼리 수행 - commit
쿼리 커밋, 트랜잭션 종료 - SET autocommit=1
autocommit 원복 - set session transaction read write
세션 읽기 쓰기 지정 원복
@Transactional을 지정하지 않으면repository메서드 호출마다session에 대한 설정을 수행하기 때문에 위 예제의 경우@Transactional(readOnly = true)설정한것과 동일하다.
@Transactional(readOnly=false) 의 경우 4개의 general_log 가 출력된다.
@Transactional(readOnly=false)
public List<Board> findAll() {
return repository.findAll();
}
// SET autocommit=0
// "select b1_0.bno,... from tbl_boards b1_0"
// commit
// SET autocommit=1
@Transactional(readOnly=true) 를 설정할 경우 영속성 레이어에서 추가작업을 하지 않아 어플리케이션 레이어에선 부하가 줄어들겠지만,
session transaction 의 read only, read write 작업을 추가적으로 수행하기 때문에 DB 레이어에선 부하가 증가한다.
DataSource 에서 autocommit 설정을 disable 처리하고, @Transactional 만 지정된 메서드를 수행하면 단 2개의 general_log 가 출력된다.
HikariDataSource dataSource = new HikariDataSource();
...
dataSource.setAutoCommit(false);
"select b1_0,.... from tbl_boards b1_0"
commit
대부분의 상황에서 트랜잭션은 필수이기에 autocommit 을 사용하겠지만 아래와 같은 특수한 상황에선 사용할만 하다.
- SELECT 만 수행하는 CQRS 패턴 어플리케이션의 경우 DB 부하를 줄이기 위해.
- 읽기전용
DataSource를 구성하고AbstractRoutingDataSource, LazyConnectionDataSourceProxy를 통해 분리호출 할 경우.
실시간 트랜잭션 read_only 활성여부를 확인하려면 아래 SQL 참고
-- SET GLOBAL TRANSACTION READ WRITE;
-- SET SESSION TRANSACTION READ WRITE;
SET GLOBAL TRANSACTION READ ONLY;
SET SESSION TRANSACTION READ ONLY;
SELECT @@SESSION.transaction_isolation as 'STI',
@@SESSION.transaction_read_only as 'STR',
@@GLOBAL.transaction_isolation as 'GTI',
@@GLOBAL.transaction_read_only as 'GTR';
SELECT * FROM mysql.general_log;
MySQL Workbench 기준, DB Client 별로 출력결과가 다를 수 있음.
@Lock, @Version
스레드가 애그리거트를 read, write 하는 동안
다른 스레드가 수정할 수 없도록 설정하기 위한 기능
Pessimistic Lock비관적 락, 선점잠금
Optimistic Lock낙관적 락, 비선점잠금
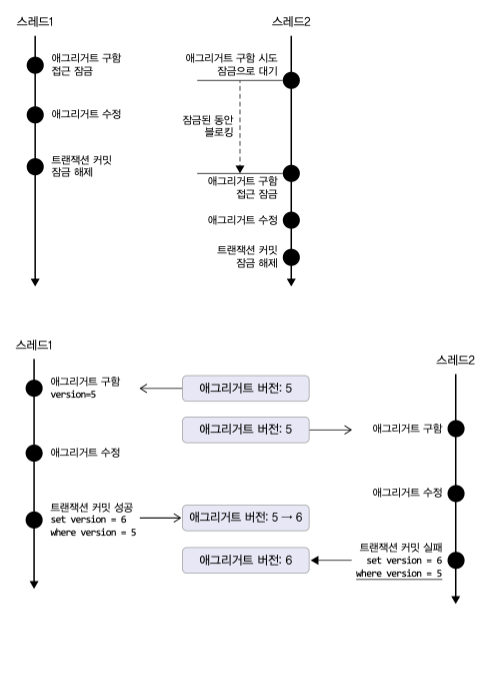
DB row 에 잠금을 걸어 트랜잭션을 block 시키는 비관적 락 방식이 있고
version 정보를 통해 Lost Update 를 제한시키는 낙관적 락 방식이 있다.
낙관적 락(Optimistic Lock)
낙관적 락 에선 DB에서 제공하는 락을 사용하지 않고 @Version 을 사용한다.
@Version 어노테이션만 지정해도 자동 사용된다.
[Long, Int, Short, Timestamp]사용 가능
@Getter
@Access(AccessType.FIELD)
@Entity
@Table(name = "purchase_order")
public class Order {
@EmbeddedId
private OrderId orderId;
...
...
// 낙관적 락을 위한 필드
@Version
private long version;
}
Entity 에 @Version 만 지정하면 별도의 어노테이션을 사용하지 않아도 version 정보를 기반으로 UPDATE 하기 때문에 Lost Update 문제가 발생하지 않는다.
-- OrderService->patch start!
select order0_.order_number as order_nu1_1_,
order0_.state as state2_1_,
order0_.version as version3_1_
from purchase_order order0_
where order0_.order_number = ?
-- UPDATE 시 version 체크
update purchase_order set state=?, version=? where order_number=? and version=?
-- OrderService->patch end!
쿼리 메서드에 별도로 @Lock 어노테이션을 사용해 낙관적 락에 대한 추가설정을 할 수 있다.
- OPTIMISTIC
트랜잭션 종료 시점에 한번 더 버전정보를 체크한다.
만약 종료시점에서 검색된 version 이 다를경우OptimisticLockException을 발생시킨다.
현재 스레드의Dirty Read, Lost Update상황을 방지한다. - OPTIMISTIC_FORCE_INCREMENT
단순SELECT요청도version을 증가시킨다. 변경까지 한다면version이 2 증가한다.
타 스레드의Dirty Read, Lost Update상황을 방지한다.
@Lock(LockModeType.OPTIMISTIC)
@Query("SELECT o FROM Order o WHERE o.orderId = :orderId")
Optional<Order> findByIdOptimistic(OrderId orderId);
@Lock(LockModeType.OPTIMISTIC_FORCE_INCREMENT)
@Query("SELECT o FROM Order o WHERE o.state = :state")
List<Order> findAllByOrderStateOptimistic(OrderState state);
LockModeType.OPTIMISTIC 을 사용했다면 초기 SELECT 한 Entity version 과 트랜잭션 종료 직전 조회한 version 이 일치하지 않는다면 OptimisticLockException 가 발생한다.
-- OrderService->findByIdOptimistic start! 함수 트랜잭션 시작
-- service function start!
select order0_.order_number as order_nu1_1_,
order0_.state as state2_1_,
order0_.version as version3_1_
from purchase_order order0_
where order0_.order_number = ?
-- service function end!
select version as version_ from purchase_order where order_number =?
-- OrderService->findByIdOptimistic end! 함수 트랜잭션 종료 전 version 검사
-- 일치하지 않으면 OptimisticLockException
LockModeType.OPTIMISTIC_FORCE_INCREMENT 을 사용했다면 SELECT 로 조회한 모든 Entity version 을 증가시킴.
-- OrderService->findAllByOrderState start!
select order0_.order_number as order_nu1_1_,
order0_.state as state2_1_,
order0_.version as version3_1_
from purchase_order order0_
where order0_.state = ?
update purchase_order set version=? where order_number=? and version=?
update purchase_order set version=? where order_number=? and version=?
update purchase_order set version=? where order_number=? and version=?
update purchase_order set version=? where order_number=? and version=?
update purchase_order set version=? where order_number=? and version=?
-- SELECT 로 조회된 purchase_order 개수만큼 수행
-- OrderService->findAllByOrderState end!
LockModeType.OPTIMISTIC_FORCE_INCREMENT 는 부하를 유발시키는 설정이긴 하지만 first-commiter win 과 같은 형태로 운영할 수 있다.
낙관적 락의 단점은 DB 락을 가져올수 있는지 즉시 체크하지 못하기 때문에 데이터 일관성 체크를 커밋 시점에야 가능하다는 것이다.
낙관적 락 과 연계된 쿼리가 있다면 별도의 처리를 해줘야할 수 도 있다.
비관적 락(Pessimistic Lock)
비관적 락에선 @Lock(LockModeType.PESSIMISTIC...) 을 사용한다.
DBMS 마다 다르지만 MySQL 의 경우 비관적 락 을 설정하면 쿼리 마지막에 FOR SHARE, FOR UPDATE 키워드가 붙는다.
- PESSIMISTIC_READ
FOR SHARE키워드를 사용,[UPDATE, DELETE]를 막는다. - PESSIMISTIC_WRITE
FOR UPDATE키워드를 사용,[SELECT, UPDATE, DELETE]를 막는다.
현재 스레드의Dirty Read, Lost Update를 막는다. - PESSIMISTIC_FORCE_INCREMENT
PESSIMISTIC_WRITE와 동일한 기능에 더불어 잠금 흭득시@Version을 증가시킨다.
비관적 락방식의 경우 락에 의한 교착상태가 발생가능하니 타임아웃 설정을 권장한다.
DBMS 레이어에서 Lock Timeout 을 설정해도 된다.innodb_lock_wait_timeout=50(default)
public interface OrderRepository extends CrudRepository<Order, OrderId> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
Optional<Order> findById(OrderId orderId);
@Lock(LockModeType.PESSIMISTIC_FORCE_INCREMENT)
// javax.persistence.lock.timeout
@QueryHints(@QueryHint(name = AvailableSettings.JPA_LOCK_TIMEOUT, value ="5000"))
@Query("SELECT o FROM Order o WHERE o.state = :state")
List<Order> findAllByOrderState(OrderState state);
}
-- findAllByOrderState 실행
-- 리스트 개수만큼 version update 가 추가실행된다.
select order0_.order_number as order_nu1_1_,
order0_.state as state2_1_,
order0_.version as version3_1_
from purchase_order order0_
where order0_.state = ?
for update;
update purchase_order set version=? where order_number = ? and version = ?;
update purchase_order set version=? where order_number = ? and version = ?;
...
update purchase_order set version=? where order_number = ? and version = ?;
비관적 락을 사용하는 대부분 이유가 Dirty Read 이후 이어지는 Lost Update 를 막기 위함이기 때문에 PESSIMISTIC_WRITE 를 주로 사용한다.
분산락
https://hyperconnect.github.io/2019/11/15/redis-distributed-lock-1.html
분산락(Distributed lock) 은 DB 접근을 제한하기 보다, 특정 코드접근(임계영역)을 제한하기 위한 기법이다.
분산 서버 환경으로 인해 다수의 동일한 코드가 동시 동작하고 있을 때 해당 코드영역의 동기화를 위해 접근을 제한시킬 때 분산락을 사용한다.
java 에서
syncronize사용을 최대한 피하는것 처럼, 분산락 사용을 최대한 기피해야한다.
중앙에서 Lock 을 관리해줄 별도의 서버가 필요한데, 아래와 같은 서비스를 사용해 구현 가능하다.
- Redis: Redisson
- Mysql: NamedLock(메타데이터 락)
@Repository
@RequiredArgsConstructor
public class NamedLockRepository {
private final JdbcTemplate jdbcTemplate;
public Integer getLock(String lockName, int timeout) {
// timeout 은 락을 획득하기 위해 기다리는 시간(초)
Integer result = jdbcTemplate.queryForObject(
"SELECT GET_LOCK(?, ?)",
Integer.class, // return type
lockName, timeout // params
);
return result;
}
public Integer releaseLock(String lockName) {
Integer result = jdbcTemplate.queryForObject(
"SELECT RELEASE_LOCK(?)",
Integer.class,
lockName
);
return result;
}
}
public void executeWithLock(String lockName) {
int lockStatus = lockRepository.getLock(lockName, 10);
if (lockStatus == 1) {
try {
// 락을 획득한 상태에서 실행할 작업
Thread.sleep(100);
count += 1;
log.info("Lock acquired. Executing protected code. count:{}", count);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lockRepository.releaseLock(lockName);
log.info("sLock released.");
}
} else {
log.info("Could not acquire lock.");
}
}
public void executeWithoutLock() {
try {
Thread.sleep(100);
count += 1;
log.info("Lock acquired. Executing protected code. count:{}", count);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
아래와 같이 api 100번 연속 호출시 분산락 내부 임계영역이 정확히 몇번 호출되는지 테스트하면 된다.
for i in {1..100}; do curl -s http://localhost:8080/distribute-lock/test & done; wait
아래 명령으로 현재 사용중인 메타데이터 락을 확인 가능.
SELECT * FROM performance_schema.metadata_locks;
하지만 MySQL 의 메타데이타 락 은 코드의 임계영역을 동시에 한번 실행시키진 않는다.
동일 세션의 GET_LOCK 호출은 이미 락을 흭득했다 보고 성공코드를 돌려주기 때문.
SELECT GET_LOCK('testLock', 10); 해당 코드를 같은 DB 콘솔에서 여러번 실행하면 동일 세션이기 때문에 모두 1(성공) 이 출력된다.
즉 어플리케이션 단위로 메타데이타 락 을 가져간다고 봐야한다.
어플리케이션 레이어에서 메타데이타 락 과 함께 로컬 Lock 를 관리하거나 synchronized 키워드를 사용하면 분산환경에서도 임계영역을 지정할 수 있다.
open-in-view
spring.jpa.open-in-view is enabled by default. Therefore, database queries may be performed during view rendering. Explicitly configure spring.jpa.open-in-view to disable this warning
보통 Service 에서 @Transactional 을 사용해 영속성 컨텍스트를 생성하고
Controller 나 외부 컴포넌트에선 준영속 컨텍스트가 될거라 새각하지만
open-in-view=true 의 경우 영속성 컨텍스트의 생존 법위가 스레드의 종료까지 이어진다
(REST API 의 Response 완료까지)
default true 이기 떄문에 컨트롤러에서 Lazy Loading 을 통해 엔티티를 통해 객체를 찾고 DB 에서 가져올 수 있다.
open-in-view=false 일 경우 준영속 컨텍스트에선 지연로딩 사용이 불가능하다.
지연로딩 기법을 사용한다면 @Transactional 외부에서 영속공간에 접근하는 내용을 제거해야한다.
Transaction 안에서만 Lazy Loading 을 수행할 수 있고, 컨트롤러 코드에서 접근시 no session 에러가 발생하게 된다.