Spring Boot - 배치!
Spring Batch 개요
https://docs.spring.io/spring-batch/docs/current/reference/html/index-single.html
엔터프라이즈 도메인 내의 많은 애플리케이션은 미션 크리티컬 환경에서 비즈니스 운영을 수행하기 위해 대량 처리가 필요합니다. 이러한 비즈니스 운영에는 다음이 포함됩니다.
Spring Batch는 로깅/추적, 트랜잭션 관리, 작업 처리 통계, 작업 재시작, 건너뛰기, 리소스 관리 등 대용량 레코드 처리에 필수적인 재사용 가능한 기능을 제공합니다
스프링 배치의 경우 내부구조가 복잡하여 진입장벽이 있음으로 위의 가이드 문서를 읽고 진행하는 것은 권장한다.
Spring Batch 구조
전반적인 구조는 아래 그림과 같다.
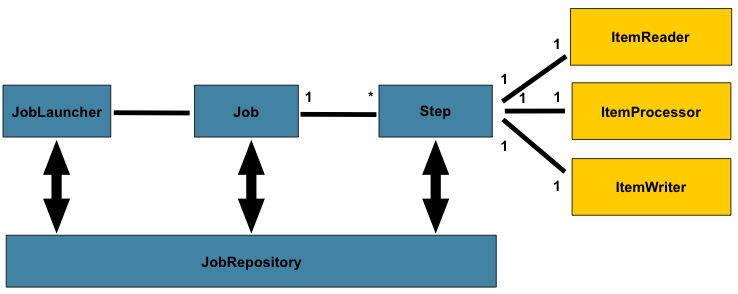
Step 은 ItemReader, ItemProcessor, ItemWriter 로 구성되고,
Job 은 여러개의 Step 으로 구성된다.
그리고 Job 의 실행시 사용한 파라미터, 실행결과 등의 메타데이터는 JobRepository 에 저장된다.
Job
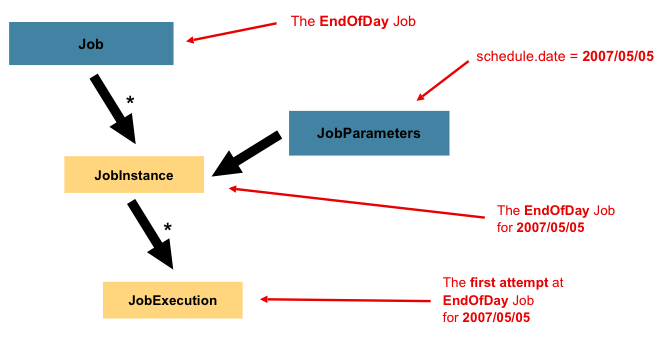
- Job
- 배치작업을 캡슐화한 엔티티로 전반적인 작업구성이 정의된다.
- JobInstance
- Job의 실행단위
Job엔티티를 기반으로 실행된다.- 시작시간과
JobParameters를 기반으로 생성된다.
- JobExecution
JobInstance인스턴스의 실행단위- 단번에 배치작업이 성공하면
JobInstance와JobExecution는 1:1 매칭된다. - 배치작업이 실패한다면 다시
JobInstance에 대한 새로운JobExecution을 생성해야 한다.
Step
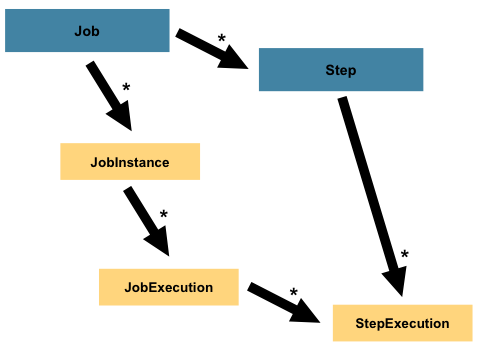
- Step
Job의 배치작업의 여러 단계를 캡슐화하는 엔티티.Job이 매우 간단해서 하나의 과정만 있다면 하나의Step으로 정의할 수 있지만 복잡하다면 여러개의Step으로 나누어 처리해야 한다.
- StepExecution
Step의 실행단위,Job하나당 N개의Step이 정의된다면JobExecution * N개 만큼 인스턴스가 생성될 수 있다.
ExcutionContext
JobExecution 부터 StepExecution 까지 계속 유지되어야할 Context(Data Map, 문맥정보) 가 필요할 때 ExcutionContext 에 데이터를 넣으면 된다.
executionContext.putLong(getKey(LINES_READ_COUNT), reader.getPosition());
...
ExecutionContext ecStep = stepExecution.getExecutionContext();
ExecutionContext ecJob = jobExecution.getExecutionContext();
//ecStep does not equal ecJob
위 코드처럼 JobExecution, StepExecution 마다 ExcutionContext 존재하며
모두 여러개의 인스턴스가 생성될 수 있는 클래스인 만큼 ExcutionContext 도 여러개의 인스턴스가 생성될 수 있다.
JobLauncher
public interface JobLauncher {
public JobExecution run(Job job, JobParameters jobParameters);
}
위와같이 Job 과 JobParameters 를 지정된 세트로 트리거 하기 위한 인터페이스
JobRepository
위에 언급한 Job, Step, ExecutionContext, JobLauncher 에 대한 데이터를 저장하고 지속하기 위한 메커니즘으로
각 추상 엔티티에 대한 CRUD 작업을 제공하여 데이터의 지속성을 유지시킨다.
내부에 의존주입받은 DAO 객체를 통해 메모리에 데이터를 지속시킬지
JPA 기반으로 데이터를 지속시킬지 설정할 수 있다.
주의: 메모리 기반 DAO 클래스들은
H2DB로 대체되어Deprecation될 예정
ItemReader, ItemProcessor, ItemWriter
ItemReader: Item 을 읽어들이기 위한 엔티티, 리소스가 여러개(DB, File, Message) 인 만큼 구현체도 여러개
ItemProcessor: Item 에 대한 비지니스 처리를 위한 엔티티
ItemWriter: Item 을 리소스에 재작성하기 위한 엔티티, 마찬가지로 리소스마다 구현체가 있음
Spring Batch 구성
Job 구성
@Bean
public Job footballJob() {
return this.jobBuilderFactory
.get("footballJob") // job name
.start(playerLoad()) // step1
.next(gameLoad()) // step2
.next(playerSummarization()) // step3
.preventRestart()
.listener(new SampleListener())
.validator(new SampleValidator())
.build();
}
preventRestart
작업 중지 혹은 실패시 다시시작 가능 여부, restartable(default true) 이기에 preventRestart 사용하여 false 로 변경 가능, JobRestartException 이 throw 된다.
listenter
JobExecutionListener 인터페이스의 구현체, 혹은 @BeforeJob, @AfterJob 어노테이션이 메서드를 통해 Job 의 필터역활을 수행가능
validator
JobParametersValidator 인터페이스의 구현체, JobParameters 의 유효성 체크, JobParametersInvalidException 이 throw 된다.
자바 구성
@EnableBatchProcessing 어노테이션은 여느 스프링의 @Eanble... 에서와 같이
다른 어노테이션들과 연계되어 여러 Bean 들을 자동 생성한다.
JobRepository,JobLauncher,JobRegistry,PlatformTransactionManager,JobBuilderFactory,StepBuilderFactory클래스가@EnableBatchProcessing어노테이션으로 인해 자동 생성된다.
Job 과 Step 을 생성하는 코드는 대략적으로 아래와 같다.
@Configuration
@EnableBatchProcessing
@Import(DataSourceConfiguration.class)
public class AppConfig {
@Autowired
private JobBuilderFactory jobs;
@Autowired
private StepBuilderFactory steps;
@Bean
public Job job(@Qualifier("step1") Step step1, @Qualifier("step2") Step step2) {
return jobs.get("myJob")
.start(step1)
.next(step2)
.build();
}
@Bean
protected Step step1(ItemReader<Person> reader,
ItemProcessor<Person, Person> processor,
ItemWriter<Person> writer) {
return steps.get("step1")
.<Person, Person> chunk(10)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
@Bean
protected Step step2(Tasklet tasklet) {
return steps.get("step2")
.tasklet(tasklet)
.build();
}
}
BatchConfigurer
스프링 배치에서 핵심구성요소
위의 @EnableBatchProcessing 에서 생성된 Bean 들은 모두 BatchConfigurer 로부터 만들어졌다 할 수 있다.
별도의 BatchConfigurer 구현체가 없다면 DefaultBatchConfigurer 가 자동으로 생성된다.
대략적인 형태는 아래와 같다.
@Component
public class DefaultBatchConfigurer implements BatchConfigurer {
private static final Log logger = LogFactory.getLog(DefaultBatchConfigurer.class);
private DataSource dataSource;
private PlatformTransactionManager transactionManager;
private JobRepository jobRepository;
private JobLauncher jobLauncher;
private JobExplorer jobExplorer;
@PostConstruct
public void initialize() {
if(dataSource == null) {
if(getTransactionManager() == null) {
this.transactionManager = ...;
}
this.jobRepository = ...;
this.jobExplorer = ...;
} else {
this.jobRepository = ...;
this.jobExplorer = ...;
}
this.jobLauncher = ...;
}
public DefaultBatchConfigurer(DataSource dataSource) {
if(this.dataSource == null) {
this.dataSource = dataSource;
}
if(getTransactionManager() == null) {
this.transactionManager = ...;
}
}
...
...
}
실제 Bean 으로 등록하는 Config 클래스는 ModularBatchConfiguration
아래와 같이 get... 을 통해 BatchConfigurer 로부터 JobRepository, JobLauncher, PlatformTransactionManager 등의 클래스를 가져와 Bean 으로 등록한다.
@Configuration(proxyBeanMethods = false)
public class ModularBatchConfiguration extends AbstractBatchConfiguration {
@Autowired
private ApplicationContext context;
@Autowired(required = false)
private Collection<BatchConfigurer> configurers;
private AutomaticJobRegistrar registrar = new AutomaticJobRegistrar();
@Override
@Bean
public JobRepository jobRepository() throws Exception {
return getConfigurer(configurers).getJobRepository();
}
@Override
@Bean
public JobLauncher jobLauncher() throws Exception {
return getConfigurer(configurers).getJobLauncher();
}
@Override
@Bean
public PlatformTransactionManager transactionManager() throws Exception {
return getConfigurer(configurers).getTransactionManager();
}
@Override
@Bean
public JobExplorer jobExplorer() throws Exception {
return getConfigurer(configurers).getJobExplorer();
}
...
}
JobRepository
BatchConfigurer 의 구현체가 생성하는 클래스 인터페이스
구현체는 SimpleJobRepository 하나밖에 없다.
public SimpleJobRepository(JobInstanceDao jobInstanceDao,
JobExecutionDao jobExecutionDao,
StepExecutionDao stepExecutionDao,
ExecutionContextDao ecDao) {
super();
this.jobInstanceDao = jobInstanceDao;
this.jobExecutionDao = jobExecutionDao;
this.stepExecutionDao = stepExecutionDao;
this.ecDao = ecDao;
}
JobInstance JobExecution, StepExecution 등의 데이터를 가지고 있다.
각
Dao클레스에 실제 데이터를 가져오기 위한SQL문
만약 DB를 사용하지 않는다면Map클래스를 조작하는 코드가 작성되어있다
스프링 배치는 데이터 지속성을 중요시하는 프레임워크이다 보니 BatchConfigurer 에 DataSource 를 지정하고 JDBC 기반의 JobRepository 를 많이 사용한다.
DefaultBatchConfigurer 에서 DataSource 가 있을경우 JobRepository 를 생성은 JobRepositoryFactoryBean 통해 진행된다.
// BatchConfigurer implements
protected JobRepository createJobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setTransactionManager(getTransactionManager());
factory.afterPropertiesSet();
return factory.getObject();
}
DataSource 가 없을경우
MapJobRepositoryFactoryBean을 사용Deprecated예정, 인메모리 DB 를 사용하도록 권장하여JobRepositoryFactoryBean단독사용으로 변경될 예정이다.
JobLauncher
실제 Job 클래스로 JobInstance 를 생성하는 클래스
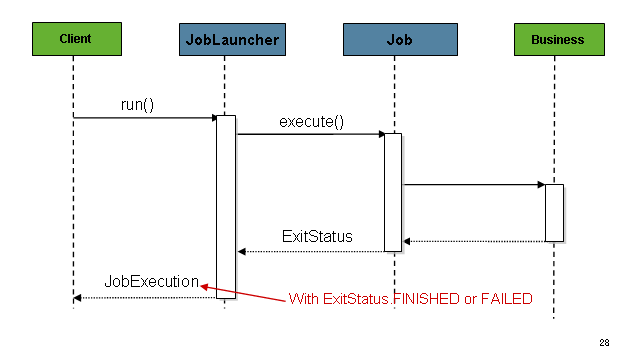
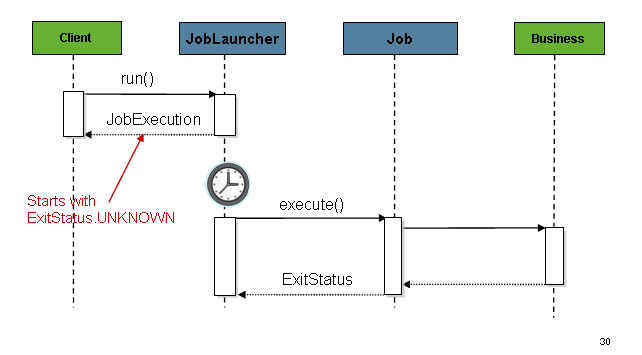
그림처럼 JobLauncher 는 동기/비동기 적으로 실행될 수 있다.
작업이 끝나면 성공 실패여부를 떠나 JobExecution 이 발생하게 되고 호출된곳에 반환되는데
동작기간이 긴 배치프로세스의 경우 비동기로 실행해야한다.
바로
JobExecution의ExitStatus를UNKNOWN으로 설정해서throw해버린다.
기본적으로 동기방식의 TaskExcecutor 를 사용하며 비동기로 동작시키고 싶을경우 아래 코드 주석처럼 SimpleAsyncTaskExecutor 를 삽입하면 된다.
// BatchConfigurer implementation
@Override
protected JobLauncher createJobLauncher() throws Exception {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(jobRepository);
// jobLauncher.setTaskExecutor(new SimpleAsyncTaskExecutor()); // 비동기 task 로 설정
jobLauncher.afterPropertiesSet(); // task 가 없다면 SyncTaskExecutor 사용
return jobLauncher;
}
실행
스프링 배치를 실행시키는 방법은 두가지
- CLI 커맨드 -
CommandLineJobRunner - 서버로 운영, 이벤트 호출
먼저 CLI 커맨드로 배치 프로세스를 실키는 방법을 알아보자.
org.springframework.batch.core.launch.support 에 정의된 CommandLineJobRunner 을 사용한다.
아래와 같은 Job 이름 endOfDay 가 있을 때
@Configuration
@EnableBatchProcessing
public class EndOfDayJobConfiguration {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Bean
public Job endOfDay() {
return this.jobBuilderFactory.get("endOfDay")
.start(step1())
.build();
}
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.tasklet((contribution, chunkContext) -> null)
.build();
}
}
CLI 커맨드로 실행시키는 방법은 아래와 같다.
$ java CommandLineJobRunner \
io.spring.EndOfDayJobConfiguration endOfDay \
schedule.date(date)=2007/05/05
CommandLineJobRunner 이우에 붙는 매개변수는 아래와 같이 나뉜다.
Full Class Name
Job의Config클래스Job Name실행시킬Job이름JobParameterskey=value형식으로 이루어짐
CLI 커맨드로 실행시키는 방식은 OS 자체에 포함된 스케줄러 (crontab 등) 이 주로 사용되기에 싱크형식의 배치 프로세스를 사용하고 반환코드(ExitCode) 가 존재한다.
대부분 0=success, 1=failed 를 사용한다.
만약 더 복잡한 종료코드를 설정해야한다면 ExitCodeMapper 를 구현 후
ApplicationContext 가 확인할 수 있도록 루트수준 Bean 으로 등록하면 된다.
public interface ExitCodeMapper {
public int intValue(String exitCode);
}
JobExecution 이 반환하는 exitCode 를 확인후 int 값으로 변경하여 CLI 커맨드로 반환한다.
서버에서 배치를 실행하는 방법은 jobLauncher 의 run 메서드만 실행하면 된다.
@Controller
public class JobLauncherController {
@Autowired
JobLauncher jobLauncher;
@Autowired
Job job;
@RequestMapping("/jobLauncher.html")
public void handle() throws Exception{
jobLauncher.run(job, new JobParameters());
}
}
서버에서 실행하는 경우는 Async 방식을 주로 쓴다.
Step 구성
Spring Batch 구조 그림을 보면 Step 은 ItemReader, ItemProcessor, ItemWriter 로 구성된다.
시퀀스 다이어 그램을 보면 n번의 read, n번의 process, m번의 wirte 가 이루어진다.
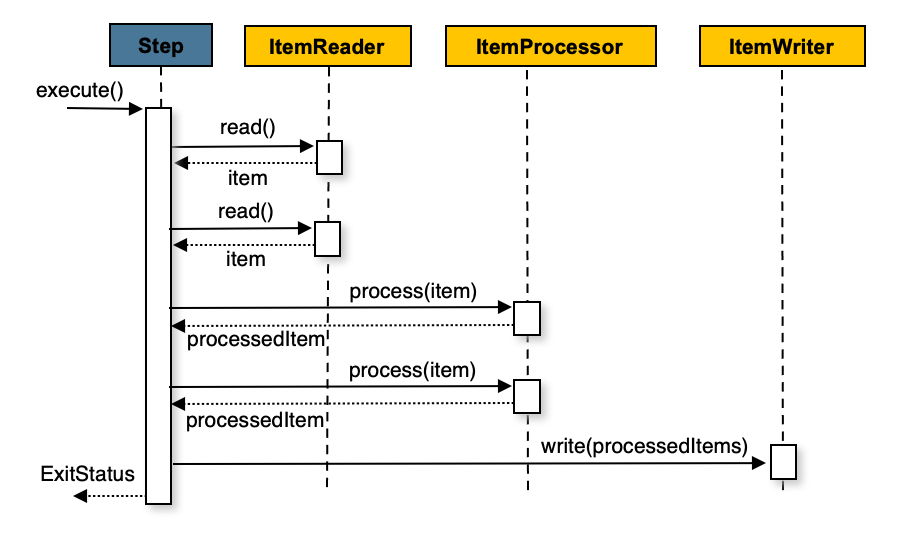
마지막에 Step 의 종료코드 ExitStatus 를 반환함으로 끝이난다.
StepBuilderFactory
지금까지 jobBuilderFactory 에서 next 메서드를 사용해 이미 생성된 Step 을 삽입해왔는데
이번엔 stepBuilderFactory 에서 Step 을 구성하는것을 알아본다.
DefaultTransactionAttribute attribute = new DefaultTransactionAttribute();
attribute.setPropagationBehavior(Propagation.REQUIRED.value());
attribute.setIsolationLevel(Isolation.DEFAULT.value());
attribute.setTimeout(30);
@Bean
public Step sampleStep(PlatformTransactionManager transactionManager) {
return this.stepBuilderFactory.get("sampleStep")
.transactionManager(transactionManager)
.<String, String>chunk(10)
.reader(itemReader())
.processor(itemProcessor())
.writer(itemWriter())
.readerIsTransactionalQueue()
.transactionAttribute(attribute)
.faultTolerant()
.retryLimit(3)
.retry(DeadlockLoserDataAccessException.class)
.skipLimit(10)
.skip(Exception.class)
.noSkip(FileNotFoundException.class)
.noRollback(ValidationException.class)
.allowStartIfComplete(true)
.startLimit(1)
.build();
}
transactionManager
스프링 부트의 트랜잭션 매니저 설정, BatchConfigurer 에서도 사용함
chunk
item-base 의 SimpleStepBuilder 를 반환하며 아래의 reader, processor, writer 함수를 쓸 수 있게 된다. 트랜잭션이 커밋되기 전에 처리할 항목 수 지정 가능.
reader, processor, writer
ItemReader ItemWriter ItemProcessor 적용
readerIsTransactionalQueue
readerIsTransactionalQueue 를 지정하면 향후 에러가 발생해 롤백할 경우에도 큐에서 데이터를 꺼내와 바로 덮어 씌울 수 있도록 한다.
transactionAttribute
isolation, propagation, timeout 설정,
repository
StepExecution and ExecutionContext 등의 Step Context(Data Map) 를 주기적으로 저장할 JobRepository, BatchConfigurer 에서도 사용함
skip, noSkip, skipLimit
faultTolerant() 함수로부터 시작, 오류발생 시 Step 의 skip 여부 결정, reader, writer, processor 어디서든 예외발생 가능하며 발생시 다음 chuck 로 이동, skipLimit 개수에 다다르면 예외가 발생하며 step 이 실패처리된다.
retry, retryLimit
faultTolerant() 함수로부터 지삭, 오류발생 시 Step 의 retry 여부 걸졍, 재시도할 예외를 지정 가능
noRollback
faultTolerant() 함수로부터 지삭, 오류발생시 ItemWriter 작성한 내용에 대해 롤백하지 않음
startLimit
allowStartIfComplete() 함수로부터 시작, 성공 혹은 오류로 종료된 Step 을 다시 실행할 것인지 여부, true 로 설정하면 이 항상 실행되도록 설정한다.
startLimit 의 default 값은 Integer.MAX_VALUE
default 값은 false
한번 실행 후 더이상 실행하지 못하도록 설정할 때 사용할 수 있다.
Intercept Step Function
다음과 같은 step 이 있을 때
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(10)
.reader(reader())
.writer(writer())
.listener(myListner)
.build();
}
myListner 의 종류는 아래와 같다.
함수명 대신 어노테이션으로 대체 가능
public interface StepExecutionListener extends StepListener {
void beforeStep(StepExecution stepExecution);
ExitStatus afterStep(StepExecution stepExecution);
}
public interface ChunkListener extends StepListener {
void beforeChunk(ChunkContext context);
void afterChunk(ChunkContext context);
void afterChunkError(ChunkContext context);
}
public interface ItemReadListener<T> extends StepListener {
void beforeRead();
void afterRead(T item);
void onReadError(Exception ex);
}
public interface ItemProcessListener<T, S> extends StepListener {
void beforeProcess(T item);
void afterProcess(T item, S result);
void onProcessError(T item, Exception e);
}
public interface ItemWriteListener<S> extends StepListener {
void beforeWrite(List<? extends S> items);
void afterWrite(List<? extends S> items);
void onWriteError(Exception exception, List<? extends S> items);
}
public interface SkipListener<T,S> extends StepListener {
void onSkipInRead(Throwable t);
void onSkipInProcess(T item, Throwable t);
void onSkipInWrite(S item, Throwable t);
}
특히나 StepExecutionListener 의 경우 향후 Step 흐름제어에서 사용하는 ExitStatus 를 처리하는 Listener 이기에 자주 사용된다.
TaskletStep
chunk 기반의 ItemReader ItemProcessor ItemWriter 로 Step 을 구성할 수 있지만
item read 는 하지 않고 item write 만 하는 등 chuck 프로세스에 어울리지 않는 배치작업이 있을 수 있다.
이때 execute 메서드 하나로만 구성되는 Tasklet 클래스를 step 에 사용하면 좀더 직관적으로 코드를 작성할 수 있다.
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.tasklet(myTasklet())
.build();
}
Tasklet 의 구조는 아래와 같다.
public interface Tasklet {
RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception;
}
위 Tasklet 인터페이스를 구현한 여러 어뎁터클래스가 있으며 그중 MethodInvokingTaskletAdapter 클래스를 보면
@Bean
public MethodInvokingTaskletAdapter myTasklet() {
MethodInvokingTaskletAdapter adapter = new MethodInvokingTaskletAdapter();
adapter.setTargetObject(fooDao());
adapter.setTargetMethod("updateFoo");
return adapter;
}
Step 흐름제어
단순 start(), next() 메서드를 사용하면 성공 실패 상관없이 step 은 순차적으로 실행된다.
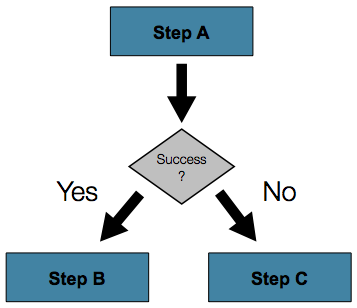
만약 위 그림과 같이 Step 의 ExitStatus 에 따라 Step 실행에 조건을 두고 싶다면
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(stepA()).on("*").to(stepB()) // *: all condition
.from(stepA()).on("FAILED").to(stepC())
.end()
.build();
}
on, from, to, end 등 여러가지 제어 함수, 그리고 Step 이 반환하는 ExitStatus 를 기반으로 step 의 흐름제어가 가능하다.
BatchStatus vs ExitStatus
BatchStatus 는JobExecution, StepExecution모두 에서 발생가능한 enum 형태의 데이터COMPLETED, STARTING, STARTED, STOPPING, STOPPED, FAILED, ABANDONED, UNKNOWNExitStatus(String) 는
StepExecution에서 반환하는 문자열 형태의 종료코드,StepExecutionListener애서 처리 생성 문자열이지만 기본적으로 사용하는 고정 문자열들이ExitStatus클래스에 정의되어 있으며Step의 기본 종료코드로 사용됨헷갈리면 안되는게
ExitStatus가 모두FAILED라고 해도BatchStatus는COMPLETED일 수 있다.
흐름제어를 진행하는 함수의 목록은 아래와 같다.
on()
ExitStatus 의 pattern matching 통해 다음 흐름의 실행여부 결정, *, ? 두가지 와일드카드 문자 사용
end()
흐름을 종료시키고 ExitStatus=COMPLETE, BatchStatus=COMPLETE 변환
fail()
흐름을 종료시키고 ExitStatus=EARLY TERMINATION, BatchStatus=COMPLETE 변환
stopAndRestart()
이전 흐름을 ExitStatus=COMPLETE 로 변경, BatchStatus=STOPPED 변환, 사용자의 추가 개입이 필요할 때 사용
Flow
Step 모음을 Flow 객체로 표기
@Bean
public Flow flow1() {
return new FlowBuilder<SimpleFlow>("flow1")
.start(step1())
.next(step2())
.build();
}
@Bean
public Flow flow2() {
return new FlowBuilder<SimpleFlow>("flow2")
.start(step3())
.build();
}
@Bean
public Job job(Flow flow1, Flow flow2) {
return this.jobBuilderFactory.get("job")
// SimpleAsyncTaskExecutor 로 step 동시실행
.start(flow1).split(new SimpleAsyncTaskExecutor())
.add(flow2)
.next(step4())
.end()
.build();
}
Meta Table
https://docs.spring.io/spring-batch/docs/current/reference/html/index-single.html#metaDataSchema
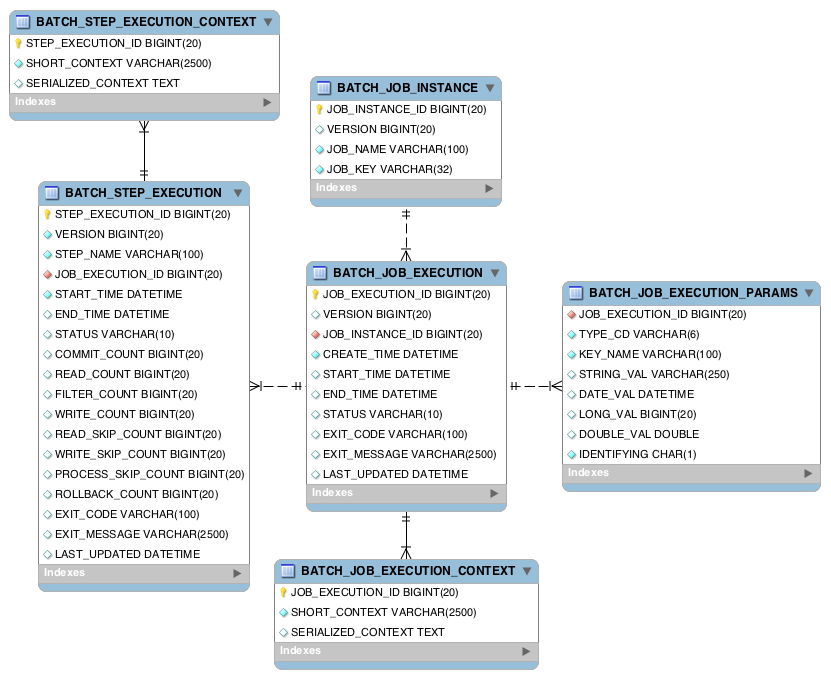
Spring Batch 의 기능들을 수행하기 위해 필수적인 메타테이블이 필요하며
ERD는 위와 같다.
org.springframework.batch.core 에 스프링 배치가 지원하는 DB 별로 schema-*.sql DDL 스크립트가 저장되어 있다.
-- JobInstance 관련 데이터 저장,
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT PRIMARY KEY , -- 식별 ID
VERSION BIGINT , -- 버전, 업데이트될 때 마다 증가
JOB_NAME VARCHAR(100) NOT NULL , -- Job 개체 이름
JOB_KEY VARCHAR(32) NOT NULL -- Job 인스턴스 고유키
);
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
JOB_EXECUTION_ID BIGINT NOT NULL ,
TYPE_CD VARCHAR(6) NOT NULL ,
KEY_NAME VARCHAR(100) NOT NULL ,
STRING_VAL VARCHAR(250) ,
DATE_VAL DATETIME DEFAULT NULL ,
LONG_VAL BIGINT ,
DOUBLE_VAL DOUBLE PRECISION ,
IDENTIFYING CHAR(1) NOT NULL ,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
);
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT PRIMARY KEY ,
VERSION BIGINT,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME TIMESTAMP NOT NULL,
START_TIME TIMESTAMP DEFAULT NULL,
END_TIME TIMESTAMP DEFAULT NULL,
STATUS VARCHAR(10),
EXIT_CODE VARCHAR(20),
EXIT_MESSAGE VARCHAR(2500),
LAST_UPDATED TIMESTAMP,
JOB_CONFIGURATION_LOCATION VARCHAR(2500) NULL,
constraint JOB_INSTANCE_EXECUTION_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
);
CREATE TABLE BATCH_STEP_EXECUTION (
STEP_EXECUTION_ID BIGINT PRIMARY KEY ,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
START_TIME TIMESTAMP NOT NULL ,
END_TIME TIMESTAMP DEFAULT NULL,
STATUS VARCHAR(10),
COMMIT_COUNT BIGINT ,
READ_COUNT BIGINT ,
FILTER_COUNT BIGINT ,
WRITE_COUNT BIGINT ,
READ_SKIP_COUNT BIGINT ,
WRITE_SKIP_COUNT BIGINT ,
PROCESS_SKIP_COUNT BIGINT ,
ROLLBACK_COUNT BIGINT ,
EXIT_CODE VARCHAR(20) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED TIMESTAMP,
constraint JOB_EXECUTION_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
);
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
JOB_EXECUTION_ID BIGINT PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT CLOB,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
);
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
STEP_EXECUTION_ID BIGINT PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT CLOB,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
);
– 작성중 –