python 자료형, 제어문, 함수!
설치
brew install python@3.10
# ~/.zshrc 에 아래와 같이 경로 및 별칭 지정
export PATH=$PATH:/opt/homebrew/bin
alias python3=python3.10
alias python=python3.10
alias pip3=pip3.10
alias pip=pip3.10
# Mac 에서 기본적으로 사용하는 파이썬, 삭제 불가능하며 파이썬 관련 프로그램이 해당 바이너리를 사용함.
/usr/bin/python3 -V
Python 3.9.6
자료형
a = 'python'
name: str = "Alice"
age: int = 30
height: float = 5.7
is_student: bool = True
byte_str: bytes = b"Hello, World!"
python 에서는 원시타입 개념이 없고 모두 객체로 취급된다.
# buildins.py
class int(object):
"""
int([x]) -> integer
int(x, base=10) -> integer
문자열
a: str = 'python'
# 문자열 연산
a * 2 # pythonpython
"=" * 50 # ==================================================
'hi' + 3 # TypeError: can only concatenate str (not "int") to str
# 오히려 될것 같은건 안됨
# 문자열 인덱스
a[3] # 'h'
a[-2] # 'o' 뒤에서 2번째
# 문자열 포멧팅
"hello %s" % "wolrd" # 'hello wolrd'
"hello %02d" % 3 # 'hello 03'
"hello {0}".format("world") # 'hello world'
"my name is {name} and {age} age".format(name="kouzie", age=20)
# 'my name is kouzie and 20 age'
# f-string을 사용한 문자열 포매팅
greeting = f"my name is {name} and {age} age"
# 문자열 리스트
string_list = ["test", "print", "hello"]
# 언더스코어로 구분된 문자열로 결합
print('_'.join(string_list)) # 출력: test_print_hello
# 슬라이싱 구문
# [시작:끝:스텝] 형태의 연산자
# 문자열 슬라이스
a[0:3] # 'pyt' 마지막 index 는 열린구간으로 인식됨(불포함)
a[:3] # 'pyt' default start 0
a[3:] # 'hon' defatlt end EOL
a[1:-1] # 'ytho', 1 ~ 마지막인덱스까지
# 스텝 연산
a: str = 'python'
print(a[::1]) # python
print(a[::2]) # pto
print(a[::3]) # ph
print(a[::-1]) # nohtyp
print(a[::-2]) # nhy
typing
python 3.9(2019) 이전 버전에서는 list, tuple, dict, set 에 요소타입을 명시할수 없어 타입힌트를 쓸수 없었다.
그래서 아래와 같이 typing 에서 제공하는 제너릭타입 클래스를 사용해야 했다.
from typing import List, Tuple, Dict, Set
my_list: List[int] = [1, 2, 3]
my_tuple: Tuple[int, str] = (1, "hello")
my_dict: Dict[str, int] = {"one": 1, "two": 2}
my_set: Set[int] = {1, 2, 3}
python 3.9 이후부터는 기본 빌트인 자료형에서 제공하는 자료형에서도 타입힌트를 쓸 수 있게 되었다.
my_list: list[int] = [1, 2, 3]
my_tuple: tuple[int, str] = (1, "hello")
my_dict: dict[str, int] = {"one": 1, "two": 2}
my_set: set[int] = {1, 2, 3}
list
# 리스트 생성
b: list[int] = [4, 5, 6]
# 생성자로 iterable 객체를 받을 수 있음
b: list[int] = list(map(lambda x: x ** 2, b))
print(b) # [16, 25, 36]
print(list("10010101")) # ['1', '0', '0', '1', '0', '1', '0', '1']
list([iterable]) 함수를 사용해 반복 가능한 객체(str, tuple, dict, set, range) 를 list 화 할 수 있다.
# 리스트 연산
a: list[int] = [1,2,3]
b: list[int] = [4,5,6]
print(a+b) # [1, 2, 3, 4, 5, 6]
print(a*2) # [1, 2, 3, 1, 2, 3]
a.extend(b)
print(a) # [1, 2, 3, 4, 5, 6]
c = [1, 2, 3]
d = [4, 5, 6]
e = [*c, *d]
print(e) # [1, 2, 3, 4, 5, 6]
# 요소 탐색
b = ['a', 'b', 'c', 'd', 'c', 'c']
b.index('c') # 2, first index
b.count('c') # 3, 개수
# 요소 탐색 by index
my_list = [1, 2, 3, 4, 5]
print(my_list[-1]) # 5
print(my_list[-2]) # 4
print(my_list[-3]) # 3
# 요소 추가
a = [1,2,3]
a.append(4) # [1, 2, 3, 4]
a.insert(0,5) # [5, 1, 2, 3, 4] (index, value)
# 요소 삭제
b = [4, 5, 6, 7]
b.remove(5) # 요소삭제
del b[2:] # [4, 6]
r = b.pop() # r=6 b=[4]
b = [4, 5, 6, 7]
b.pop(-2) # [4, 5, 7]
# 요소 정렬
a = [2,3,1,4]
b = ['b','c','a','d']
a.sort() # [1, 2, 3, 4]
b.sort() # ['a', 'b', 'c', 'd']
b.reverse() # ['d', 'c', 'b', 'a']
# 슬라이스 연산, 문자열 슬라이스와 동일함
my_list = [0, 1, 2, 3, 4, 5]
print(my_list[:1]) # [0]
print(my_list[:2]) # [0, 1]
print(my_list[:-1]) # [0, 1, 2, 3, 4]
print(my_list[0:]) # [0, 1, 2, 3, 4, 5]
print(my_list[1:]) # [1, 2, 3, 4, 5]
print(my_list[1:1]) # []
print(my_list[1:2]) # [1]
print(my_list[1:3]) # [1, 2]
# 2단계씩
print(my_list[::2]) # [0, 2, 4]
# 거꾸로
print(my_list[::-1]) # [5, 4, 3, 2, 1, 0]
dict
# 추가
a: dict[str] = {"hi": "hello"}
a["who"] = "me" # {'hi': 'hello', 'who': 'me'}
# 삭제
del a['hi'] # {'who': 'me'}
a.clear() # { } 초기화
# 조회
a = {'hi': 'hello', 'who': 'me'}
a.keys() # dict_keys(['hi', 'who'])
a.values() #dict_values(['hello', 'me'])
a.items() # dict_items([('hi', 'hello'), ('who', 'me')])
list(a.keys()) # ['hi', 'who'] # 리스트로 변환
list(a.values()) # ['hello', 'me']
list(a.items()) # [('hi', 'hello'), ('who', 'me')] # 튜플에 대한 리스트
items = a.items()[0][0] # 'hi'
tuple, set
tuple: immutable list, () 기호를 사용해 생성한다.
set: 중복없는 list, 집합자료형, {} 기호를 사용해 생성한다.
t: tuple[int] = (1,2,3)
s: set[int] = {1,2,3}
# list to tuple, set
t = tuple([1,2,3])
s = set([1,2,3])
print(t[0]) # 1
# set 연산
s1: set[int] = {1,2,3,4}
s2: set[int] = {3,4,5,6}
s1 & s2 # 교집합: {3, 4}
s1 | s2 # 합집합: {1, 2, 3, 4, 5, 6}
s1 - s2 # 차집합: {1, 2}
# set 요소 추가
s1 = {1,2,3,4}
s1.add(5) # {1, 2, 3, 4, 5}
s1.update([6,7,8]) # {1, 2, 3, 4, 5, 6, 7, 8}
# set 요소 삭제
s1.remove(3) # (index)
s1.pop()
typing - 고급타입힌트
Union, Optional, Any 와 같은 고급 타입 힌트를 사용할 경우 여전히 typing 을 사용해야한다.
Union
Union은 여러 타입을 하나로 결합하여 사용, 변수나 함수 인자가 여러 타입을 가질 수 있음을 나타낼 때 사용한다.
def process(data: Union[int, str]) -> None:
if isinstance(data, int):
print(f"Processing an integer: {data}")
else:
print(f"Processing a string: {data}")
process(10) # Processing an integer: 10
process("hello") # Processing a string: hello
python 3.10 이후부턴 | 연산자를 통해 Union 대체가 가능하다.
def toString(num: int | float) -> str:
return str(num)
Optional
Python 에서 null 을 뜻하는 None 타입과 같이 사용된다.
Optional[str] 는 Union[str, None]과 동일.
x = None
print(x) # None
print(type(x)) # <class 'NoneType'>
from typing import Optional
def greet(name: Optional[str] = None) -> str:
if name is None:
return "Hello, Stranger!"
else:
return f"Hello, {name}!"
print(greet()) # Hello, Stranger!
print(greet("Alice")) # Hello, Alice!
Any
from typing import Any
def process(data: Any) -> None:
print(f"Processing data: {data}")
process(10) # Processing data: 10
process("hello") # Processing data: hello
process([1, 2, 3]) # Processing data: [1, 2, 3]
Type, TypeVar
Type: 타입 힌트를 작성할 때 사용
TypeVar: 제네릭 타입을 정의할 때 사용
from typing import Type, TypeVar
class Animal:
pass
class Dog(Animal):
pass
T = TypeVar('T')
A = TypeVar('A', bound=Animal)
def create_instance(cls: Type[A]) -> A:
return cls()
def get_first_element(lst: list[T]) -> T:
return lst[0]
if __name__ == '__main__':
# Type 사용 예시
dog_instance = create_instance(Dog)
# TypeVar 사용 예시
int_list = [1, 2, 3]
str_list = ['a', 'b', 'c']
first_int: int = get_first_element(int_list)
first_str: str = get_first_element(str_list)
print(first_int, first_str) # 1 a
제어문
if, elif, else
x = True
y = False
if x:
print("hi")
elif y:
print("hello")
else:
print("world")
bool 자료형 끼리는 and, or, not
x and y # False
x or y # True
not y # True
리스트, 튜플을 검사할 땐 in, not in
1 in [1,2,3] True
1 not in [2,3,4] True
삼항연산자
# value_when_true if condition else value_when_false
x = 10
y = 20
# x가 y보다 큰지 확인하고, 결과에 따라 다른 값을 할당
result = "x is greater" if x > y else "y is greater or equal"
print(result)
while
while x:
if y:
break
if z:
continue
파이썬에는 do while 없음
for - list, tuple, dict
# list 순회
for item in [1, 2, 3, 4, 5]:
print(item)
# tuple 순회
for item in (1, 2, 3, 4, 5):
print(item)
person = {"name": "Alice", "age": 30, "city": "New York"}
# dict 키-값 순회
for key, value in person.items():
print(f"{key}: {value}")
# dict 키 순회
for key in person:
print(key)
# dict 값 순회
for value in person.values():
print(value)
# str 순회
for char in "hello":
print(char)
for - range, enumerate, zip
# 0부터 4까지 순회
for i in range(5):
print(i)
# 1부터 5까지 순회
for i in range(1, 6):
print(i)
# 1부터 9까지 2씩 증가하며 순회
for i in range(1, 10, 2):
print(i)
names: list[str] = ["Alice", "Bob", "Charlie"]
scores: list[int] = [85, 90, 95]
for name in enumerate(names):
print(f"Name: {name}")
for name, score in zip(names, scores):
print(f"Name: {name}, Score: {score}")
참고로 range, enumerate, zip 는 함수 아니고 iterable 가능한 객체임
names: list[str] = ["Alice", "Bob", "Charlie"]
scores: list[int] = [85, 90, 95]
my_enumerate: enumerate[str] = enumerate(names)
my_zip: zip = zip(names, scores) # 내부 요소 typehint 안됨
my_range: range = range(5) # 내부 요소 typehint 안됨
for - 컴프리헨션
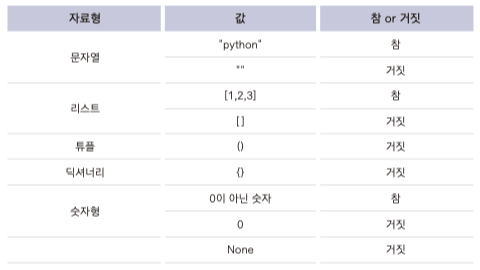
# 기본 for 문을 사용한 리스트 생성
squares = []
for x in range(10):
squares.append(x**2)
# 리스트 컴프리헨션을 사용한 리스트 생성
squares = [x**2 for x in range(10)]
print(squares) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
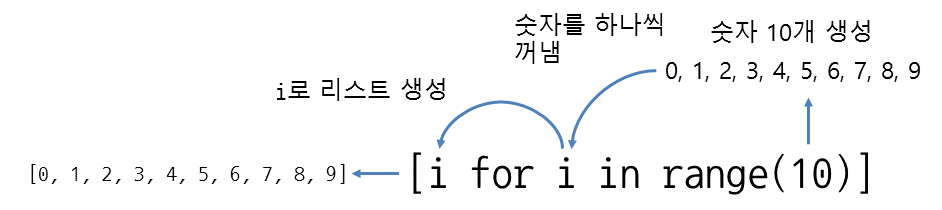
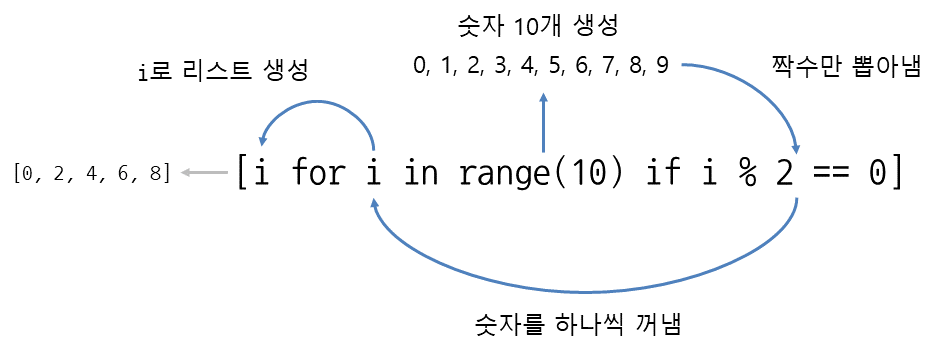
# 3 나머지가 0인 요소만 처리
# 0, 3, 6, 9 만 expression 에 넣는다
th_squares = [x ** 2 for x in range(10) if x % 3 == 0]
print(th_squares) # [0, 9, 36, 81]
arr = [[0] * (N + 1)] + [[0] + list(map(int, input().split())) for _ in range(N)]
컴프리헨션은 아래와 같은 형태로 구성된다.
list = [{expression} {for item in iterable} {if condition}]
진행 순서: {for item in iterable} → {if condition} → {expression}
# 중첩된 리스트 컴프리헨션을 사용한 리스트 생성
my_list = [i * j for j in range(2, 10) for i in range(1, 10)]
print(len(my_list)) # 72
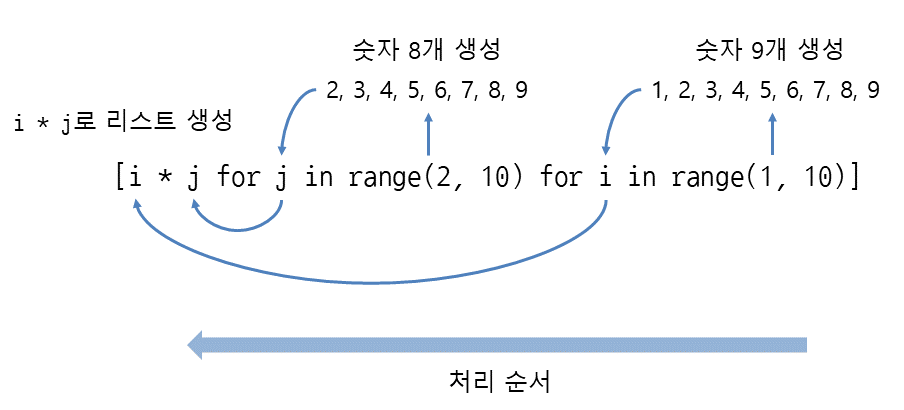
1 ~ 9, 2 ~ 9 두개 숫자 조합으로 총 72개의 요소가 생성될 수 있다.
보통 아래와 같이 2차원 배열을 만들 때 많이 사용한다.
matrix = [[i * j for j in range(3)] for i in range(3)]
print(matrix) # [[0, 0, 0], [0, 1, 2], [0, 2, 4]]
list 외에도 dict, set 에서도 컴프리헨션 문법 적용이 가능하다.
# 키와 값을 동일하게 설정한 딕셔너리 생성
square_dict = {x: x**2 for x in range(5)}
print(square_dict) # {0: 0, 1: 1, 2: 4, 3: 9, 4: 16}
# 각 요소를 제곱하여 새로운 집합 생성
square_set = {x**2 for x in range(10)}
print(square_set) # {0, 1, 4, 9, 16, 25, 36, 49, 64, 81}
아래와 같이 코테에서 2차원 배열 생성할 때 자주 사용함.
import io
import sys
# Input 문자열 정의
input_str = """3 3
1 2 3
4 5 6
7 8 9
"""
# StringIO 객체를 생성하고 이를 stdin으로 설정
sys.stdin = io.StringIO(input_str)
# 이후 기존 코드 그대로 사용
N, M = map(int, input().split())
arr = [list(map(int, input().split())) for _ in range(N)]
# 결과 출력 (테스트용)
print(N, M)
print(arr)
match, case
python 3.10 이후 추가된 문법, switch 문 역할을 수행하는 제어문
이전에는 모두 if-elif-else 로 처리했어야함.
함수
def add1(a=1, b=1):
return a + b
# 반환타입 명시
def add2(a=1, b=1) -> int:
return a + b
add1() # 2
add2(b=2,a=5) # 7
python 은 별도의 반환값, 매개변수의 인자값 등을 생략해도 된다.
함수 또한 객체로 취급되며 다양한 메타데이터들을 가지고 있다.
def foobar():
"""foo~~bar~~"""
print("baz")
if __name__ == '__main__':
print(type(foobar)) # <class 'function'>
print("Docstring:", foobar.__doc__) # foo~~bar~~
print("Name:", foobar.__name__) # foobar
print("Module:", foobar.__module__) # __main__
print("Defaults:", foobar.__defaults__) # ('default',)
print("Code:", foobar.__code__) # <code object foobar at 0x...>
print("Globals:", foobar.__globals__) # {...}
print("Closure:", foobar.__closure__) # None
print("Annotations:", foobar.__annotations__) # {'x': <class 'int'>, 'y': <class 'str'>, 'return': <class 'NoneType'>}
print("KW Defaults:", foobar.__kwdefaults__) # None
print("Dict:", foobar.__dict__) # {}
가변인자, 키워드인자
가변 인자
def add_all(*args):
result = 0
for i in args:
result += i
return result
키워드인자
def example_function(**kwargs):
for key, value in kwargs.items():
print(f"{key}: {value}")
example_function(name="Alice", age=30, city="New York")
# name: Alice
# age: 30
# city: New York
가변인자 + 키워드인자
def example_function(*args, **kwargs):
print("Positional arguments:", args)
print("Keyword arguments:", kwargs)
print(type(args)) # <class 'tuple'>
print(type(kwargs)) # <class 'dict'>
example_function(1, 2, 3, name="Alice", age=30)
# 출력:
# Positional arguments: (1, 2, 3)
# Keyword arguments: {'name': 'Alice', 'age': 30}
python 문법에서 가변인자는 항상 키워드인자 앞에 있어야 한다.
파이썬에는 메서드오버로딩 을 지원하지 않기때문에 생성자나 함수에 여러개의 변수를 받아야 할 경우 *args, **kwargs 를 매개변수를 적극적으로 사용해야한다.
map
고차 함수 map 의 결과로 생성되는 iterator 객체.
데이터 처리의 지연 평가(lazy evaluation) 특성을 가지고 있어 메모리 효율적이다.
result = map(int, "10010101")
print(type(result)) # Output: <class 'map'>
아래와 같이 str 로 반환되는 문자열을 int 로 변환하여 map 객체로 변환하고 list 로 넘겨 쉽게 숫자 list 생성이 가능하다.
print(list(map(int, "10010101"))) # [1, 0, 0, 1, 0, 1, 0, 1]
한 번만 소비 가능하여 한 번 순회하거나 변환하면 소진된다.
nums = [1, 2, 3]
squared = map(lambda x: x**2, nums)
print(list(squared)) # [1, 4, 9]
print(list(squared)) # []
for 컴프리핸션은 한번에 모든 요소를 순회해야 하지만 map 의 경우 요청시에 연산이 가능하기 때문에 좀더 효율적이다.
nums = range(1, 1_000_000) # 큰 입력
squared = map(lambda x: x**2, nums)
# 값 하나씩 생성
print(next(squared)) # 1
print(next(squared)) # 4
람다, filter, reduce, sorted
# lambda arguments: expression
add = lambda x, y: x + y
print(add(3, 5)) # 8
# 두 숫자의 합을 계산하는 람다 함수
add = lambda x, y: x + y
print(add(3, 5)) # 8
# 리스트의 각 요소를 제곱
numbers = [1, 2, 3, 4, 5]
squared = list(map(lambda x: x ** 2, numbers))
print(squared) # [1, 4, 9, 16, 25]
# 리스트에서 짝수만 필터링
numbers = [1, 2, 3, 4, 5, 6]
evens = list(filter(lambda x: x % 2 == 0, numbers))
print(evens) # [2, 4, 6]
# 리스트의 모든 요소의 곱을 계산
from functools import reduce
numbers = [1, 2, 3, 4, 5]
product = reduce(lambda x, y: x * y, numbers)
print(product) # 120
# 튜플의 리스트를 두 번째 요소를 기준으로 정렬
points = [(1, 2), (3, 1), (5, 7), (2, 3)]
sorted_points = sorted(points, key=lambda point: point[1])
print(sorted_points) # [(3, 1), (1, 2), (2, 3), (5, 7)]
고차함수 - 함수를 인자로
def apply_function(func, x, y):
return func(x, y)
def add(a, b):
return a + b
if __name__ == '__main__':
result = apply_function(add, 2, 3)
print(result) # 5
typing 의 Callable 을 사용하면 타입힌트를 적용할 수 있다.
# 두 개의 int를 받아 int를 반환하는 함수를 인자로 받는 함수
def apply_function(func: Callable[[int, int], int], x: int, y: int) -> int:
return func(x, y)
def add(a: int, b: int) -> int:
return a + b
if __name__ == '__main__':
result1 = apply_function(add, 4, 5)
print(result1) # 9
result2 = apply_function(lambda x, y: x * y, 4, 5)
print(result2) # 20
변수 scope
파이썬도 타 언어와 같이 변수의 정의된 위치에 따라 scope 를 가지는데, global, local 두개로 나뉜다.
global: 모듈단위local: 함수단위
함수 중첩시
nonlocalscope도 존재하긴 한다.
global_var = "전역 변수"
def outer():
nonlocal_var = "비전역 변수"
print(global_var) # 가능
print(nonlocal_var) # 가능
def inner():
local_var = "지역 변수"
print(global_var) # 가능
print(nonlocal_var) # 가능
print(local_var) # 가능
print(local_var) # 불가능 (NameError: name 'local_var' is not defined)
print(nonlocal_var) # 불가능 (NameError: name 'nonlocal_var' is not defined)
print(local_var) # 불가능 (NameError: name 'local_var' is not defined)
이때 scope 를 명확히 지정하기 위해 키워드를 사용가능
global_var = "전역 변수"
def outer():
global global_var
global_var = "새로운 전역 변수"
print(global_var) # 전역 변수
outer()
print(global_var) # 새로운 전역 변수
당연히 scope 를 지정하지 않으면 새로운 변수가 선언되면서 초기화 되지 않음
nonlocal 키워드 역시 새로운 변수 선언을 하지 않고 상위 중첩함수의 변수를 가져오기 위한 키워드
closure
중첩함수를 사용해 closure 를 생성할 수 있다.
def make_multiplier(factor):
def multiplier(number):
return number * factor
return multiplier
if __name__ == '__main__':
double = make_multiplier(2)
triple = make_multiplier(3)
quadruple = make_multiplier(4)
print(double(5)) # 10
print(triple(5)) # 15
print(quadruple(5)) # 20
decorator
python 2.2 도입, 다른 함수를 인수로 받아 새롭게 수정된 함수로 대체하는 고차함수
주로 권한검사, 로깅 같이 함수안에서 고정반복되는 코드를 작성해야할 때 자주 사용한다.
def my_decorator(func):
def wrapper():
print("Something is happening before the function is called.")
func()
print("Something is happening after the function is called.")
return wrapper
@my_decorator
def foo():
print("Hello!")
if __name__ == '__main__':
foo()
# Something is happening before the function is called.
# Hello!
# Something is happening after the function is called.
초기 foo() 함수는 그대로 있고 my_decorator() 함수를 겨쳐 foo() 가 재정의된다.
실제 우리가 정의했던 foo() 함수는 재정의된 함수 별도의 공간에 참조변수로서 존재하게 된다.
일반적으로 정의한 함수의 매개변수 타입, 개수 모두 다르기때문에 decorator 함수 정의시 wrapper함수 를 사용하는게 대부분
가변인자와 가변키워드 인자를 통해 wrapper 함수 정의가 가능하다.
def check_is_admin(func):
def wrapper(*args, **kwargs):
if kwargs.get('username') != 'admin':
raise Exception("username is not admin, name:%s" % kwargs.get('username'))
return func(*args, **kwargs)
return wrapper
@check_is_admin
def test_func(msg: str, **kwargs):
print(msg)
if __name__ == '__main__':
test_func('hello world', username="admin", age=30)
# test_func('hello world', username="kouzie", age=30)
# Exception: username is not admin, name:kouzie
변환되는 과정을 코드로 나타내면 아래와 같다.
이미 재정의된 함수를 다시 재정의하기 때문에 이중으로 재정의되어 아래같이 실행된다.
test_func = check_is_admin("admin")(test_func)
update_wrapper
def test_deco(f):
def wrapper(*args, **kwargs):
print("hello")
return f(*args, **kwargs)
return wrapper
@test_deco
def foobar():
"""foo~~bar~~"""
print("boo")
if __name__ == '__main__':
print(foobar.__doc__) # None
print(foobar.__name__) # wrapper
한번 감싸는 순간 함수가 재정의 되기때문에 기존 함수의 메타데이터들(속성, 이름) 들을 잃어버린다.
파이썬 자동 문서화등에서 문제가 발생하수 있기때문에 원복해주는 functools 패키지의 update_wrapper() 함수를 사용하는 것을 권장
import functools
def test_deco(f):
def wrapper(*args, **kwargs):
return f(*args, **kwargs)
wrapper = functools.update_wrapper(wrapper, f)
return wrapper
@test_deco
def foobar():
"""foo~~bar~~"""
print("goo")
if __name__ == '__main__':
print(foobar.__doc__) # foo~~bar~~
print(foobar.__name__) # foobar
update_wrapper 내부 코드를 보면 각종 메타데이터 정보를 별도로 내부변수에 담아두었다가 래퍼 함수 참조변수에 할당하도록 되어있다.
한줄 추가하는것 간단한 일이지만 좀더 좋은 직관성, 짧은 코드를 위해 update_wrapper 기능을 하는 decorator 용 함수가 정의되어 있다.
import functools
def test_deco(f):
@functools.wraps(f)
def wrapper(*args, **kwargs):
return f(*args, **kwargs)
return wrapper
@test_deco
def foobar():
"""foo~~bar~~"""
print("goo")
if __name__ == '__main__':
print(foobar.__doc__) # foo~~bar~~
print(foobar.__name__) # foobar
decorator 매개변수
아래와 같이 3중첩으로 decorator 함수를 정의하면 decorator 자체에 매개변수 전달이 가능하다.
def check_is_admin_mapping(name):
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
if kwargs.get('username') != name:
raise Exception("username is not {0}, name:{1}".format(name, kwargs.get("username")))
else:
return func(*args, **kwargs)
return wrapper
return decorator
@check_is_admin_mapping("kouzie")
def test_func_kouzie(msg: str, **kwargs):
print(msg)
@check_is_admin_mapping("admin")
def test_func_admin(msg: str, **kwargs):
print(msg)
if __name__ == '__main__':
test_func_kouzie("hello", username="kouzie", age=30)
test_func_admin("hello", username="admin", age=30)
다중 decorator
여러번 decorator 적용할 경우 메서드 재정의가 한번 더 이루어지면서 two depth decorator 를 통해 원본 함수를 호출하게된다.
def check_is_admin_mapping(name):
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
if kwargs.get('username') != name:
raise Exception("username is not {0}, name:{1}".format(name, kwargs.get("username")))
else:
return func(*args, **kwargs)
return wrapper
return decorator
def check_is_age_mapping(age):
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
if kwargs.get('age') < age:
raise Exception(f"age is before, age:{kwargs.get('age')}")
else:
return func(*args, **kwargs)
return wrapper
return decorator
# 위에서부터 순서대로 실행
@check_is_admin_mapping("kouzie")
@check_is_age_mapping(20)
def test_func(msg: str, **kwargs):
print(msg)
if __name__ == '__main__':
test_func("hello", username="kouzie", age=30)
클래스와 decorator
클래스에 decorator 를 사용해 클래스를 조작하는 방법.
import uuid
def get_name_id(self):
return str(self.name) + str(self.uuid)
def set_class_name_and_id(klass):
klass.name = str(klass)
klass.uuid = uuid.uuid4()
klass.get_name_id = get_name_id
return klass
@set_class_name_and_id
class SomeClass(object):
pass
if __name__ == '__main__':
sc = SomeClass()
print(SomeClass.name) # <class '__main__.SomeClass'>
print(sc.uuid) # 4dff7a95-a3cd-4930-a7a9-dac385b8c55b
print(sc.get_name_id()) # <class '__main__.SomeClass'>2ad3944d-5bdc-4ac6-938d-a94c3390339a
클래스변수, 메서드를 decorator를 통해 추가가능하다
함수가 클래스로 재정의되어 클래스의 __call__ 함수를 호출하게되는 형태로 변환