k8s - 개요!
k8s 개요
구글에서 시작한 컨테이너 오케스트레이션 오픈소스.
컨테이너 오케스트레이션 툴은 k8s 외에도 Aws ECS, docker swarm, nomad, Apache Mesos 등이 있다.
이중에서 가장 인기있는 컨테이너 오케스트레이션 툴이 k8s 이다.
docker desktop 으로 k8s를 쉽게 사용 가능하다.
별다른 이유가 없다면
docker desktop을 사용하는것을 추천
kubectl
마스터 컴포넌트 중 하나인 API Server 와 통신하기 위해 kubectl 명령을 사용한다.
kubectl 과 API Server가 어떻게 연결되어 있는지 알아보자.
$ ls ~/.kube
cache
config
http-cache
clusters:
- cluster:
certificate-authority: /Users/gojiyong/.minikube/ca.crt
server: https://127.0.0.1:32768
name: minikube
## kubectl 명령 실행시 사용할 클러스터 정보
contexts:
- context:
cluster: minikube
user: minikube
name: minikube
current-context: minikube
kind: Config
preferences: {}
## 클러스터 사용자 정보 context,
users:
- name: minikube
user:
client-certificate: /Users/gojiyong/.minikube/profiles/minikube/client.crt
client-key: /Users/gojiyong/.minikube/profiles/minikube/client.key
## 엑세스 하는 사용자 정보 - 클러스터 엑세스를 위한 인증 키 등 설정
k8s 아키텍처
k8s 컴포넌트: https://kubernetes.io/ko/docs/concepts/overview/components/
k8s는 아래와 같은 여러개의 컴포넌트로 이루어진다.
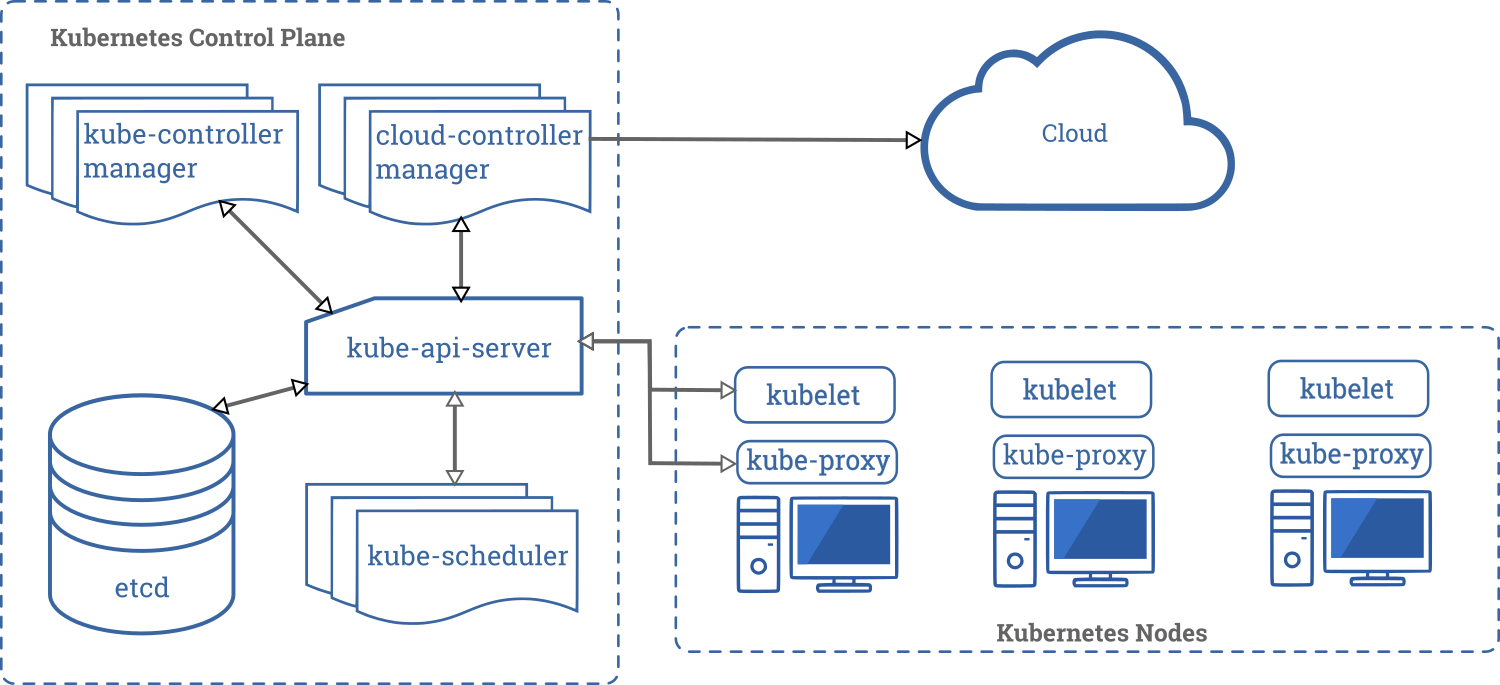
마스터 컴포넌트 모음을 통칭해 컨트롤 플레인(
Control Plane) 이라고 한다.
- k8s control plane(마스터 컴포넌트)
kube-api-serverkube-schedulerkube-controller-manageretcd
- k8s node(노드 컴포넌트)
kubeletkube-proxy
k8s는 아키텍처는 전체적으로 master 와 node 로 구성되며
master 와 node 내부에서 각종 동작을 하는 컴포넌트들이 존재한다.
마스터 컴포넌트
k8s 클러스터 전체를 관리하는 역할
- 클러스터 노드의 리소스 상황 파악
- 컨테이너를 가동시킬 노드를 선택
실제 control plane 을 구성하는 포드들이 kube-system namespace 에서 동작중이며 이를 항상 인지하고 있어야 한다.
$ kubectl get pod -n kube-system -o custom-columns=Pod:metadata.name,Node:spec.nodeName
Pod Node
coredns-6d4b75cb6d-jvhfg docker-desktop
coredns-6d4b75cb6d-qdbbr docker-desktop
etcd-docker-desktop docker-desktop
kube-apiserver-docker-desktop docker-desktop
kube-controller-manager-docker-desktop docker-desktop
kube-proxy-n78j8 docker-desktop
kube-scheduler-docker-desktop docker-desktop
storage-provisioner docker-desktop
vpnkit-controller docker-desktop
API Server
쿠버의 리소스 정보를 관리하기 위한 Rest API 앤드포인트 서버
각 컴포넌트로부터 정보를 받아 etcd 에 저장
컴포넌트간 통신, 노드간 통신을 지원한다.
그림을 보면 모든 컴포넌트들이 API Server 를 통해 통신하는 것을 알 수 있음.
kubectl 명령 또한 API Server 를 통해 전파된다.
etcd
/etc + distribute의 약어.
레드헷에서 설정파일을 서버간 공유하기 위해 만든 툴을 k8s에서 승계함.
클러스터 구성정보를 관리를 위한 분산 Key-value store
노드의 상태정보, k8s에서 필요한 모든 설정 정보가 들어가 있으며 API Server 가 이를 참조해 각 컴포넌트가 동작할 수 있도록 도와줌,
중요한 데이터이기에 백업, 별도의 서버들에 분산실행 한다.
Raft 합의 알고리즘을 통해 모든 노드에게 일관성 있는 설정을 공유한다.
스케줄러
파드를 어느 노드에서 작동시킬지를 제어하는 백앤드 컴포넌트, API Server 와 통신하며 클러스터 상태를 확인, 빈공간의 노드에 파드를 할당 및 실행하는 스케줄링을 처리한다.
컨트롤러 매니저
파드를 관리하는 컨트롤러들이 곳곳에 배치되어 있고 이 컨트롤러 각각을 실행하는 컴포넌트가 컨트롤러 매니저. 클러스터의 상태를 감시, 항상 정상상태를 유지시키는 백앤드 컴포넌트
노드 컴포넌트
https://kubernetes.io/ko/docs/tutorials/kubernetes-basics/explore/explore-intro/
컨테이너가 작동되는 서버, 여러대의 노드를 준비해 클러스터를 구성,
노드는 클라우드 서비스 회사의 가상 머신 혹은 물리 머신이 노드역할을 한다.
해당 노드안에서 여러대의 컨테이너가 동작
kubelet
노드 내부에선 kubelet 이라는 에이전트가 움직이며 컨테이너(파드)를 실행, 헬스체크 한다.
노드의 status 를 정기적으로 감시하며 이를 API Server 로 전송, etcd 에 저장되도록 지원.
kube-proxy
클러스터 안의 별도의 가상 네트워크 설정,
노드로 들어오는 패킷을 적절한 Pod 로 라우팅, 로드밸런싱 등의 동작을 관리하는 컴포넌트
Event chain
k8s 는 Reconciliation Loops 를 통해 항상 context 상태를 검사한다.
Reconciliation: 조정을 뜻한다. 조정은 두 레코드 세트가 일치하는지 확인하는 프로세스.
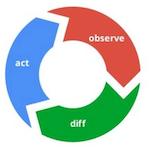
Observe: 현 상태와의 차이를 비교하기 위해 API Server 에 상태조회
Diff: 현 context 와 API Server 에서 받아온 context 를 비교
Act: 두 context 간 차이가 있다면 업데이트
위의 일련의 과정은 Event chain 이라는 이라는 관계로 형성된다.
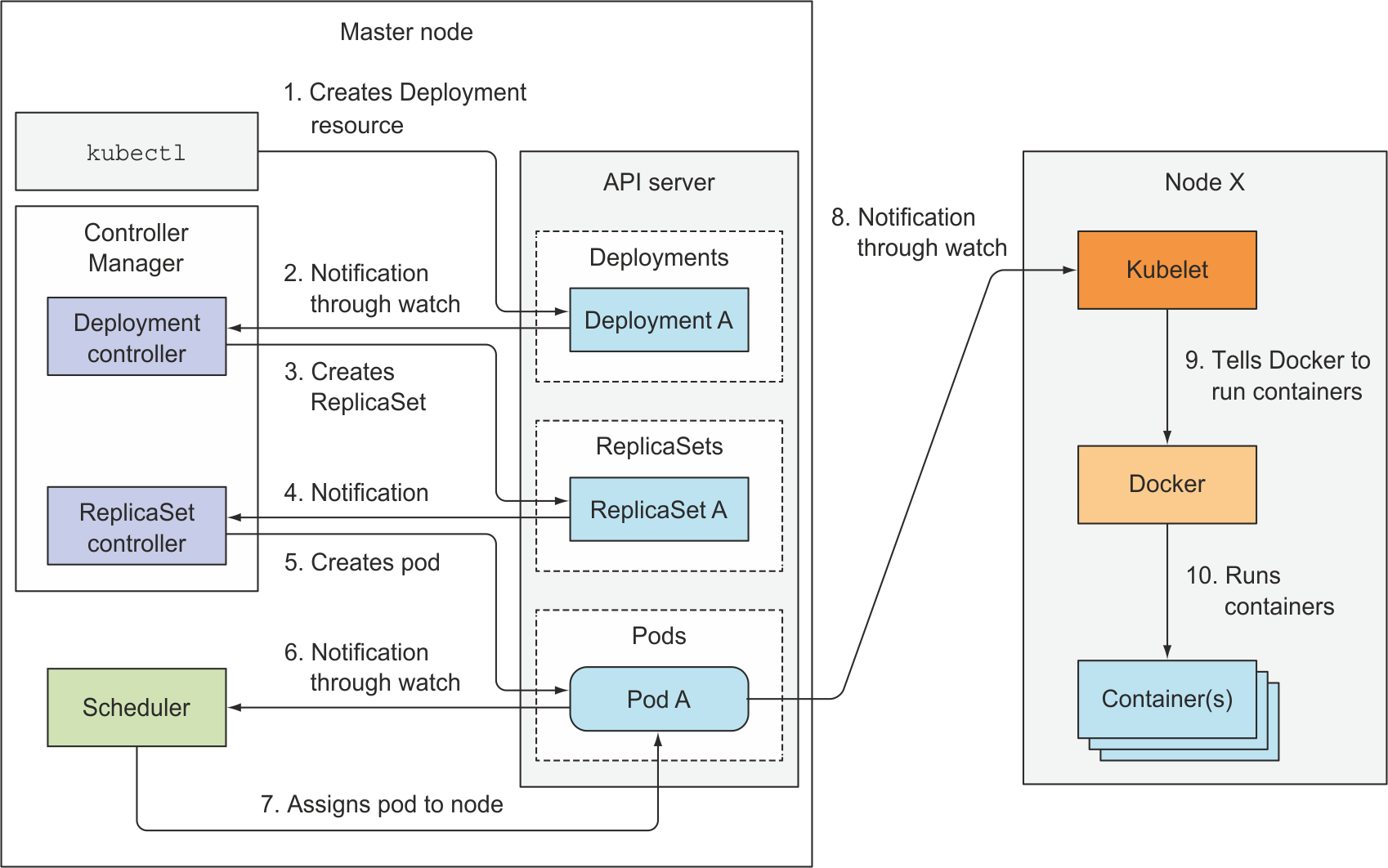
kubectl로 디플로이먼트 매니페스트를apply,kubectl이디플로이먼트 API호출,디플로이먼트 API가etcd에 매니페스트 정보를 저장디플로이먼트 API를watch(감시)하고 있는디플로이먼트 컨트롤러가 변화를 감지디플로이먼트 컨트롤러가리플리카셋 API를 호출,리플리카셋 API가etcd에 매니페스트 정보를 저장리플리카셋 API를watch(감시)하고 있는리플리카셋 컨트롤러가 변화를 감지리플리카셋 컨트롤러가파드 API를 호출,파드 API가etcd에 매니페스트 정보를 저장파드 API를watch(감시)하고 있는스케줄러가 변화를 감지스케줄러가 어떤 노드에 파드를 배치할지 결정,스케줄러가파드 API를 호출해etcd업데이트(어떤 노드에 배치할지)파드 API를watch(감시)하고 있는 노드의kubelet이 변화를 감지kubelet이컨테이너 런타임에 포드 작성 지시컨테이너생성
Event chain 은 이 과정을 지속적으로 루프한다.
실제 디플로이먼트를 apply 하고 일련의 Event chain 과정을 확인하고 싶다면 아래 명령 사용
$ kubectl get events -w
## nginx-deployment.yaml
## 기본항목
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
## 디플로이먼트 스팩
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod ## 템플릿 검색조건
## 파드 템플릿
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.15 ## 컨테이너 이미지
ports:
- containerPort: 80
위의 디플로이먼트 매니페스트를 apply 하고 이벤트 체인에서 출력되는 메세지를확인
$ kubectl get events -w
LAST SEEN TYPE REASON OBJECT MESSAGE
0s Normal ScalingReplicaSet deployment/nginx-deployment Scaled up replica set nginx-deployment-f75fb748c to 3
0s Normal SuccessfulCreate replicaset/nginx-deployment-f75fb748c Created pod: nginx-deployment-f75fb748c-hq556
0s Normal SuccessfulCreate replicaset/nginx-deployment-f75fb748c Created pod: nginx-deployment-f75fb748c-j2sh9
1s Normal SuccessfulCreate replicaset/nginx-deployment-f75fb748c Created pod: nginx-deployment-f75fb748c-wbpzp
<unknown> Normal Scheduled pod/nginx-deployment-f75fb748c-j2sh9 Successfully assigned default/nginx-deployment-f75fb748c-j2sh9 to minikube
<unknown> Normal Scheduled pod/nginx-deployment-f75fb748c-hq556 Successfully assigned default/nginx-deployment-f75fb748c-hq556 to minikube
<unknown> Normal Scheduled pod/nginx-deployment-f75fb748c-wbpzp Successfully assigned default/nginx-deployment-f75fb748c-wbpzp to minikube
0s Normal Pulling pod/nginx-deployment-f75fb748c-hq556 Pulling image "nginx:1.15"
0s Normal Pulling pod/nginx-deployment-f75fb748c-j2sh9 Pulling image "nginx:1.15"
0s Normal Pulling pod/nginx-deployment-f75fb748c-wbpzp Pulling image "nginx:1.15"
0s Normal Pulled pod/nginx-deployment-f75fb748c-hq556 Successfully pulled image "nginx:1.15"
0s Normal Created pod/nginx-deployment-f75fb748c-hq556 Created container nginx
0s Normal Started pod/nginx-deployment-f75fb748c-hq556 Started container nginx
0s Normal Pulled pod/nginx-deployment-f75fb748c-j2sh9 Successfully pulled image "nginx:1.15"
0s Normal Created pod/nginx-deployment-f75fb748c-j2sh9 Created container nginx
0s Normal Started pod/nginx-deployment-f75fb748c-j2sh9 Started container nginx
0s Normal Pulled pod/nginx-deployment-f75fb748c-wbpzp Successfully pulled image "nginx:1.15"
0s Normal Created pod/nginx-deployment-f75fb748c-wbpzp Created container nginx
0s Normal Started pod/nginx-deployment-f75fb748c-wbpzp Started container nginx
API Server 에선 Manifest file로 etcd 에 업데이트만 할뿐 이를 k8s 컨트롤러가 각각 감시하며 별도로 움직인다.
마스터 가용성
운영중인 서비스의 가용성을 늘리려면 노드를 확보하고 파드를 늘리면 된다.
k8s 자체의 가용성을 늘리려면 아래 그림처럼 마스터 노드(컨트롤 플레인) 을 다중화 하여 가용성을 확보해야한다.
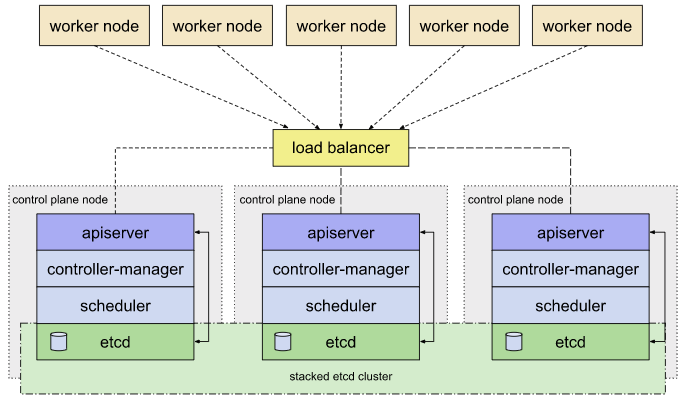
etcd 는 클러스터로 구축하여 서로같의 데이터를 항시 동기화 하고
API Server 서버는 로드밸런서를 사용해 엑세스를 분산시킨다.
컨트롤러 매니저와 스케줄러는 액티브/스탠바이형을 가지며 액티브한 마스터 컴포넌트의 장애에 대비한다. 서로간의 경합을 피하기 위해 동시간대에 하나씩의 컴포넌트만 동작한다.
액티브한 컴포넌트는 기본값인 2초마다 갱신시간을 기록하며
kube-system 네임 스페이스의 endpoints인 kube-controller-manager 에서 확인 가능하다.
renewTime 속성 확인
$ kubectl get endpoints kube-controller-manager -n kube-system -o yaml
apiVersion: v1
kind: Endpoints
metadata:
annotations:
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"minikube_2a1b1ca1-403a-45e1-b4b8-c50afb0e14a1","leaseDurationSeconds":15,"acquireTime":"2020-04-29T16:36:09Z","renewTime":"2020-05-05T11:32:38Z","leaderTransitions":3}'
creationTimestamp: "2020-04-28T08:17:42Z"
managedFields:
- apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
f:metadata:
f:annotations:
.: {}
f:control-plane.alpha.kubernetes.io/leader: {}
manager: kube-controller-manager
operation: Update
time: "2020-05-05T11:32:38Z"
name: kube-controller-manager
namespace: kube-system
resourceVersion: "174543"
selfLink: /api/v1/namespaces/kube-system/endpoints/kube-controller-manager
uid: c38faf14-ceb3-4e54-91fd-fa730b1d58a9
컨트롤 플레인의 노드(마스터 노드)의 개수는 홀수로 하는것이 좋다. etcd 클러스터에서 노드간의 투표를 통해 데이터 동기화를 진행하기에 항상 항상 과반수가 나오는 홀수를 권장하며 3 ~ 7개 까지의 노드수가 효율적이다.
노드 가용성
일반 노드에선 컨트롤 플레인에서 고려할 각종 문제점이 없기에
가용성, 다중화가 필요하다면 노드(서버)를 추가확보하기만 하면 된다.
단 노드 다운시 해당 노드에 존재하던 파드들이 다른 노드에 배치되기에 리소스를 확인하며 노드확보할 필요가 있다.
노드 2개 운영시 하나의 노드가 다운될 경우 다른 하나의 노드에 부하가 집중됨으로 노드는 3개 이상으로 구성하는것이 전형적인 구조이다.
가장큰 리소스인 노드부터 가장작은 파드, 각종 컴포넌트들의 다중화를 진행하였어도
폭발반경(Blast Radius) 을 계산하지 않는다면 물리적 장애 발생시 대처가 불가능하다.
폭발반경의 범위는 아래와 같다.
- 물리서버
- 랙
- 데이터 센터
- 지역
만약 하나의 물리서버에 가상머신을 사용해 모든 서버를 올리게 되면 해당 물리서버 다운시 모든 서비스가 중단된다.
만약 하나의 랙에 모든 서비스 운영 물리서버를 설치한다면 해당 랙의 전력이나 네트워크 다운시 모든 서비스가 중단된다.
데이터 센터나 지역도 마찬가지이다. 재난 발생시에 전력, 네트워크가 차단될 경우 모든 서비스가 중단된다.
폭발반경을 의식하며 동일한 종류의 서버(노드, 컨트롤 플레인), 가상머신을 분리 배치해야한다.
데이터센터 폭발반경을 의식해 k8s 리소스를 분산배치할 경우 동기화 스르풋, 타임아웃이 될 위험이 발생한다.
컨트롤 플레인의 경우 특히 더 민감한데 하트비트 100밀리초, 리더선출 1000밀리초를 기본값으로 사용한다.
애저의 경우 한국 중부, 남부지역의 지연시간은 10밀리초 정도라한다.
전용 네트워크 백본을 통해 연결되기에 이보다 더 빨라질순 없다.
만약 목표를 10밀리초 이하로 잡아야 한다면 별도에 지역에 클러스터 하나를 구축하는것이 아닌 하나의 지역마다 클러스터 하나를 구축해야 한다.
k8s 업데이트, 업그레이드
k8s 클러스터 운영시 2가지의 버전업이 필요하다.
- k8s 컴포넌드 버전업
- k8s 서버 버전업
k8s는 마이너는 3개월 간격으로 버전이 릴리즈 되고 있으며 단순 버그 패치는 한달에 한두번 릴리즈 되고 있다.
Cordon, Uncordon, Drain
업데이트시에 노드의 재부팅이 빈번히 일어남으로 k8s 스케줄링에서 제외해야 한다.
이때 Cordon, Uncordon 명령을 사용한다.
Cordon: 폐쇄하다
다음과 같은 간단한 Deployment를 apply
## nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
$ kubectl apply -f nginx.yaml
$ kubectl get pod --output=wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-f89759699-5pqrm 1/1 Running 0 96s 172.18.0.2 minikube-m03 <none> <none>
nginx-f89759699-7pmmz 1/1 Running 0 96s 172.18.0.2 minikube-m02 <none> <none>
nginx-f89759699-wxjtx 1/1 Running 0 96s 172.18.0.3 minikube-m03 <none> <none>
$ kubectl cordon minikube-m02
node/minikube-m02 cordoned
$ kubectl get node
NAME STATUS ROLES AGE VERSION
minikube Ready master 143m v1.18.0
minikube-m02 Ready,SchedulingDisabled <none> 141m v1.18.0
minikube-m03 Ready <none> 11m v1.18.0
minikube-m02 노드를 cordon 명령을 통해 스케줄링에서 제외한다.
STATUS 에 SchedulingDisabled 상태가 추가된 것을 확인
이 상태에서 replicas 를 6으로 변경한다.
$ kubectl get pod --output=wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-f89759699-5pqrm 1/1 Running 0 3h25m 172.18.0.2 minikube-m03 <none> <none>
nginx-f89759699-7pmmz 1/1 Running 0 3h25m 172.18.0.2 minikube-m02 <none> <none>
nginx-f89759699-fnfst 1/1 Running 0 23s 172.18.0.5 minikube-m03 <none> <none>
nginx-f89759699-mcpj2 1/1 Running 0 23s 172.18.0.6 minikube-m03 <none> <none>
nginx-f89759699-tmhz2 1/1 Running 0 23s 172.18.0.4 minikube-m03 <none> <none>
nginx-f89759699-wxjtx 1/1 Running 0 3h25m 172.18.0.3 minikube-m03 <none> <none>
minikube-m02에는 추가되지 않고 minikube-m03에만 파드가 추가생성되었다.
minikube-m02를 Uncordon 명령으로 스케줄링 대상으로 복원
$ kubectl uncordon minikube-m02
node/minikube-m02 uncordoned
$ kubectl get node
NAME STATUS ROLES AGE VERSION
minikube Ready master 5h48m v1.18.0
minikube-m02 Ready <none> 5h46m v1.18.0
minikube-m03 Ready <none> 3h36m v1.18.0
Drain은 Cordon 움직임에 포드의 삭제, 재작성을 더한것이다.
$ kubectl drain minikube-m03
node/minikube-m03 cordoned
error: unable to drain node "minikube-m03", aborting command...
There are pending nodes to be drained:
minikube-m03
error: cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): kube-system/kindnet-v7qmx, kube-system/kube-proxy-b6r9k
노드 전용으로 움직이는 데몬셋은 다른 노드로 옮기수 없기에 오류가 발생한다.
$ kubectl drain minikube-m03 --ignore-daemonsets
node/minikube-m03 already cordoned
WARNING: ignoring DaemonSet-managed Pods: kube-system/kindnet-v7qmx, kube-system/kube-proxy-b6r9k
evicting pod default/nginx-f89759699-fnfst
evicting pod default/nginx-f89759699-5pqrm
evicting pod default/nginx-f89759699-mcpj2
evicting pod default/nginx-f89759699-tmhz2
evicting pod default/nginx-f89759699-wxjtx
pod/nginx-f89759699-mcpj2 evicted
pod/nginx-f89759699-wxjtx evicted
pod/nginx-f89759699-fnfst evicted
pod/nginx-f89759699-tmhz2 evicted
pod/nginx-f89759699-5pqrm evicted
node/minikube-m03 evicted
$ kubectl get node
NAME STATUS ROLES AGE VERSION
minikube Ready master 5h54m v1.18.0
minikube-m02 Ready <none> 5h52m v1.18.0
minikube-m03 Ready,SchedulingDisabled <none> 3h42m v1.18.0
$ kubectl get pod --output=wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-f89759699-5nh2s 1/1 Running 0 91s 172.18.0.5 minikube-m02 <none> <none>
nginx-f89759699-7pmmz 1/1 Running 0 3h33m 172.18.0.2 minikube-m02 <none> <none>
nginx-f89759699-9x2gq 1/1 Running 0 91s 172.18.0.6 minikube-m02 <none> <none>
nginx-f89759699-jxdbq 1/1 Running 0 91s 172.18.0.3 minikube-m02 <none> <none>
nginx-f89759699-kdtqs 1/1 Running 0 91s 172.18.0.4 minikube-m02 <none> <none>
nginx-f89759699-pp4kh 1/1 Running 0 91s 172.18.0.7 minikube-m02 <none> <none>
evicted: 퇴거
drain 설정한 노드의 파드는 모두 다른 노드에 재작성 되고 스케줄링에서 제외된다.
k8s 리소스
- 애플리케이션 실행 -
Pod,ReplicaSet,Deployment,DaemonSet - 네트워크 관리 -
Service,Ingress - 애플리케이션 설정 정보 관리 -
ConfigMap,Secrets - 배치잡 관리 -
Job,CronJob
외에도 여러가지 k8s 리소스가 있지만 자주 사용하는 리소스 몇가지만 먼저 알아보자.
파드(Pod): k8s에서 생성/관리할 하는 가장 작은 컴퓨팅 단위
https://kubernetes.io/ko/docs/concepts/workloads/pods/
k8s 에선 여러개의 컨테이너를 모아 파드로 관리한다.
파드는 항상 하나의 노드에 배치되며 파드 내부에서 도커 컨테이너 여러개를 모아 관리할 수 있다.
리플리카 셋(Replica Set): 클러스터 안에서 가동되는 파드 수를 관리하는 리소스
https://kubernetes.io/ko/docs/concepts/workloads/controllers/replicaset/
클러스터 안에 지정된 수의 파드를 일정하게 유지하며 장애대응 및 자동 실행하는 역할.
디플로이먼트(Deployment): 애플리케이션 배포 버전 단위를 관리하는 리소스
https://kubernetes.io/ko/docs/concepts/workloads/controllers/deployment/
파드안의 컨테이너를 버전업 하고 싶을 때 시스템을 정지시키지 않고 버전업(롤링업데이트), 롤백 기능 등을 제공한다.
데몬 셋(Daemon Set): 특정노드 혹은 모든 노드에 항상 실행되어야할 특정 컨테이너(파드)를 관리하는 리소스
https://kubernetes.io/ko/docs/concepts/workloads/controllers/daemonset/
마스터 노드의 스케줄러에 영향을 받지 않고 지정한 노드에서 컨테이너를 동작시키고 싶을때 사용한다.
예를들어 로그콜렉터, 모니터링 기능을 하는 컨테이너(파드)는 노드당 하나씩 작동시키고 싶은 경우가 있는데 이때 데몬셋을 사용한다.
kube-proxy또한 데몬 셋을 사용해 가동된다.
스테이트풀 셋(Stateful Set)
고정된 상태(Stateful) 을 요구하는 컨테이너(파드)를 관리하는 리소스
https://kubernetes.io/ko/docs/concepts/workloads/controllers/statefulset/
DB와 같은 고정된 상태(Stateful)를 필요로 하는 컨테이너의 경우 스테이트풀 셋 를 사용한다.
안정성, 고정성, 지속성 을 보증한다.
Manifest file(템플릿)
Manifest: 선언서
클러스터 내부에서 움직이는 컨테이너, 네트워크, 잡 등의 k8s 리소스를 Manifest file 을 통해 관리한다.
yaml, json 형식의 파일로 구성된다.
k8s 의 모든 리소스는 Manifest file 을 통해 이루어지기 때문에
리소스별 문법을 익혀야 한다.
kubectl explain명령어를 통해 리소스별 사용 가능한 내부 속성을 볼 수 있다.
리소스별로 사용법이 다름으로 간단한 구성과 실행, 삭제 방법만 알아본다.
## webserver.yaml
apiVersion: apps/v1 ## api 버전 정보 - 호출할 api 버전 지정, kubectl api-versions 로 사용할 수 있는 버전 확인 가능.
kind: ReplicaSet ## 쿠버 리소스 종류 - Pod, ReplicaSet, Service, ConfigMap, Job 등등
metadata: ## 해당 오브젝트 이름, 레이블 지정
name: webserver ## 리소스 이름 - kubectl 명령으로 조작할 때 사용하는 이름
spec: ## 리소스의 상세 정보, 실행 동작 방식 등을 지정, 아래는 kind = ReplicaSet 에서 사용 가능한 속성들
replicas: 10
selector:
matchLabels:
app: webfront
template:
metadata:
labels:
app: webfront
spec:
containers:
- image: nginx
name: webfront-container
ports:
- containerPort: 80
위와 같이 Manifest file 을 사용해 k8s 리소스 생성, 삭제가능
$ kubectl apply -f webserver.yaml
replicaset.apps/webserver created
$ kubectl delete -f webserver.yaml
replicaset.apps "webserver" deleted
Manifest file 의 정보는 etcd 에 저장되고 관리한다.
kuberctl 명령으로 Manifest file 업데이트가 가능하며 업데이트 버전 정보가 추가 기록된다.
https://kubernetes.io/ko/docs/concepts/overview/working-with-objects/labels/
쿠버에선 수월한 리소스 관리 를 위해 labels 속성을 많이 사용한다.
## Label/label-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod-a
labels:
env: test
app: photo-view
spec:
containers:
- image: nginx
name: photoview-container
--- ## --- 를 사용해 하나의 파일에 2개의 리소스 정보 입력 가능
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod-b
labels:
env: test
app: imagetrain
spec:
containers:
- image: nginx
name: photoview-container
$ kubectl apply -f Label/label-pod.yaml
pod/nginx-pod-a created
pod/nginx-pod-b created
$ kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod-a 1/1 Running 0 24s app=photo-view,env=test
nginx-pod-b 1/1 Running 0 24s app=imagetrain,env=test
Manifest file 내부 리소스 label 을 수정해서 다시 apply,
imagetrain -> predictoin 으로 수정
$ kubectl apply -f Label/label-pod.yaml
pod/nginx-pod-a unchanged
pod/nginx-pod-b configured
$ kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod-a 1/1 Running 0 6m3s app=photo-view,env=test
nginx-pod-b 1/1 Running 0 6m3s app=predictoin,env=test
라벨 선택 속성 -l 사용하여 라벨을 통해 생성 리소스 검색 가능
$ kubectl get pod -l app=photo-view,env=test
NAME READY STATUS RESTARTS AGE
nginx-pod-a 1/1 Running 0 7m13s
| 연산자 | 설명 |
|---|---|
key=value |
key 값이 value 일 경우 |
key!=value |
key 값이 value 아닐 경우 |
'key in (...value)' |
key 값이 value 에 포함 될경우 |
'key notin (...value)' |
key 값이 value 에 포함되지 않을 경우 |
key |
key 값이 존재할 경우 |
!key |
key 값이 존재하지 않을 경우 |
in,notin연산은 홀따옴표로 묶어주어야 한다.
콤마로AND연산은 사용 가능하지만OR연산은 사용 불가능하다.
apiGroups
yaml 에서 apiGroups 와 같은 속성을 사용하는데 k8s API Server 에서 사용하는 api 모음을 뜻한다.
일반적으로 사용하는 apiVersion: v1 은 core api 를 뜻한다.
아래와 같은 종류의 apiGroups 가 존재한다.
- core
- extensions
- apps
- rbac.authorization.k8s.io