java 8 - 병렬, Optional!
병렬
컬렉션 클래스에서 parallel() 메서드를 쉽게 병렬로 데이터 처리가 가능하다.
하지만 병렬이라고 무조건 싱글 스레드 처리보다 빠른것이 아니며
병렬로 실행할 경우 분리(포크)/합병(조인) 하는 과정이 생기기에 추가적인 연산과정이 필요하기 때문에
적은 데이터 연산 과정의 경우 오히려 연산시간이 더 늘어날 수 있다.
측정이 아닌 스트림 성능 측정을 통해 선택방식을 결정해야 한다.
sequential(), parallel()
사실 우리가 일반적으로 사용하는 스트림은 sequential(순차적) 방식이며 내부적으로 boolean flag 가 스위치 역할을 하며 parallel 로 실행할지 sequential로 실행할지 결정된다.
만약 stream().sequential().parallel()...; 처럼 2개 모두 사용하면 마지막에 호출된 parallel() 메서드가 boolean flag 를 변환한다.
성능 측정
jmh(Java Microbenchmark Harness) 라이브러리를 사용하면 가비지 컬렉터, 바이트코드 최적화 등의 잡다한 시간을 무시하고 쉽게 벤치마크를 할 수 있다.
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.21</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.21</version>
</dependency>
@State(Scope.Thread)
@BenchmarkMode(Mode.AverageTime) // 밴체마크 대상 실행 평균 시간 측정
@OutputTimeUnit(TimeUnit.MILLISECONDS) // 밴치마크 시간 단위
@Fork(value = 2, jvmArgs = { "-Xms4G", "-Xmx4G" }) // 4G 힙공간에서 2회 실행
@Measurement(iterations = 2)
@Warmup(iterations = 3)
public class ParallelStreamBenchmark {
private static final long N = 10_000_000L;
@Benchmark // 밴치마크 대상 메서드
public long iterativeSum() {
long result = 0;
for (long i = 1L; i <= N; i++) {
result += i;
}
return result;
}
/*Result "modernjavainaction.chap07.ParallelStreamBenchmark.iterativeSum":
3.910 ±(99.9%) 0.376 ms/op [Average]
(min, avg, max) = (3.838, 3.910, 3.957), stdev = 0.058
CI (99.9%): [3.533, 4.286] (assumes normal distribution)*/
@Benchmark
public long parallelSum() {
return Stream.iterate(1L, i -> i + 1).limit(N).parallel().reduce(0L, Long::sum);
}
/*Result "modernjavainaction.chap07.ParallelStreamBenchmark.parallelSum":
103.221 ±(99.9%) 28.860 ms/op [Average]
(min, avg, max) = (99.191, 103.221, 107.178), stdev = 4.466
CI (99.9%): [74.361, 132.081] (assumes normal distribution)*/
전통적인 for문 방식은 3초대가 나온반면 병렬로 실행하는 방식은 100초 가까이 걸렸다.
사실 위의 parallelSum() 은 병렬방식으로 실행되지않고 순차적인 방식으로 진행된다.
iterate를 사용하면 reduce 메서드 실행전까지 스트림이 생성되지 않기 때문에 일반적인 순차 스트림 방식으로 reduce sum 함수를 진행하고
여기서 발생하는 기본형으로 언박싱, 스레드가 생성으로 인한 오버헤드가 발생한다.
@Benchmark
public long rangedSum() {
return LongStream.rangeClosed(1, N).reduce(0L, Long::sum);
}
@Benchmark
public long parallelRangedSum() {
return LongStream.rangeClosed(1, N).parallel().reduce(0L, Long::sum);
}
/*
# Run progress: 20.00% complete, ETA 00:06:43
# Fork: 1 of 2
# Warmup Iteration 1: 1.177 ms/op
# Warmup Iteration 2: 1.077 ms/op
# Warmup Iteration 3: 1.102 ms/op
Iteration 1: 1.079 ms/op
Iteration 2: 1.084 ms/op
# Run progress: 30.00% complete, ETA 00:05:53
# Fork: 2 of 2
# Warmup Iteration 1: 6.546 ms/op
# Warmup Iteration 2: 8.517 ms/op
# Warmup Iteration 3: 7.539 ms/op
Iteration 1: 7.777 ms/op
Iteration 2: 7.675 ms/op
Result "modernjavainaction.chap07.ParallelStreamBenchmark.parallelRangedSum":
4.404 ±(99.9%) 24.792 ms/op [Average]
(min, avg, max) = (1.079, 4.404, 7.777), stdev = 3.837
CI (99.9%): [≈ 0, 29.195] (assumes normal distribution)
*/
@TearDown(Level.Invocation) // 각 밴치마크 실행 후 가비지 컬렉터 동작
public void tearDown() {
System.gc();
}
}
일반적인 순차스트림에서 사용하는 공유 데이터를 사용하는 것에서도 병렬 처리방식으로 변경될 경우 정확한 데이터처리가 이루어지지 않을 수 있다.
포크/조인 프레임워크
java8 이전에 어떤식으로 병렬 프로그래밍을 진행했는지 알아보자.
java7에 추가된 포크/조인 프레임워크 방식을 사용한다.

각각의 작업들을 잘게 쪼개 서브테스크로 만들고 모든 서브테스크를 수행
처리결과를 조합하는 과정이 실제 병렬처리에 들어가있다.
작업을 나누고 스레드에 할당하는 과정에서 java.util.concurrent.RecursiveTask 객체를 통해 재귀적으로 스레드 풀을 사용하게 된다.
public class ForkJoinSumCalculator extends RecursiveTask<Long> {
public static final long THRESHOLD = 10_000;
private final long[] numbers;
private final int start;
private final int end;
public ForkJoinSumCalculator(long[] numbers) {
this(numbers, 0, numbers.length);
}
private ForkJoinSumCalculator(long[] numbers, int start, int end) {
this.numbers = numbers;
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
int length = end - start;
if (length <= THRESHOLD) // 처리개수가 THRESHOLD 보다 작아진다면 연산 후 반환
return computeSequentially();
ForkJoinSumCalculator leftTask = new ForkJoinSumCalculator(numbers, start, start + length / 2); // 분할1
leftTask.fork(); // 태스크 비동기 실행
ForkJoinSumCalculator rightTask = new ForkJoinSumCalculator(numbers, start + length / 2, end); // 분할2
Long rightResult = rightTask.compute(); // 태스크 분할
Long leftResult = leftTask.join(); // 결과가 도출될때 까지 대기
return leftResult + rightResult;
}
private long computeSequentially() {
long sum = 0;
for (int i = start; i < end; i++) {
sum += numbers[i];
}
return sum;
}
public static long forkJoinSum(long n) {
long[] numbers = LongStream.rangeClosed(1, n).toArray();
ForkJoinTask<Long> task = new ForkJoinSumCalculator(numbers);
return new ForkJoinPool().invoke(task); // compute 결과 반환.
}
}
forkJoinSum() 메서드를 보면 java.util.concurrent.ForkJoinTask 태스크를 생성해 ForkJoinPool 에 집어넣어 병렬실행한다.
ForkJoinPool 인스턴스는 은 일반적으로 한개이상 생성하지 않으며 런타임의 availableProcessors 에서 반환한 개수만큼의 스레드 풀을 생성해 두며 태스크가 자유롭게 해당 풀에 접근할 수 있도록 한다.
invoke() 메서드를 통해 ForkJoinSumCalculator 의 compute 메서드가 호출되게 된다.
compute 내부를 살펴보면 leftTaks 의 경우 ForkJoinTask 의 fork(), join() 메서드를 호출해 결과를 계산했다.
fork() 를 통해 compute() 메서드를 스레드 풀에서 실행시키고 join() 메서드를 호출해 예하의 모든 메서드가 종료될때까지(최종 결과값 반환) 기다린다.
https://www.baeldung.com/java-fork-join
@Override
protected Long compute() {
int length = end - start;
if (length <= THRESHOLD) {
return computeSequentially();
}
ForkJoinSumCalculator leftTask = new ForkJoinSumCalculator(numbers, start, start + length / 2);
leftTask.fork();
ForkJoinSumCalculator rightTask = new ForkJoinSumCalculator(numbers, start + length / 2, end);
rightTask.fork();
Long rightResult = rightTask.join();
Long leftResult = leftTask.join();
return leftResult + rightResult;
}
compute 대신 fork 를 사용해도 작업내용은 동일하다. task 큐에 밀어넣고 compute 메서드가 실행되길 기다린다.
작업훔치기
fork() 를 통해 분할된 스레드가 동일한 크기의 태스크를 맡는다는 것을 확신할 수 없고, 비슷한 크기의 태스크를 맡는다 해도 비슷한 시간에 같이 끝난다는 것도 확신할 수 없다.
최대한 많은 코어가 일을 할 수 있도록 ForkJoinPool 에선 작업훔치기 기법을 사용한다.
스레드마다 처리해야할 태스크가 저장되는 작업 큐가 있으며
자신의 큐의 태스크가 비워지면 다른 스레트의 큐의 꼬리에서 작업을 훔쳐와 처리한다.
모든 스레드의 작업 큐가 비워질때까지 재귀적으로 반복한다.
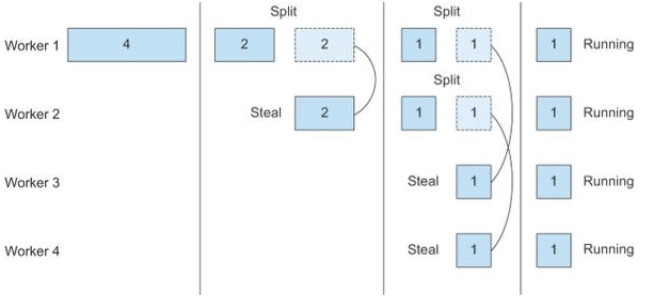
그림을 보면 분할(split)과 동시에 각 스레드에서 작업훔치기(steal)를 통해 순식간에 4개의 스레드가 동작한다.
Spliterator 인터페이스
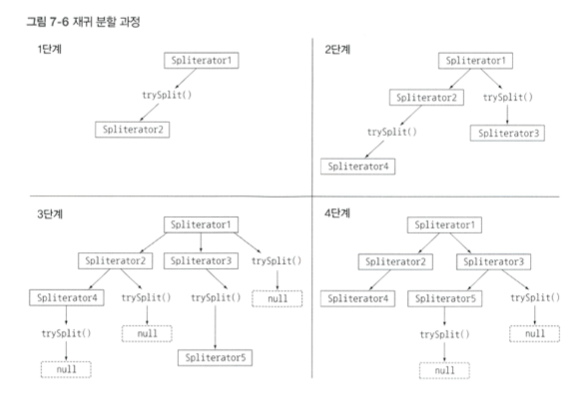
Spliterator: 분할할 수 있는 반복자,spli + iterator
java8 부터 모든 컬렉션 클래스에 구현되어 있다.
간단한 단어의 개수를 세는 코드이다.
public static int countWordsIteratively(String s) {
int counter = 0;
boolean lastSpace = true;
for (char c : s.toCharArray()) {
if (Character.isWhitespace(c))
lastSpace = true;
else {
if (lastSpace) counter++;
lastSpace = false;
}
}
return counter;
}
public static void main(String[] args) {
String sentence = " Nel mezzo del cammin di nostra vita " +
"mi ritrovai in una selva oscura" +
" che la dritta via era smarrita ";
System.out.println("Found " + countWordsIteratively(sentence) + " words");
// Found 19 words
}
공백을 만나면 lastSpace 를 true 로 변경하고 공백이 아닌 문자를 만날때 마다 lastSpace가 true 라면 단어 시작으로 보고 카운트를 1 증가하는 코드이다.
이번엔 parallel, stream 의 reduce 를 사옹해 count 를 구해보자.
private static class WordCounter {
private final int counter;
private final boolean lastSpace;
public WordCounter(int counter, boolean lastSpace) {
this.counter = counter;
this.lastSpace = lastSpace;
}
public WordCounter accumulate(Character c) {
if (Character.isWhitespace(c))
return lastSpace ? this : new WordCounter(counter, true);
else
return lastSpace ? new WordCounter(counter + 1, false) : this;
}
public WordCounter combine(WordCounter wordCounter) {
return new WordCounter(counter + wordCounter.counter, wordCounter.lastSpace);
}
public int getCounter() {
return counter;
}
}
public static int countWordsByStream(String sentence) {
WordCounter wordCounter = IntStream.range(0, sentence.length())
.mapToObj(i -> sentence.charAt(i))
.parallel()
.reduce(new WordCounter(0, true),
(wordCounter1, character) -> wordCounter1.accumulate(character),
(wordCounter1, wordCounter2) -> wordCounter1.combine(wordCounter2));
return wordCounter.getCounter();
}
public static void main(String[] args) {
System.out.println("Found " + countWordsByStream(sentence) + " words");
// Found 43 words
}
WordCounter 를 통해 charactor 를 감싸고 병렬처리를 위한 메서드 accumulate, combine 를 정의한다.
병렬로 실행하게 되먼 생각하지 못했던 문제가 발생한다.
public static int countWords(String sentence) {
WordCounter wordCounter = IntStream.range(0, sentence.length())
.mapToObj(i -> sentence.charAt(i))
.parallel()
.reduce(new WordCounter(0, true),
(word, character) -> {
System.out.println("character:" + character);
return word.accumulate(character);
},
(word1, word2) -> word1.combine(word2));
return wordCounter.getCounter();
/*
character:a
character:i
character:
character:
character:
character:c
*/
}
이유는 간단히 parallel 로 시작되다 보니 어디서 누가 먼저 시작되는지 모르기 떄문이다.
단어 중간, 공백 한가운데에서 시작될 수 있고 단어 중간에서 시작될 경우 한 단어를 2개 로 카운트해버린다.
스레드가 여러개일 수록 단어를 여러 스레드가 쪼개서 가져가게 될것이고 모두 첫 카운트를 증가시킬 것이다.
단어가 끝나는 위치에서 스레드를 분할시켜야 한다.
spliterator 를 통해 구현해보자.
private static class WordCounterSpliterator implements Spliterator<Character> {
private final String string;
private int currentIndex = 0;
private WordCounterSpliterator(String string) {
this.string = string;
}
@Override
public boolean tryAdvance(Consumer<? super Character> action) {
// 소비한 문자 반환 및 진행여부 결정
action.accept(string.charAt(currentIndex++));
return currentIndex < string.length();
}
@Override
public Spliterator<Character> trySplit() {
int restSize = string.length() - currentIndex; // 현재 위치에서 나머지 크기 구함
if (restSize < 10) return null; // 나머지가 일정크기 이하일 경우 split 하지 않음
for (int splitPos = currentIndex + restSize / 2; splitPos < string.length(); splitPos++) {
// 현재위치 + 나머지의 중간부문으로 이동 및 공백일 경우 split
if (Character.isWhitespace(string.charAt(splitPos))) {
Spliterator<Character> spliterator = new WordCounterSpliterator(string.substring(currentIndex, splitPos));
currentIndex = splitPos;
return spliterator;
}
}
return null;
}
@Override
public long estimateSize() {
//탐색 요소 개수
return string.length() - currentIndex;
}
@Override
public int characteristics() {
return ORDERED + SIZED + SUBSIZED + NONNULL + IMMUTABLE;
}
}
public static int countWordsSpliterator(String sentence) {
WordCounterSpliterator spliterator = new WordCounterSpliterator(sentence);
Stream<Character> stream = StreamSupport.stream(spliterator, true);
WordCounter wordCounter = stream.reduce(new WordCounter(0, true),
(word, character) -> word.accumulate(character),
(word1, word2) -> word1.combine(word2));
return wordCounter.counter;
}
public static void main(String[] args) {
String sentence = "Nel mezzo del cammin di nostra vita " +
"mi ritrovai in una selva oscura" +
" che la dritta via era smarrita ";
System.out.println("Found " + countWordsSpliterator(sentence) + " words");
// Found 19 words
}
Optional
Java 에서 NPE(NullPointerException) 를 피하기위해 만들어진 구조
Optional 은 Serializable 를 구현하지 않음으로 직렬화가 불가능하다.
객체 필드로 사용하기 보단 아래처럼 메서드를 사용해 가져오는 것을 권장한다.
public class Person {
private Car car;
public Optional<Car> getCarAsOptional() {
return Optional.ofNullable(car);
}
}
Map<String, Object> 의 value 를 가져오기 위해 get(String key) 같은 null 위험성이 있는 메서드를 사용할때 Optional 를 사용하면 좋다.
Optional<Object> value = Optional.ofNullable(map.get("key"));
Optional 를 사용하면 좀더 좀더 직관적인 유틸리티 메서드를 만들 수 있다.
public static Optional<Integer> stringToInteger(String s) {
try{
return Optional.of(Integer.parseInt(s));
} catch(Exception e) {
return Optional.empty();
}
}
Optional 생성방법
Optional<Car> optCar1 = Optional.empty(); // 빈 Optional 객체 생성
Car car = new Car();
Optional<Car> optCar2 = Optional.of(car); // Optional 객체 생성, car가 null이라면 NPE 발생
Car nullCar = null;
Optional<Car> optCar2 = Optional.ofNullable(nullCar); // nullable Optional 객체 생성
empty of ofNullable 3가지 메서드로 생성 가능
Optional<Car> optCar1 = Optional.empty();
Car car = null;
Optional<Car> optCar2 = Optional.ofNullable(car);
System.out.println(optCar1 == optCar2); // true
empty 는 Optional의 static 메서드로 사전 정의된 싱글턴 객체를 반환
ofNullable 또한 전달받은 Object가 null일경우 동일한 싱글턴 객체를 반환
== 연산자로 참조위치까지 동일한 객체임을 알 수 있음.
Optional.map
stream 의 map 메서드와 비슷, 요소의 개수가 하나인 컬렉션으로 생각할 수있다.
Optional<Car> optCar = Optional.empty();
Optional<String> carName = optCar.map(Car::getName);
반환값이 Optional 이며 요소(Car)가 null이라 해도 에러가 반환되지 않는다.
이런식으로 NPE 지옥에서 빠져나갈 수 있다.
객체 내부의 객체내부의 객체…. 의 요소 또한 이런식으로 가져올 수있을 것 같지만 map 이 아닌 flatMap 을 사용해야 한다.
아래처럼 Optional 에 감싸진 Optional 을 가져오기 때문
Optional<Car> optCar = Optional.empty();
Optional<Optional<Engine>> carEngine = optCar.map(Car::getEngine);
Optional<String> carName = optCar
.flatMap(Car::getEngine)
.map(Engine::getName);
Optional 언랩
Optional 내부의 요소를 가져오는 여러가지 메서드
get() - 값이 없으면 NoSuchElementException 발생, 가장 간단하지만 Optional 객체 목적을 위반
orElse(T other) - 값이 없으면 대체할 기본값 제공.
orElseGet(Supplier<? extends T> supplier) - orElse 와 비슷한 메서드, 값이 없으면 Supplier 실행, 디폴트 메서드 생성에 리소스가 많이 필요하기에 꼭 필요한 경우에만 사용할 것.
Engine test = optCar.flatMap(Car::getEngine).orElseGet(() -> {
Engine engine = new Engine();
return engine;
});
orElseThrow(Supplier<? extends T> exceptionSupplier) - 값이 없으면 예외를 발생, 예외 객체를 Supplier 를 통해 지정가능.
ifPresent(Consumer<? super T> consumer) - 값이 있을경우에만 Consumer 실행
ifPresent(Consumer<? super T> action, Runnable emptyAction) - 값이 있을경우 Consumer 실행, 없을경우 Runnable 실행