Elastic Search - Nori!
한글 유니코드
좀더 상세한 한글처리를 하려면 한글 유니코드에 대한 이해가 필요하다.
유니코드는 전세계 문자를 모두 표현하기 위한 코드로, 한글은 유니코드의 기본 영역인 0x0000 ~ 0xFFFF 내부에 정의돼 있다.
기본영역안에 한글, 한자, 가타카나, 로마자 등이 포함되어 있다.
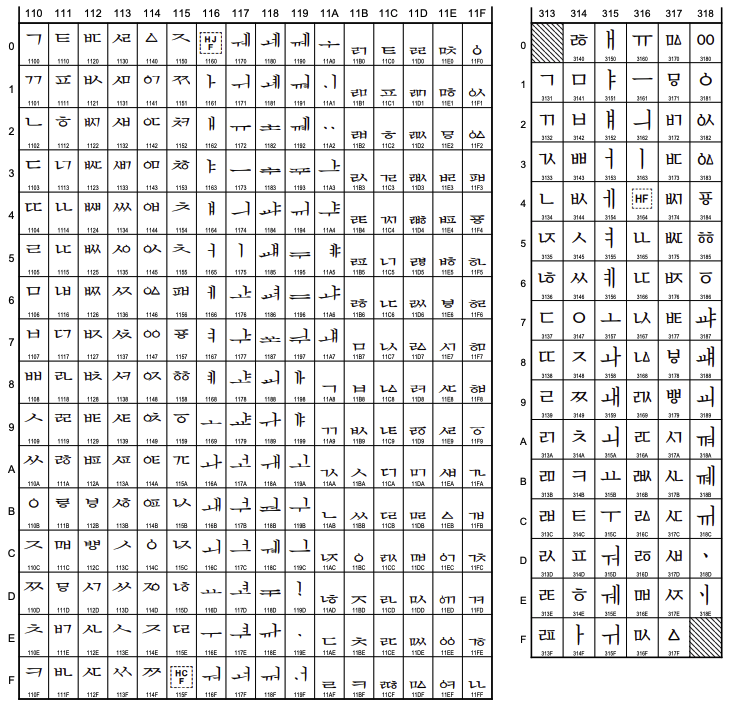
- Hangul Jamo(한글 자모)
0x1100 ~ 0x11FF총 256
https://unicode.org/charts/PDF/U1100.pdf - Hangul Compatibility Jamo(한글호환형 자모)
0x3130 ~ 0x318F총 96
https://unicode.org/charts/PDF/U3130.pdf - Hangul Syllables(한글 음절)
0xAC00 ~ 0xD7AF총 11184
https://unicode.org/charts/PDF/UAC00.pdf
주로 사용하는 한글 유니코드는 Hangul Syllables, Hangul Compatibility 이다.
유니코드 목록의 예시는 아래 그림을 참고
초성 중성 종성
먼저 한글의 한글 음절 이 어떻게 자모 구성되는지 사전지식이 필요하다.
한글음절은 자모의 결합으로 글자를 표현하고 조합된 자모는 [초성, 중성, 종성] 으로 구분된다.
초성: 처음 소리인 자음, 님 에서 ㄴ
중성: 중간 소리인 모음, 님 에서 ㅣ
종성: 끝 소리인 자음, 님 에서 ㅁ
초성, 중성, 종성을 조합해서 한글 음절 한 글자를 만들수 있다.
이중 한글 자음과 모음을 표현하는 유니코드는 아래와 같다.
public static final char[] CHO_SUNG = { // 19개
'ㄱ', 'ㄲ', 'ㄴ', 'ㄷ', 'ㄸ',
'ㄹ', 'ㅁ', 'ㅂ', 'ㅃ', 'ㅅ',
'ㅆ', 'ㅇ', 'ㅈ', 'ㅉ', 'ㅊ',
'ㅋ', 'ㅌ', 'ㅍ', 'ㅎ'
};
public static final char[] JUNG_SUNG = { // 21개
'ㅏ', 'ㅐ', 'ㅑ', 'ㅒ', 'ㅓ',
'ㅔ', 'ㅕ', 'ㅖ', 'ㅗ', 'ㅘ',
'ㅙ', 'ㅚ', 'ㅛ', 'ㅜ', 'ㅝ',
'ㅞ', 'ㅟ', 'ㅠ', 'ㅡ', 'ㅢ',
'ㅣ'
};
public static final char[] JONG_SUNG = { // 28개
' ', 'ㄱ', 'ㄲ', 'ㄳ', 'ㄴ',
'ㄵ', 'ㄶ', 'ㄷ', 'ㄹ', 'ㄺ',
'ㄻ', 'ㄼ', 'ㄽ', 'ㄾ', 'ㄿ',
'ㅀ', 'ㅁ', 'ㅂ', 'ㅄ', 'ㅅ',
'ㅆ', 'ㅇ', 'ㅈ', 'ㅊ', 'ㅋ',
'ㅌ', 'ㅍ', 'ㅎ'
};
한글음절 구성에 규칙을 알고있고 [초성, 중성, 종성] 개수를 사전에 알고 있기 때문에 한글음절 한글자에 대한 규칙을 아래와 같이 정할 수 있다.
(초성순서 X 21 X 28) + (중성순서 X 28) + 종성순서 + 0xAC00
예로 곰 이란 글자의 [초성, 중성, 종성] 의 인덱스는 아래와 같은데
- 초성 인덱스: 0
- 중성 인덱스: 8
- 종성 인덱스: 16
인덱스를 규칙에 넣어 계산해보면 아래와 같은 유니코드가 나오는것을 알 수 있다.
0 X 21 X 28 + 8 X 28 + 16 + 0xAC00
= 240 + 44032
= 44272
= 0xACF0
반대로 한글음절 한문자를 [초성, 중성, 종성] 으로 분리하려면 아래 연산을 수행하면 된다.
초성 인덱스 = 유니코드 / (21 X 28)
중성 인덱스 = (유니코드 % (21 X 28)) / 28
종성 인덱스 = (유니코드 % (21 X 28)) % 28
한글 유니코드의 특징을 사용하여 자모를 음절로, 음절을 자모로 변경가능하다.
노리 (nori)
https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-nori.html
한글은 조사, 접미사, 명사, 동사 등이 결합되어 복합적을 단어를 구성한다.
이런 복합적인 단어를 복합명사라 하며 형태소 분석을 하려면 복합명사를 분리할 수 있어야 한다.
이를 위해 사용자 사전 을 만들어 복합명사 분리에 사용한다.
한글 형태소 분석기의 경우 아리랑, 은전한닢, Nori 등이 있는데
Lucene 에서 공식적으로 지원되고 기본 플러그인으로 포함되어 있는건 Nori 가 유일하다.
elasticsearch-plugin install analysis-nori
-> Downloading analysis-nori from elastic
[=================================================] 100%??
-> Installed analysis-nori
Nori 는 아래와 같이 구성되어 있다.
nori_tokenizer토크나이저nori_path_of_speech토큰필터nori_readingform토큰필터
nori_tokenizer 토크나이저
복합명사를 형태소로 나누기 위해 decompound_mode, user_dictionary 두가지 파라미터를 제공한다.
PUT nori_analyzer
{
"settings": {
"index": {
"analysis": {
"tokenizer": {
"nori_user_dict_tokenizer": {
"type": "nori_tokenizer",
"decompound_mode": "mixed",
"user_dictionary": "userdict_ko.txt"
}
},
"analyzer": {
"nori_token_analyzer": {
"type": "custom",
"tokenizer": "nori_user_dict_tokenizer"
}
}
}
}
}
}
user_dictionary
사용자 커스텀한 복합명사를 지정하고 싶다면 user_dictionary 를 지정하면 된다.
userdict_ko.txt 는 Elastic Search 에서 사용하는 config 디렉토리에 아래와 같이 저장
// userdict_ko.txt
삼성전자
삼성전자 삼성 전자
user_dictionary 를 사용해 사용자 사전 을 지정하지 않더라도 기본적으로 세종말뭉치, mecab-ko-dic 를 사용해 토큰화를 지원한다.
decompound_mode
복합명사를 토크나이저가 처리하는 방식을 결정하며 아래 3 가지 방식이 있음.
none: 별도의 토큰화 하지 않음discard: 복합명사로 구분, 원본데이터 삭제,[잠실역] → [잠실, 역]mixed: 복합명사로 구분, 원본데이터 유지,[잠실역] → [잠실, 역, 잠실역]
POST nori_analyzer/_analyze
{
"analyzer": "nori_token_analyzer",
"text": "잠실역"
}
// result
{
"tokens": [
{
"token": "잠실역",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0,
"positionLength": 2
},
{
"token": "잠실",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "역",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 1
}
]
}
nori_part_of_speech 토큰 필터
한글 불용어(stoptags)를 제거하는 토큰 필터
PUT nori_analyzer/_settings
{
"index": {
"analysis": {
"analyzer": {
"nori_stoptags_analyzer": {
"tokenizer": "nori_tokenizer",
"filter": [
"nori_posfilter"
]
}
},
"filter": {
"nori_posfilter": {
"type": "nori_part_of_speech",
"stoptags": [
"E", "IC", "J", "MAG", "MAJ", "MM", "NA", "NR",
"SC", "SE", "SF", "SH", "SL", "SN", "SP", "SSC",
"SSO", "SY", "UNA", "UNKNOWN", "VA", "VCN", "VCP",
"VSV", "VV", "VX", "XPN", "XR", "XSA", "XSN", "XSV"
]
}
}
}
}
}
결과는 아래와 같다.
POST nori_analyzer/_analyze
{
"analyzer": "nori_stoptags_analyzer",
"text": "그대 이름은 장미"
}
// result
{
"tokens": [
{
"token": "그대",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "이름",
"start_offset": 3,
"end_offset": 5,
"type": "word",
"position": 1
},
{
"token": "장미",
"start_offset": 7,
"end_offset": 9,
"type": "word",
"position": 3
}
]
}
| 값(tag) | 영문명 | 한글명 | 예시 |
|---|---|---|---|
| E | Verbal endings | 어미 | 사랑/하(E)/다 |
| IC | Interjection | 감탄사 | 와우(IC), 맙소사(IC) |
| J | Ending Particle | 조사 | 나/는(J)/너/에게(J) |
| MAG | General Adverb | 일반 부사 | 빨리(MAG)/달리다, 과연(MAG)/범인/은/누구/인가 |
| MAJ | Conjunctive adverb | 접속 부사 | 그런데(MAJ), 그러나(MAJ) |
| MM (*) | ES:Modifier(한정사), Lucene API:Determiner(관형사) | 설명이 다름 | 맨(MM)/밥 |
| NA | Unknown | 알 수 없음 | |
| NNB | Dependent noun (following nouns) | 의존명사 | |
| NNBC | Dependent noun | 의존명사(단위를 나타내는 명사) | |
| NNG | General Noun | 일반 명사 | 강아지(NNG) |
| NNP | Proper Noun | 고유 명사 | 비숑(NNP) |
| NP | Pronoun | 대명사 | 그것(NP), 이거(NP) |
| NR | Numeral | 수사 | 하나(NR)/밖에, 칠(NR)/더하기/삼(NR) |
| SC(*) | Separator (· : /) | 구분자 | nori_tokenizer가 특수문자 제거 |
| SE(*) | Ellipsis | 줄임표(…) | nori_tokenizer가 특수문자 제거 |
| SF(*) | Terminal punctuation (? ! .) | 물음표, 느낌표, 마침표 | nori_tokenizer가 특수문자 제거 |
| SH | Chinese character | 한자 | 中國(SH) |
| SL | Foreign language | 외국어 | hello(SL) |
| SN | Number | 숫자 | 1(SN) |
| SP | Space | 공백 | |
| SSC(*) | Closing brackets | 닫는 괄호 ),] | nori_tokenizer가 특수문자 제거 |
| SSO(*) | Opening brackets | 여는 괄호 (,[ | nori_tokenizer가 특수문자 제거 |
| SY | Other symbol | 심벌 | |
| UNA | Unknown | 알 수 없음 | |
| UNKNOWN | Unknown | 알 수 없음 | |
| VA | Adjective | 형용사 | 하얀(VA)/눈 |
| VCN | Negative designator | 부정 지정사(서술격조사) | 사람/이/아니(VCN)/다 |
| VCP | Positive designator | 긍정 지정사(서술격조사) | 사람/이(VCN)/다 |
| VSV | Unknown | 알 수 없음 | |
| VV | Verb | 동사 | 움직이(VV)/다,먹(VV)/다 |
| VX | Auxiliary Verb or Adjective | 보조 용언 | 가지/고/싶(VX)/다, 먹/어/보(VX)/다 |
| XPN(*) | Prefix | 접두사(체언 접두사?) | ES에서 매핑되는 단어를 찾지 못함 |
| XR(*) | Root | 어근 | ES에서 매핑되는 단어를 찾기 못함 |
| XSA | Adjective Suffix | 형용사 파생 접미사 | 멋/스럽(XSA)/다 |
| XSN(*) | Noun Suffix | 명사 파생 접미사 | ES에서 매핑되는 단어를 찾기 못함 |
| XSV(*) | Verb Suffix | 동사 파생 접미사 | ES에서 매핑되는 단어를 찾기 못함 |
nori_readingform 토큰 필터
문서에 존재하는 한자를 한글로 변경하는 필터
PUT nori_readingform
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"nori_readingform_analyzer": {
"tokenizer": "nori_tokenizer",
"filter": [ "nori_readingform" ]
}
}
}
}
}
}
POST nori_readingform/_analyze
{
"analyzer": "nori_readingform_analyzer",
"text": "中國"
}
// result
{
"tokens": [
{
"token": "중국",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
}
]
}
Term Suggester API
오타수정을 위한 Term Suggester API, 자동완성을 위한 Completion Suggester API 서비스를 구성할 수 있다.
맞춤법 오타의 경우 아래와 같이 자모로 분리하고
샴성전자의 경우ㅅㅑㅁㅅㅓㅇㅈㅓㄴㅈㅏ삼성전자의 경우ㅅㅏㅁㅅㅓㅇㅈㅓㄴㅈㅏ
두 한글의 자모로 분리된 문자열의 편집거리를 측정하여 오타수정이 가능하다.
그리고 한글 검색에서 자주 실수 하는것이 한영키 오타이다.
삼성전자를 영문으로 입력할경우tkatjdwjswksamsung을 한글로 입력할 경우ㄴ므녀ㅜㅎ
영문과 한문을 잘못입력했을 때 이를 교정하려면 자모와 영문을 키보드 위치에 맞게 변환할 수 있어야 한다.
아래와 같이 영문-자모 매핑 배열을 정의해두면 한영키 오타교정이 가능하다.
// 키보드상에서 한영키에 의해서 오타 교정이 필요한 키배열 (영문키 33자)
public static final String[] KEYBOARD_KEY_ENG = {
"a", "b", "c", "d", "e", "f", "g", "h", "i", "j",
"k", "l", "m", "n", "o", "p", "q", "r", "s", "t",
"u", "v", "w", "x", "y", "z", "Q", "W", "E", "R",
"T", "O", "P"
};
// 키보드상에서 한영키에 의해서 오타 교정이 필요한 키배열 (한글키 33자)
public static final String[] KEYBOARD_KEY_KOR = {
"ㅁ", "ㅠ", "ㅊ", "ㅇ", "ㄷ", "ㄹ", "ㅎ", "ㅗ", "ㅑ", "ㅓ",
"ㅏ", "ㅣ", "ㅡ", "ㅜ", "ㅐ", "ㅔ", "ㅂ", "ㄱ", "ㄴ", "ㅅ",
"ㅕ", "ㅍ", "ㅈ", "ㅌ", "ㅛ", "ㅋ", "ㅃ", "ㅉ", "ㄸ", "ㄲ",
"ㅆ", "ㅒ", "ㅖ"
};
Completion Suggester API
completion 옵션을 사용할경우 prefix 기준으로 문서를 찾기 때문에 한글과는 어울리지 않는다.
한글의 경우 복합명사가 많아 전방일치 자동완성 외의 기능은 구현하기 힘들다.
만약 전방일치 자동완성만 구현해도 된다하면 기존 영문 Completion Suggester API 방식을 사용하면 된다.
예로 아래와 같이 인덱스를 정의, 문서 3개 추가, prefix 로 신혼을 지정하면
문서 3개 모두 신혼 문자열로 시작하기 때문에 3개 문서가 suggest 로 출력된다.
PUT /ac_test
{
"settings": {
"index": {
"number_of_shards": 5,
"number_of_replicas": 1
}
},
"mappings": {
"_doc": {
"properties": {
"itemSrc": { "type": "keyword" },
"itemCompletion": { "type": "completion" }
}
}
}
}
POST /ac_test/_doc/1
{ "itemSrc": "신혼", "itemCompletion": "신혼" }
POST /ac_test/_doc/2
{ "itemSrc": "신혼가전", "itemCompletion": "신혼가전" }
POST /ac_test/_doc/3
{ "itemSrc": "신혼가전특별저", "itemCompletion": "신혼가전특별전" }
GET /ac_test/_search
{
"suggest": {
"ac_test_completion": {
"prefix": "신혼",
"completion": {
"field": "itemCompletion",
"size": 10
}
}
}
}
completion 기능은 메모리에 로드되어 빠르지만, 한글의 경우 부분일치 자동완성 을 구현하기 위해 속도에서 일부 손해를 보더라도 Lucene에서 제공하는 검색쿼리를 많이 사용한다.
분석기에서 배웠던 토크나이저(ngram, edge_ngram) 와 토큰필터(edge_ngram back)를 사용하면 왠만한 글자는 모두 자동완성처리할 수 있다.
아래와 같이 ngram, edge_ngram, edge_ngram back 을 지원하는 토크나이저와, 토큰필터를 정의하고 3가지 분석기를 생성.
// 인덱스 생성
PUT /ac_test2
{
"settings": {
"index": {
"number_of_shards": 5,
"number_of_replicas": 1
},
"analysis": {
"analyzer": {
"ngram_analyzer": { "tokenizer": "ngram_tokenizer" },
"edge_ngram_analyzer": { "tokenizer": "edge_ngram_tokenizer" },
"edge_ngram_analyzer_back": {
"tokenizer": "edge_ngram_tokenizer",
"filter": [ "edge_ngram_filter_back" ]
}
},
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram", "min_gram": "1", "max_gram": "50",
"token_chars": [ "letter" ]
},
"edge_ngram_tokenizer": {
"type": "edge_ngram", "min_gram": "1", "max_gram": "50",
"token_chars": [ "letter" ]
}
},
"filter": {
"edge_ngram_filter_back": {
"type": "edge_ngram", "min_gram": "1", "max_gram": "50",
"side": "back"
}
}
}
},
"mappings": {
"_doc": {
"properties": {
"item": {
"type": "keyword",
"boost": 30
},
"itemNgram": {
"type": "text",
"analyzer": "ngram_analyzer",
"search_analyzer": "ngram_analyzer",
"boost": 3
},
"itemNgramEdge": {
"type": "text",
"analyzer": "edge_ngram_analyzer",
"search_analyzer": "ngram_analyzer",
"boost": 2
},
"itemNgramEdgeBack": {
"type": "text",
"analyzer": "edge_ngram_analyzer_back",
"search_analyzer": "ngram_analyzer",
"boost": 1
}
}
}
}
}
// 문서 삽입
POST /ac_test2/_doc/1
{
"item": "신혼",
"itemNgram": "신혼",
"itemNgramEdge": "신혼",
"itemNgramEdgeBack": "신혼"
}
POST /ac_test2/_doc/2
{
"item": "신혼가전",
"itemNgram": "신혼가전",
"itemNgramEdge": "신혼가전",
"itemNgramEdgeBack": "신혼가전"
}
POST /ac_test2/_doc/3
{
"item": "신혼가전특별전",
"itemNgram": "신혼가전특별전",
"itemNgramEdge": "신혼가전특별전",
"itemNgramEdgeBack": "신혼가전특별전"
}
토크나이저와 토큰필터로 문자 하나하나씩 ngram 방식으로 조립해두었기 때문에 왠만한 문자열에 대해 검색 가능하다.
GET /ac_test2/_search
{
"query": {
"bool": {
"should": [
{ "term": { "item": "신혼" } },
{ "term": { "itemNgram": "신혼" } },
{ "term": { "itemNgramEdge": "신혼" } },
{ "term": { "itemNgramEdgeBack": "신혼" } }
],
"minimum_should_match": 1
}
}
}