Redis 영속성 PubSub Stream!
데이터 영속성
인메모리 DB 특성상 서버가 재부팅 될 경우 데이터가 날라간다.
이를 방지하기 위한 기술이 두가지 있다.
- 스냅숏
특점 시점(한시간, 하루, 한달 등)을 지정해서 내용을 RDB(RedisDataBase) 압축포멧 파일로 저장하여 복원. - AOF(Append Only File: 추가전용파일)
write 작업 수행할 때 마다 로그처럼 기록하는 형식, 로그 파일 을 재생하는 방식으로 데이터를 복원.
스냅숏 RDB 파일보다 사이즈가 크고 복원속도가 느리다.
일부 손실되어도 상관 없다면 스냅숏만 사용하는것을 권장한다.
데이터 영속성이 중요하다면 스냅숏/AOF 를 같이 사용하는 혼합형식을 권장한다.
스냅숏
스냅숏 실행 전에 메모리, 디스크, 서비스 사용량을 확인하고 진행해야한다.
스냅숏 실행은 대부분 replica 에서 진행된다.
- 특정 시점에 스냅숏 실행
- 직접 스케줄러 설정 해야함.
- SAVE(동기), BGSAVE(비동기) 명령으로 수동으로 스냅숏 실행
- 싱글스레드로 동작하기에 SAVE 사용한 권장하지 않음
- 조건 만족시 스냅숏 실행, 아래 default 조건이 있음
- 1시간 내에 최소 하나 이상 write
- 5분 내에 최소 100개 이상 write
- 1분 내에 최소 10000개 이상 write
서버의 종료가 발생했을 때 스냅숏 시점 이후에 데이터는 손실된다.
AOF
AOF 설정은 default disable, AOF 는 실시간 백업처럼 기록되기 떄문에 내구성이 높다.
AOF 도 무적은 아니다, write 요청을 버퍼공간에 보관하고 있다가 파일에 기록하기 때문에 file flush 전에 서버가 종료되면 데이터는 손실된다.
- no(default) AOF 비활성화
- always write 작업마다 file flush, 손실 없음
- everysec(권장) 매초마다 buffer 에서 file flush, 최대 1초 데이터 손실
레플리케이션
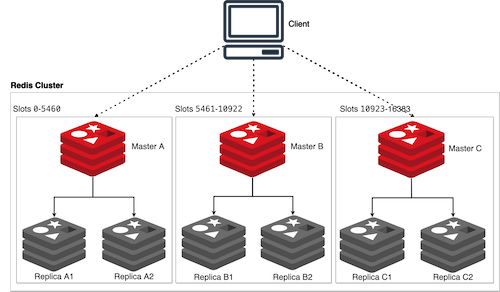
- 읽기 작업 확장을 통한 고가용성 확보
- 중복 데이터 구성으로 인한 failover 안정성 확보
레플리케이션 메커니즘은 아래와 같다.
- 동기화는 PSYNC 명령어(Partial SYNC, 이벤트 루프 비동기 논블로킹 방식)으로 구현.
- 서버에 연결을 요청, 현 시점까지의 오프셋을 전송
- 백로그에서 요청한 오프셋을 확인
- 오프셋을 백로그에서 찾을 수 있다면 부분동기화를 진행
- 오프셋을 백로그에서 찾을 수 없다면 전체동기화를 진행
- 네트워크가 정상 연결된 상태에선 실시간 쓰기 명령을 레플리카에 전송한다.
- 레플리카에서는 TTL로 키를 만료시키지 않으며 마스터로 부터 DEL 명령어를 수신받아 동기화한다.
repl-disable-tcp-nodelay=no(default) 비활성화 할 경우 쓰기명령을 실시간으로 레플리카에 전송한다.
yes 로 활성화 할 경우 명령어를 압축 전송하여 동기화 지연이 발생하지만 네트워크 대역을 확보할 수 있다.
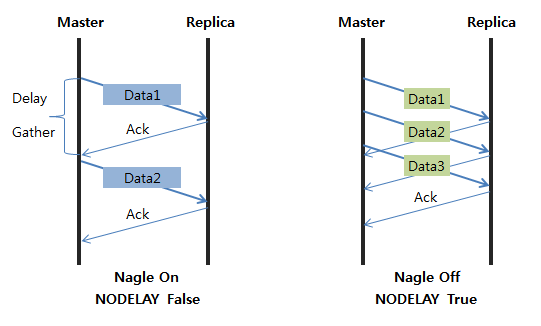
nodelay 라 하더라도 쓰기 명령을 전송하는 과정에서 마스터와 레플리카 내의 데이터가 동일하다고 보장할 수 없다.
전체동기화 메커니즘은 아래와 같다.
- 마스터는 BGSAVE 명령을 통해 비동기적으로 RDB 파일 생성 및 레플리카에 전달
- 마스터는 BGSAVE 시작 이후 쓰기요청은 레플리카의 출력버퍼에 전달
- 레플리카는 RDB 와 출력버퍼의 명령을 순차적으로 메모리에 적재
- 마스터는 실시간으로 쓰기 작업을 레플리카에 전송
여러개의 레플리카가 동시 전체동기화 진행시 BGSAVE 가 진행중이라면 해당 RDB 를 수신받고,
이미 RDB 가 생성되어 있는 경우 새로운 BGSAVE 를 실행하여 새로운 전체동기화를 수행한다.
RDB 를 저장하기 위한 디스크 공간이 없을 수 있으며 S3 와 같은 네트워크 저장공간을 사용하여 전체동기화 과정을 수행할 수 도 있다.
새로 생성된 전체동기화 되지 않은 레플리카 서버도 정상동작한다.
이를 막고싶다면replica-serve-staledata=no로 설정하면전체동기화완료 전까진 에러를 반환한다(SYNC with master in progress).
부분동기화 메커니즘은 아래와 같다.
- 네트워크가 일시적으로 끊길경우 부분동기화를 수행한다.
- 마스터는 쓰기 작업 정보를
레플리케이션 백로그에 저장한다. - 레플리카는 연결이 끊어진 동안의 모든 쓰기작업을 백로그에서 가져온다.
repl-backlog-size=1MB # 백로그의 유지 크기
repl-backlog-ttl=3600 # 백로그 유지 시간
연결이 끊겨 레플리카의 출력버퍼보다 많은 양의 쓰기정보가 전달되면 동기화가 실패되고 재동기화(부분동기화)를 수행한다.
부분동기화 수행이 불가능할경우 전체동기화를 수행한다.
레플리케이션 failover
마스터는 기본 10초 간격으로 모든 레플리카에 ping 을 보낸다, 레플리카도 마스터에 매초 ping 을 보낸다.
마스터는 마지막으로 ping 을 받은 후 일정시간동안 다음 ping 이 도착하지 않으면 레플리카 끊김 상태로 인식한다(기본 60초).
최소 레플리카 연결 개수를 충족하지 않으면 마스터는 더이상의 쓰기작업을 수행하지 않는다(기본 충족값은 0).
레플리케이션 환경에서 마스터 노드가 장애가 발생했을 때 레플리카 노드가 자동으로 마스터로 승격되는 기능은 없다.
아래 명령어를 통해 래플리카를 마스터로 승격하고 다른 래플리카들에게 새로운 마스터 노드 주소를 알려야한다.
# 새로운 마스터 승격 레플리카에서 실행
REPLICAOF NO ONE
# 새로운 레플리카들에서 실행
REPLICAOF <master ip> <matser port>
센티널을 사용하면 합의알고리즘을 통해 자동으로 마스터 노드를 선정할 수 있다.
클러스터링
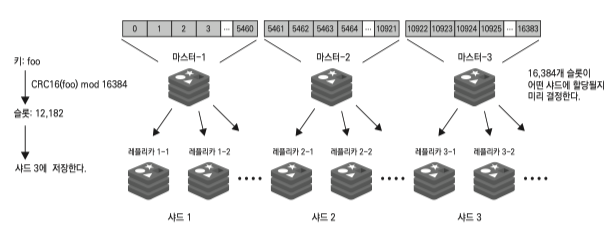
- 마스터 노드 장애 발생시 자동 failover 기능을 지원한다.
- 16384 개의 해시 슬롯과 moduler 연산을 사용해 샤딩 기능을 지원한다.
key range 파티셔닝도 있긴한데 잘 사용하지 않음.
클러스터에서 명령어 실행에 대한 메커니즘은 아래와 같다.
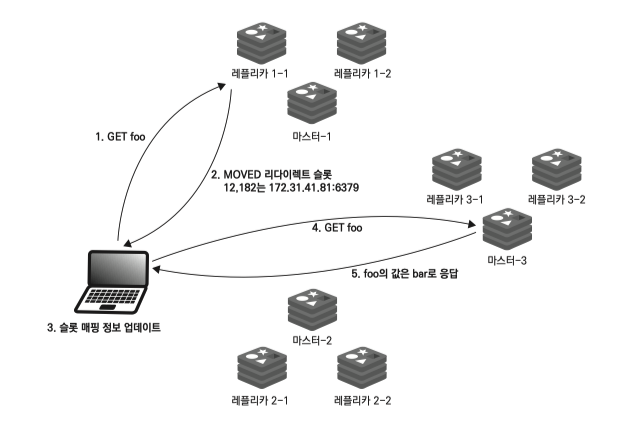
클라이언트는 첫 요청시 아무 노드에 연결을 시도하며 슬롯에 데이터가 없으면 MOVED 를 통해 리다이렉트 되어 다시 노드에 접근한다.
이떄 MOVED 전달하는 노드는 항상 마스터 노드이다.
읽기 요청에 대해 설명
- 클러스터 노드 IP 에 접속
- 레플리카/마스터 상관없이 동일하게 동작
- 슬롯 내부에 값이 존재하면 읽어서 반환.
- 슬롯 내부에 값이 없으면 MOVED 를 클라이언트에 응답.
- 클라이언트는 로컬 슬롯/서버 매핑을 업데이트.
쓰기 요청에 대해 설명
- 클러스터 노드 IP 에 접속
- 레플리카 노드인 경우.
- 마스터 MOVED 를 클라이언트에 응답.
- 클라이언트는 로컬 슬롯/서버 매핑을 업데이트.
- 마스터 MOVED 를 클라이언트에 응답.
- 마스터 노드인 경우.
- 슬롯 내부에 값이 존재하면 쓰기 처리.
- 슬롯 내부에 값이 없으면 MOVED 를 클라이언트에 응답.
- 클라이언트는 로컬 슬롯/서버 매핑을 업데이트.
레디스 클러스터를 사용하려면 클라이언트에서 MOVED 리다이렉트를 지원해야한다.
또한 성능향상을 위해 샤드별 슬롯매핑정보를 유지/업데이트하는 기능을 클라이언트에서 지원하면 좋다.
ASK 리다이렉트도 있는데 키가 이동중에 있어 확실하게 저장되어있는 상태인지 알지 못할 때 사용하는 명령어이다.
노드 재구성중이라면 ASK 리다이렉트가 전송될 수 도 있다.
클러스터 failover
16379번 포트를 통해 노드간 통신환경을 구성하며 클러스터 버스 라 부른다.
클러스터 버스를 통해 모든 노드는 완전메쉬형태로 연결된다.
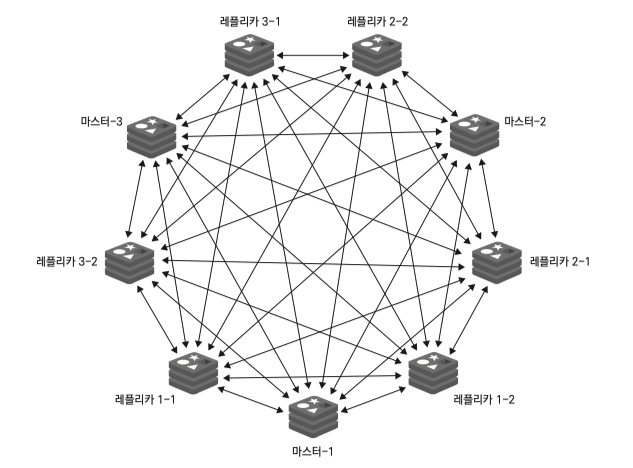
노드들은 클러스터 버스를 통해 설정, 상태 등의 정보들을 주기적으로 교환한다.
완전 메시로 연결되어 있지만 모든 연결 노드에 ping 을 보내지는 않고 랜덤으로 선택하여 핑을 보내고 응답을 받는다.
노드가 늘어나더라도 ping 패킷 총량은 일정하도록 유지한다.
가십 프로토콜(gossip protocol) 이라 부르며 자신과 다른 노드들의 상태를 전파한다.
이를 통해 최신 상태정보가 클러스터로 퍼져나가게 된다.
상태값은 아래 2가지, 가십 프로토콜을 통해 해당 상태를 전파하며 노드들은 다른 노드들의 생존여부를 확인한다.
- PFAIL 상태(Possible Failure)
- 다른 노드에 핑을 보내고
cluster-node-timeout이내에 응답이 오지 않을 때 해당 노드를 PFAIL 로 표시.
- 다른 노드에 핑을 보내고
- FAIL 상태
- 과반수의 마스터 노드가 대상 노드를 PFAIL 혹은 FAIL 상태로 판단하는 경우
- FAIL 상태로 판단에 걸리는 수식은 아래와 같다.
cluster-node-timeout * cluster-replica-validity-factor
cluster-replica-validity-factor값은 사용자의 설정값,
투표로 FAIL 상태 업데이트를 결정하기에 과반수 이상의 노드가 장애가 발생하면 복구되지 않는다.
승격 레플리카의 선출 과정은 아래와 같다.
- 마스터의 FAIL 상태 확인
- 레플리카는
cluster-node-timeout * 2시간동안 대기 후 다른 마스터 노드들에게 인증 패킷 브로드캐스트 - 각 마스터들은 raft 합의 알고리즘을 통해 투표로 응답
- 과반수의 투표를 받은 레플리카가 승격, 과반수에 도달하지 못하면 재투표를 진행
PubSub
채널을 통해 이벤트를 공유한다.
모든 어플리케이션의 메세지 브로드캐스팅, 로컬 캐시 동기화, 키 삭제/만료 핸들링 등에 사용될수 있다.
클러스터링 환경에서 채널이름이 key 로 사용되어 샤딩처리 되기때문에 하나의 채널을 분산하여 메세지 Publish 환경을 구성해야 한다.
# 지정 채널 구독하기
# SUBSCRIBE channel [ channel ...]
SUBSCRIBE redis-interest memcached-interest mongodb-interest
# 1) "subscribe"
# 2) "redis-interest"
# 3) (integer) 1
# 1) "subscribe"
# 2) "memcached-interest"
# 3) (integer) 2
# 1) "subscribe"
# 2) "mongodb-interest"
# 3) (integer) 3
# Reading messages... (press Ctrl-C to quit or any key to type command)
패턴으로 채널 구독이 가능하다. 편하지만 클채널에 연결된 라이언트 수 만큼 루프를 돌아야한다.
# 지정 패턴으로 채널 구독
PSUBSCRIBE *-interest
# 1) "psubscribe"
# 2) "*-interest"
# 3) (integer) 1
# PUBLISH channel message
PUBLISH redis-interest " Hey , guys . Good news about Redis ."
# SUBSCRIBE 에서 출력된 메세지
# 1) "message"
# 2) "redis-interest"
# 3) " Hey , guys . Good news about Redis ."
# PSUBSCRIBE 에서 출력된 메세지
# 1) "pmessage"
# 2) "*-interest"
# 3) "redis-interest"
# 4) " Hey , guys . Good news about Redis ."
Keyspace Notifications
키 공간 알림 기능
# By default all notifications are disabled because most users don't need
# this feature and the feature has some overhead. Note that if you don't
# specify at least one of K or E, no events will be delivered.
# notify-keyspace-events ""
notify-keyspace-events "KEA"
K: 키 공간 알림E: 키 이벤트 알림A: 아래g$lshzxe별칭g: 일반 명령어$: 문자열형 명령어l: 리스트형 명령어s: Set형 명령어h: Hash형 명령어z: Sorted Set형 명령어x: 만료 이벤트e: 제거 이벤트
KEA 설정하면 모든 알림에 대해 수신설정을 할 수 있다.
발행되는 알림은 아래 2가지
- 키 공간 알림:
__keyspace@<db>__:<key> - 키 이벤트 알림:
__keyevent@<db>__:<event>
모든 알림을 구독할 때에는 아래 명령어 사용.
# 콘솔에서 config 구성 변경
redis-cli CONFIG SET notify-keyspace-events KEA
# 패턴구독
PSUBSCRIBE '__key*__:*'
SET mykey test 명령 수행시 발행되는 이벤트
# 1) "pmessage"
# 2) "__key*__:*"
# 3) "__keyspace@0__:mykey"
# 4) "set"
# 1) "pmessage"
# 2) "__key*__:*"
# 3) "__keyevent@0__:set"
# 4) "mykey"
DEL mykey 명령 수행시 발행되는 이벤트
# 1) "pmessage"
# 2) "__key*__:*"
# 3) "__keyspace@0__:mykey"
# 4) "del"
# 1) "pmessage"
# 2) "__key*__:*"
# 3) "__keyevent@0__:del"
# 4) "mykey"
SET mykey "Hello" EX 10 명령 수행시 발행되는 이벤트
# 1) "pmessage"
# 2) "__key*__:*"
# 3) "__keyspace@0__:mykey"
# 4) "set"
# 1) "pmessage"
# 2) "__key*__:*"
# 3) "__keyevent@0__:set"
# 4) "mykey"
# 1) "pmessage"
# 2) "__key*__:*"
# 3) "__keyspace@0__:mykey"
# 4) "expire"
# 1) "pmessage"
# 2) "__key*__:*"
# 3) "__keyevent@0__:expire"
# 4) "mykey"
만료시 발행되는 이벤트
# 1) "pmessage"
# 2) "__key*__:*"
# 3) "__keyspace@0__:mykey"
# 4) "expired"
# 1) "pmessage"
# 2) "__key*__:*"
# 3) "__keyevent@0__:expired"
# 4) "mykey"
서버 부담으로 인해 만료 이벤트만 구독하려면 아래 명령어 사용
redis-cli CONFIG SET notify-keyspace-events Ex
SET mykey "Hello" EX 5
SUBSCRIBE '__keyevent@*__:expired'
# 1) "message"
# 2) "__keyevent@0__:expired"
# 3) "mykey"
Shared PubSub
클러스터 환경에서 PubSub 을 사용하면 모든 Primary + Replica 노드에 메세지를 Publish 함으로 요청량이 많아지면 확장에 불리해진다.
redis 7.0 이후 Shared PubSub 을 지원하여 채널 이름을 기반으로 샤드처리하여 PubSub 을 수행한다.
일정 주기마다 Stream을 새로 생성하기 미리 N개의 Stream을 만들어 사용하기
# SSUBSCRIBE shardchannel [ shardchannel ...]
SSUBSCRIBE redis-interest
# SPUBLISH shardchannel message
SPUBLISH redis-interest " Hey , guys . Good news about Redis ."
SPUBLISH 메세지는 SSUBSCRIBE 으로만 받을 수 있다.
패턴구독 명령어도 지원하지 않는다.