MySQL 인덱스, 아키텍처, 트랜잭션!
인덱스
400페이지가 넘는 책을 한장씩 펼처 원하는 내용를 찾기보단 목차를 통해 찾느게 빠르듯,
DB에서도 레코드가 저장된 주소를 key-value 쌍으로 삼아 정렬된 인덱스를 생성한다.
인덱스 장단점
위의 설명대로 인덱스의 장점은 검색시 시스템 부하를 획기적으로 줄일 수 있다.
트리 구조의 저장을 통해 O(log n)의 시간을 요구한다.
단점은 인덱스를 위한 저장공간, 별도의 연산과정이 필요하다.
특히 추가/삭제 과정에서 균형이 무너질 수 있고 균형 재분배를 통해 다시 균형을 맞추는대 매우 큰 비용이 발생한다.
따라서 추가/삭제가 빈번히 일어나는 경우 오히려 성능저하 가능성이 있다.
WHERE 조건문에 자주 사용되는 칼럼, JOIN 이 많이 사용되고 NON NULL 컬럼을 인덱스로 설정하면 좋다.
물론 테이블 행 수가 적거나, INSERT/DELETE 가 자주 일어나고,
WHERE 조건으로 검색결과가 전체 데이터의 10~15% 이상이라면 인덱스를 설정하지 않는게 더 효율적일 수 있다.
인덱스의 종류
- 고유 인덱스(Unique Index)
- 비고유 인덱스(NonUnique Index)
- 단일 인덱스(Single Index)
- 결합 인덱스(Composite Index)
- 함수기반 인덱스(Function Index)
고유 인덱스 생성
기본키, 유일키에 대한 칼럼에 대한 인덱스, 제약조건에 가까운 인덱스이다.
CREATE UNIQUE INDEX index_board
ON tbl_board (b_idx)
비고유 인덱스 생성
중복값이 있는 칼럼에 대한 인덱스
CREATE INDEX index_board
ON tbl_board (b_idx)
복합 인덱스 생성
복수개의 칼럼으로 구성된 인덱스
CREATE UNIQUE INDEX index_board
ON tbl_board (b_idx, b_title)
내부적으론 2개의 칼럼을 합쳐 B Tree 를 구성하게 됨으로 결합 인덱스의 칼럼 순서가 중요하다.
복합 인덱스는 결합 인덱스, 다중칼럼 인덱스 등 불리우는 이름이 많다.
또 복합 인덱스 내부 칼럼만 읽는 질의 요청시 인덱스만 사용해 질의 응답하는 커버링 인덱스 방법을 사용할 수 있다.
SELECT * FROM index_board
WHERE (b_idx, b_title) IN ((1,'test_title'), (2,'hello world'));
위와 같이 튜플형태로 복합 인덱스 조회가 가능하다.
함수기반 인덱스
특정 연산이후의 만들어진 값을 인덱스로 만들고 싶을 때 함수기반 인덱스를 사용한다.
CREATE TABLE tbl_user
(
user_id BIGINT,
first_name VARCHAR(10),
last_name VARCHAR(10),
PRIMARY KEY (user_id)
);
CREATE INDEX index_full_name ON tbl_user ((CONCAT(first_name,' ',last_name)));
테이블 구조를 변경하지 않고 빠른 검색을 위한 인덱스 생성이 가능하다.
B Tree(Balanced Tree)
참고
https://www.youtube.com/watch?v=bqkcoSm_rCs
https://www.youtube.com/watch?v=H_u28u0usjA
https://cuuduongthancong.com/~galles/visualization/BTree.html
대부분의 DB 인덱스 내부구조는 B Tree 를 기반으로 한다.
다른 트리 자료구조보다 디스크 I/O를 최소화하면서도 빠른 검색, 삽입, 삭제가 가능하다.
최상위 루트노드로부터 자식노드가 붙어있는 트리형태로, 차수 만큼의 자식노드를 가질 수 있고 차수 - 1 개의 데이터를 가질 수 있다.
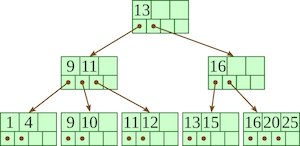
B Tree 는 이론상 탐색에서 가장 빠른 $O(\log{n})$ 의 속도를 보여준다.
위 그림의 경우 차수가 4인
B Tree
B+ Tree, B* Tree 가 인덱스에 주로 사용된다.
하나의 노드에 여러개의 데이터를 표기하게 되면서 낮은 높이의 트리구조를 가져가는것이 장점이다.
인덱스 크기에 따른 B Tree 변화
https://blog.jcole.us/2013/01/10/btree-index-structures-in-innodb/
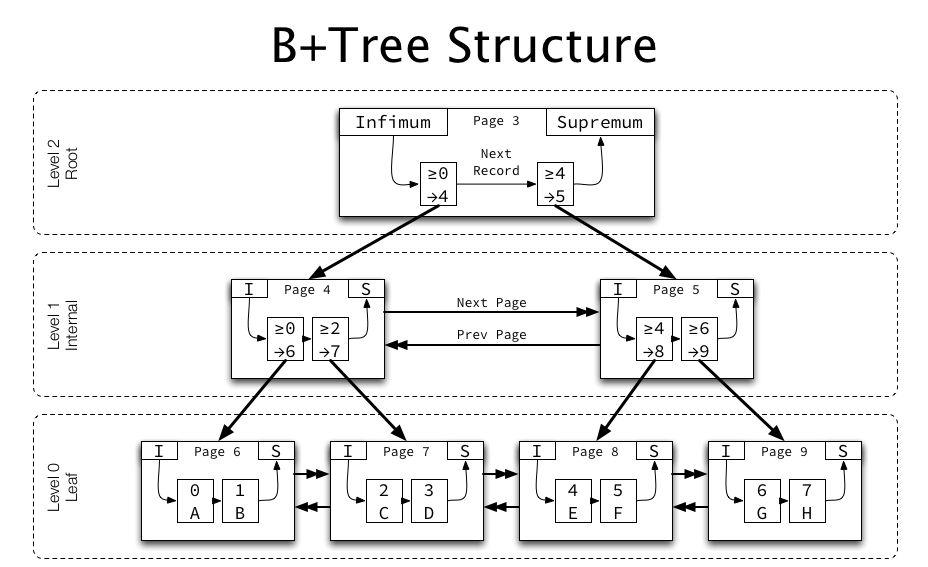
MySQL InnoDB 의 인덱스 페이지는 위 그림과 같이 B+ Tree 로 구성되어 있으며,
실제 데이터 레코드는 리프 노드 인덱스 페이지에서 가리키게 된다.
그림만 봐도 인덱스 페이지 에 넣을 수 있는 키값의 크기가 작을수록 많은 데이터 레코드를 가리킬 수 있다.
키값 16byte, 자식노드 주소 크기가 12byte 일 때 대략 585 개 정도의 노드 포인터를 저장할 수 있다. 레벨이 3만되어도 리프노드 에서 2억(585^3) 의 데이터 레코드를 가리킬 수 있다.
대부분의 대용량 데이터베이스라 하더라도 레벨이 5를 넘지 않는다.
보통 스토리지 엔진이 인덱스 페이지 단위로 디스크에서 데이터를 읽기 때문에 키값 크기가 늘어날 수록 비효율적으로 동작하게된다.
만약 키값이 16byte 에서 32byte 로 늘어나면 리프노드에서 가리키는 데이터 레코드는 5천만개로, 급속도로 줄어들게 된다.
인덱스 페이지 사이즈는 기본 16KB,
@@innodb_page_size글로벌 환경변수로 확인 및 변경 가능.
인덱스 탐색(Index seek), 인덱스 스캔(Index scan)
인덱스를 통해 데이터 레코드를 읽어올 때 아래 2가지 과정을 먼저 거처야한다.
- 인덱스 탐색(Index seel): 조건을 만족하는 인덱스 저장위치 탐색
- 인덱스 스캔(Index scan): 저장위치부터 Range 만큼 스캔
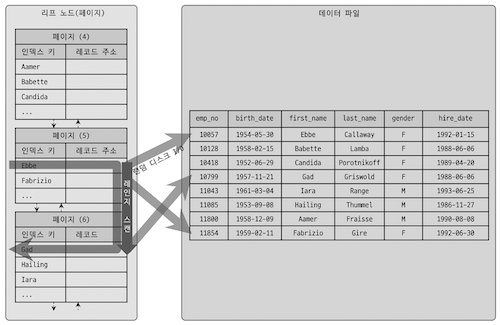
B Tree 인덱스 페이지에서 인덱스르 검색해도 해당 인덱스에는 primary key 만 저장되어 있기에, primary key 를 통해 데이터 레코드를 다시한번 읽기 때문에 레코드 단위로 랜덤 I/O 가 한번씩 발생한다.
SHOW STATUS LIKE 'Handler_%';
/*
+------------------+-----+
|Variable_name |Value|
+------------------+-----+
|Handler_read_key |0 | 인덱스 탐색 횟수
|Handler_read_next |0 | 인덱스 스캔 시작
|Handler_read_prev |0 | 인덱스 스캔 마무리
| .... |... |
+------------------+-----+
*/
인덱스의 파일시스템 기록과정은 대략 아래와 같다.
인덱스 초기화
DB 시작시 기존에 영구 저장소(파일시스템) 에 저장된 인덱스 데이터를 로드, 인메모리 인덱스 구조로 초기화
인덱스 영구 저장소 기록
인메모리 인덱스 데이터를 직렬화하여 주기적으로 또는 특정 이벤트(시스템 종료, 체크포인트 도달)가 발생했을 때 파일 시스템에 기록한다.
장애발생으로 인한 강제 종료시에는 DB 로그를 참고하여 인덱스 데이터의 일관성과 영구성을 보장한다.
MySQL 아키텍처
MySQL 아키텍처는 크게 아래 2가지 엔진으로 구성된다.
- MySQL 엔진
- 스토리지 엔진
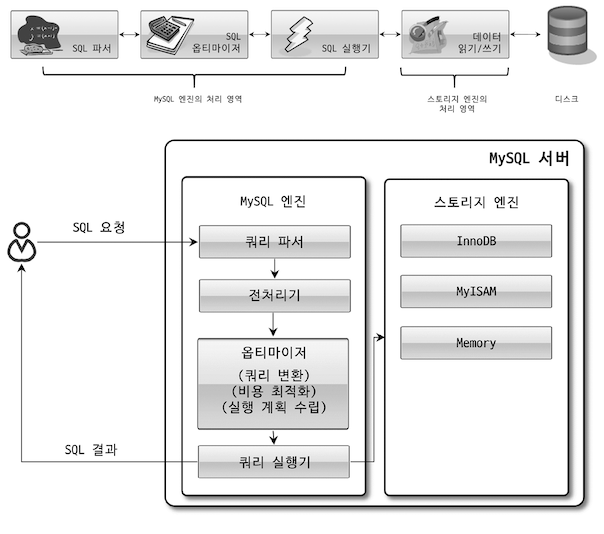
스토리지 엔진
SHOW ENGINES 명령어를 통해 MySQL 에서 제공하는 여러 스토리지 엔진 확인이 가능하다.
> SHOW ENGINES;
/*
+------------------+-------+--------------------------------------------------------------+------------+----+----------+
|Engine |Support|Comment |Transactions|XA |Savepoints|
+------------------+-------+--------------------------------------------------------------+------------+----+----------+
|InnoDB |DEFAULT|Supports transactions, row-level locking, and foreign keys |YES |YES |YES |
|MRG_MYISAM |YES |Collection of identical MyISAM tables |NO |NO |NO |
|MEMORY |YES |Hash based, stored in memory, useful for temporary tables |NO |NO |NO |
|BLACKHOLE |YES |/dev/null storage engine (anything you write to it disappears)|NO |NO |NO |
|MyISAM |YES |MyISAM storage engine |NO |NO |NO |
|CSV |YES |CSV storage engine |NO |NO |NO |
|ARCHIVE |YES |Archive storage engine |NO |NO |NO |
|PERFORMANCE_SCHEMA|YES |Performance Schema |NO |NO |NO |
|FEDERATED |NO |Federated MySQL storage engine |NULL |NULL|NULL |
+------------------+-------+--------------------------------------------------------------+------------+----+----------+
*/
핸들러
실제 데이터의 Read & Write 요청시 MySQL 엔진 과 스토리지 엔진 은 핸들러 API 를 통해 통신한다.
아래 명령을 통해 MySQL 에서 제공하는 핸들러 API 확인이 가능하다.
MySQL 엔진 이 어떤 핸들러 API 를 몇번 사용했는지 알 수 있다.
> SHOW GLOBAL STATUS LIKE 'Handler%';
/*
+--------------------------+--------+
|Variable_name |Value |
+--------------------------+--------+
|Handler_commit |3264334 |
|Handler_delete |28225 |
|Handler_discover |0 |
|Handler_external_lock |4472420 |
|Handler_mrr_init |0 |
|Handler_prepare |0 |
|Handler_read_first |181150 |
|Handler_read_key |2367953 |
|Handler_read_last |0 |
|Handler_read_next |909595 |
|Handler_read_prev |0 |
|Handler_read_rnd |51755 |
|Handler_read_rnd_next |17552719|
|Handler_rollback |97591 |
|Handler_savepoint |0 |
|Handler_savepoint_rollback|0 |
|Handler_update |1021281 |
|Handler_write |12445394|
+--------------------------+--------+
*/
핸들러 API 요청은 핸들러 가 받아 처리하는데, 가장 밑단에서 데이터를 디스크에서 Read & Write 한다.
사실상 핸들러=스토리지 엔진 이라 할 수 있다, 핸들러 API 를 요청받는 스토리지 엔진 종류만 달라질 뿐 MySQL 엔진 에서 바라보는 핸들러 는 변하지 않는다.
핸들러 API 요청을 통해 MySQL 엔진 과 스토리지 엔진 의 역할을 분리한다.
GROUP BY, ORDER BY 등 복잡한 처리는 MySQL 엔진 이 처리하고,
[디스크, 버퍼, 캐시] 등으로부터 데이터를 읽어오는 역할은 스토리지 엔진 이 처리한다.
플러그인
사설 스토리지 엔진 을 플러그인 형태로 빌드하여 MySQL 서버에서 사용 가능하다.
아래 명령을 통해 설치되어 있는 플러그인 확인이 가능하다.
> SHOW PLUGINS;
/*
+--------------------------+--------+------------------+-----------+-----------+
|Name |Status |Type |Library |License |
+--------------------------+--------+------------------+-----------+-----------+
|binlog |ACTIVE |STORAGE ENGINE |NULL |GPL |
|mysql_native_password |ACTIVE |AUTHENTICATION |NULL |GPL |
|sha256_password |ACTIVE |AUTHENTICATION |NULL |GPL |
|CSV |ACTIVE |STORAGE ENGINE |NULL |GPL |
|MEMORY |ACTIVE |STORAGE ENGINE |NULL |GPL |
|InnoDB |ACTIVE |STORAGE ENGINE |NULL |GPL |
|INNODB_TRX |ACTIVE |INFORMATION SCHEMA|NULL |GPL |
|INNODB_LOCKS |ACTIVE |INFORMATION SCHEMA|NULL |GPL |
|INNODB_SYS_VIRTUAL |ACTIVE |INFORMATION SCHEMA|NULL |GPL |
|INNODB_TRX_STATUS |ACTIVE |INFORMATION SCHEMA|NULL |GPL |
|MyISAM |ACTIVE |STORAGE ENGINE |NULL |GPL |
...
|partition |ACTIVE |STORAGE ENGINE |NULL |GPL |
|ngram |ACTIVE |FTPARSER |NULL |GPL |
+--------------------------+--------+------------------+-----------+-----------+
*/
공식 문서에 공개된 플러그인 API 를 통해 새로운 기능을 수행하는 플러그인 개발이 가능하다.
InnoDB
B+Tree Page 기본 16KB 노드 구조를 사용하여 데이터를 저장하는 MySQL의 기본 스토리지 엔진.
B+Tree Internal Page- 데이터를 찾아가기 위한 인덱스용 노드B+Tree Leaf Page- 실제 데이터가 저장되어있는 노드
인덱스 크기가 작을경우 노드를 하나의 Page 단위(16KB)로 맞춰 B+Tree Internal Page 를 구성한다.
레코드가 저장된 B+Tree Leaf Page 는 사이즈가커서 노드에 여러개의 Page 단위로 저장될 수 있다.
InnoDB 아키텍처
MySQL 에서 가장 많이 사용되는 스토리지 엔진 구조는 아래 그림과 같다.
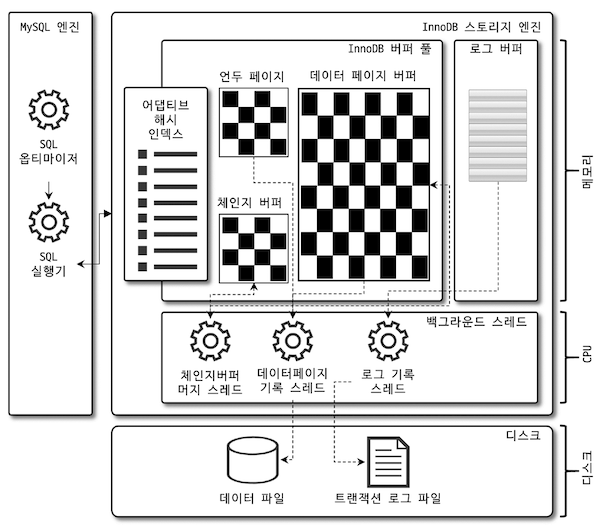
InnoDB 에서 제공하는 동기화 시스템 덕에 MySQL 서버 시작, 종료시 미완 트랜잭션이나 Partial write 와 같은 복구는 자동으로 수행된다.
디스크 손상같은 하드웨어 이슈가 일어나지 않는 경우 대부분 오류는 자동 복구된다.
InnoDB 버퍼 풀
일종의 캐시(버퍼)공간, 디스크에 Write 할 데이터, 인덱스 정보를 모아 일괄 작업으로 처리하면서 랜덤한 디스크 작업 발생 횟수를 줄인다.
일반적으로 물리메모리 50% 정도를 InnoDB 버퍼 풀 크기(innodb_buffer_pool_size) 로 사용하면서 상황을 보며 점점 늘려가는 것을 추천한다, 64G 이상이라면 처음부터 40G 좀 넘게 설정하는 것도 좋다.
InnoDB 버퍼 풀 사이즈 변경은 시스템에 많은 부하를 일으킴으로 운영외 시간에 변경하는 것을 권장한다.
InnoDB 버퍼 풀 은 풀 전체를 관리하는 잠금(세마포어)을 통해 Concurreny Control 하는데 InnoDB 버퍼 풀 인스턴스 개념으로 풀을 여러개로 쪼개어 잠금 경합을 줄일 수 있다.
InnoDB 커넥션 수
커넥션 개수는 기본값 151.
SHOW VARIABLES LIKE 'max_connections'; -- 151
SET GLOBAL max_connections = 500;
수평 확장된 어플리케이션에서 사용하기엔 적어 500-1000개 까지 늘려 사용하는 경우가 많다.
물론 부하 테스트 및 실제 운영하며 모니터링을 통해 실제 동시 DB 요청 수를 확인 후 조정해야한다.
OS, DB, innodb_buffer_pool_size(10GB) 정도를 할당하면 대략 13GB 정도를 사용하게된다.
커넥션당 5MB 고부하 쿼리를 호출할 경우 500개 커넥션 설정시 2.5GB 를 사용하게 됨으로 운영 가능하다.
물론 5MB 보다 훨씬 작은 커넥션이 더 많이 호출됨.
MySQL 엔진 요소
쿼리파서
요청 쿼리를 토큰으로 분리하고 트리형태 구조로 변경, 쿼리를 파싱하는 과정에서 문법을 검증하고 오류를 반환한다.
전처리기
쿼리파서가 생성한 트리형태 쿼리문장에 구조적인 문제점 확인, [테이블, 속성명, 함수명] 등의 존재여부와 접근권한 등을 확인하는 과정을 수행한다.
옵티마이저
쿼리문장을 빠르게 처리할 수 있도록 실행순서를 최적화한다, 사실상 DBMS 의 두뇌 역할.
실행엔진(쿼리실행기)
핸들러API(스토리지 엔진)으로부터 받은 결과를 조작하거나, 반은 결과를 다시 다른 핸들러API 로 만들어 추가적인 작업을 하도록 연결하는 역할.
메모리 구조
[글로벌 메모리 영역, 로컬 메모리 영역] 2가지 영역으로 분류되며 대표적으로 관리하는 메모리는 아래 그림과 같다.
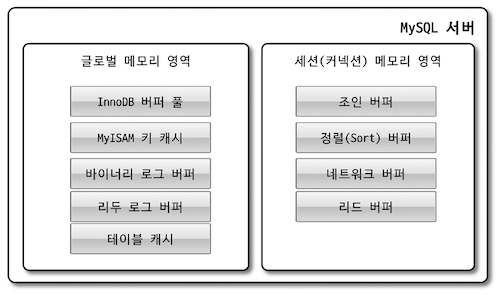
로컬 메모리 영역 은 사용자 스레드 가 쿼리를 처리하는데 사용되며 사용자 스레드별 로 독립적으로 할당되고 공유되지 않는다.
이런 이유로 [세션 메모리 영역, 클라이언트 메모리 영역, 커넥션 메모리 영역] 이라고도 한다.
글로벌 메모리 영역은 모든 사용자 스레드에게 공유되며
MySQL 스레드 구조
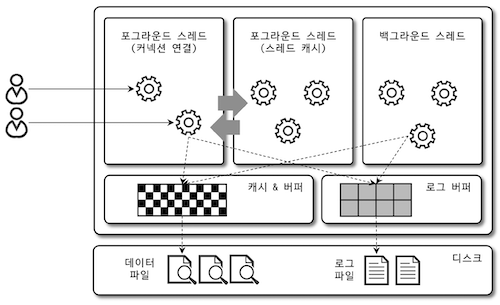
- 백그라운드 스레드
- 포그라운드 스레드
포그라운드 스레드 는 평상시 스레드 캐시 에 존재하다 사용자의 요청이 들어오면 처리하도록 지원한다.
포그라운드 스레드를사용자 스레드라 부르기도 한다.
thread_cache_size 시스템 변수를 통해 스레드 캐시 에 존재하는 포그라운드 스레드 개수를 조절한다.
그림처럼 포그라운드 스레드 [캐시, 버퍼, 로그버퍼] 의 Read & Write 를 수행한다.
디스크의 Read & Write 는 백그라운드 스레드 가 수행한다.
아래와 같은 여러 작업이 백그라운드 스레드 로부터 수행된다.
- Insert Buffer 를 병합하는 스레드
- Log 를 디스크로 기록하는 스레드
- InnoDB 버퍼 풀의 데이터를 디스크에 기록하는 스레드
- 데이터를 버퍼로 읽어 오는 스레드
- 잠금이나 데드락을 모니터링하는 스레드
백그라운드 스레드 가 뒤에서 처리해주는 작업으로 인해 InnoDB 에서는 INSERT, UPDATE, DELETE 쿼리로 디스크 데이터가 완전히 저장 될 때까지 기다리지 않아도 된다.
아래 명령을 통해 실행중인 스레드 종류와 타입 확인 가능.
> SELECT thread_id, name, type
FROM performance_schema.threads;
/*
+---------+-------------------------------------------+----------+
|thread_id|name |type |
+---------+-------------------------------------------+----------+
|1 |thread/sql/main |BACKGROUND|
|3 |thread/innodb/io_ibuf_thread |BACKGROUND|
|4 |thread/innodb/io_read_thread |BACKGROUND|
...
|43 |thread/sql/signal_handler |BACKGROUND|
|44 |thread/mysqlx/acceptor_network |BACKGROUND|
|45 |thread/sql/compress_gtid_table |FOREGROUND|
|50 |thread/sql/one_connection |FOREGROUND|
+---------+-------------------------------------------+----------+
*/
대부분 스레드 풀 목적은 CPU 에 최적화된 스레드 수를 사용하여 문맥교환 수를 줄이고 오버헤드를 낮춰 성능을 증가시키기 위함이다.
하지만 CPU 성능대비 많은 요청이 들어오면 요청을 처리하기 위한 스레드 개수를 늘려야 하고 전통적인 스레드 모델보다 비슷한 대기시간을 같게 된다.
위에서 설명한 [백그라운드, 포그라운드] 스레드 구조는 커넥션별로 스레드가 생성되는 전통적인 스레드 모델이다.
스레드 풀 을 사용하여 하나의 스레드가 여러개의 커넥션을 처리할 수 있다.
151은 너무 작지도, 너무 크지도 않은 값으로, 다양한 워크로드(웹 앱, 소규모 DB 등)에서 기본값으로 동작하도록 설계.
SHOW VARIABLES LIKE 'max_connections';
SELECT @@max_connections;
-- max_connections의 기본값은 151
max_connections의 최대값을 내부적으로 약 100,000까지 설정할 수 있지만 병목현상, 리눅스의 파일시스템 성능상 1000개 이상은 설정하지 않는다.
MySQL 모드
MySQL 서버의 sql_mode 시스템 변수에 설정된 값으로 아래와 같은 설정에 관여한다.
- SQL 문장 작성 규칙
- 데이터 타입 변환
- 기본값 제어
MySQL 기본 sql_mode 는 아래와 같다.
SELECT @@sql_mode;
-- ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
ONLY_FULL_GROUP_BY
SQL 문법에 조금 더 엄격한 규칙을 적용. GROUP BY 절에 포함되지 않은 칼럼은 집합함수에 사용할 수 없음.
STRICT_TRANS_TABLES
INSERT, UPDATE 문장으로 데이터를 변경하는 경우 칼럼의 타입과 저장되는 값의 타입이 다를 때 자동으로 타입 변경을 수행한다.
NO_ZERO_IN_DATE, NO_ZERO_DATE
DATE, DATETIME 타입의 칼럼에 2020-00-00 같은 잘못된 날짜를 저장하는 것이 불가능해진다.
클러스터링 인덱스
InnoDB 스토리지 엔진 에서 제공하는 클러스터링 인덱스 는 primary key 기준으로 비슷한 레코드를 묶어서 저장하는 방법,
인덱스에 의한 저장 방법이기 때문에 클러스터링 테이블 방법이라 부르기도 한다.
클러스터링 인덱스 를 사용하면 primary key 에 의해 데이터 레코드의 물리적 저장위치가 결정되어 [DELETE, INSERT, UPDATE] 에선 느리지만,
대부분 웹서비스의 읽기/쓰기 비율이 1:9 ~ 2:8 정도이기에 사용하는것을 권장한다.
InnoDB 스토리지 엔진 에서 기본 사용되며 이런 특성으로 인해 인덱스를 생성하면, 해당 생성한 인덱스가 바로 데이터 레코드 주소를 가리키는것이 아닌 primary key 를 가리킨다.
primary key, 인덱스 모두 없는 테이블의 경우에도 클러스터링 인덱스 사용을 위해 내부적으로 레코드의 일련번호 칼럼을 생성한다.
primary key 를 거쳐가는 과정에서 인덱스 탐색 과 인덱스 스캔 이 한번씩 더 일어나기 때문에 비효율적이라 생각할 수 있지만 primary key 를 기준으로 검색하는 경우에는 빠른 성능을 보장한다.
이런 특성 때문에 클러스터링 될 수 있는 유의미한 값으로 primary key 를 직접 지정하는 것을 권장하고, 필요하다면 복합 인덱스로 primary key 를 사용하는 것도 좋다.
MySQL 지원 인덱스
멀티밸류 인덱스
JSON 타입 칼럽에 사용하는 인덱스
배열이나 객체에 대해 인덱스 설정이 가능하다.
CREATE TABLE tbl_json_user
(
user_id BIGINT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(10),
last_name VARCHAR(10),
credit_info JSON,
INDEX mx_creditscores ((CAST(credit_info -> '$.credit_scores' AS UNSIGNED ARRAY))
) );
INSERT INTO tbl_json_user VALUES (1, 'Matt', 'Lee', '{"credit_scores":[360, 353, 351]}');
SELECT * FROM tbl_json_user WHERE 360 MEMBER OF(credit_info->'$.credit_scores');
트랜잭션, autocommit
MySQL 의 경우 autocommit 의 기본값은 1이다. 세션을 열고 적용하는 모든 쿼리는 즉각 적용된다.
해당 상태에선 롤백을 수행해도 수행결과가 취소되지 않는다.
SELECT @@autocommit; -- 1
SET autocommit=1;
INSERT INTO tbl_author (birth, name) VALUES ('1980-05-15', 'John Doe');
ROLLBACK; -- 롤백해도 INSERT 가 취소되지 않음
autocommit=0 인 상태에선 롤백을 수행하면 수행결과가 취소되며, 적용시키고 싶을땐 커밋 명령을 따로 호출해야한다.
SET autocommit=0;
INSERT INTO tbl_author (birth, name) VALUES ('1980-05-15', 'John Doe');
ROLLBACK; -- 롤백시 INSERT 가 취소됨
-- COMMIT;
트랜잭션을 명시하면 autocommit=1 상태여도 바로 적용되지 않고 autocommit=0 처럼 동작한다.
트랜잭션이 완료되면 기존 세션의 autocommit 상태로 돌아간다.
SET autocommit=1;
START TRANSACTION;
SET autocommit=1;
INSERT INTO tbl_author (birth, name)
VALUES ('1980-05-15', 'John Doe');
ROLLBACK; -- autocommit 상태와 상관없이 INSERT 가 취소됨
-- COMMIT;
START TRANSACTION 은 명시적인 autocommit=0 이라 볼 수 있다.
대부분 롤백이 필요할 경우 autocommit=0 대신 START TRANSACTION 을 사용한다.