NoSQL MongoDB!
MongoDB
https://github.com/mongodb/mongo https://github.com/neelabalan/mongodb-sample-dataset 위 샘플데이터 설치 후 gui 툴에서 import 설정
대표적인 NoSQL 인 MongoDB 에서 클러스터를 어떻게 처리하는지 개념적 요소에 대해 알아본다.
services:
mongodb:
image: mongo:6.0
container_name: mongodb_container
restart: always
environment:
MONGO_INITDB_ROOT_USERNAME: admin
MONGO_INITDB_ROOT_PASSWORD: password
MONGO_INITDB_DATABASE: testdb
ports:
- "27017:27017"
volumes:
- ./mongodb_data:/data/db
B-Tree기반의WiredTiger스토리지 엔진을 사용BSON(Binary JSON)- 도큐먼트를 저장하며 아래와 같이 드라이버가 변환을 담당한다.
클라이언트--json--(드라이버)--bson--서버- 경량 바이너리 형식으로 압축된 바이트 문자열을 빠르게 인코딩하고 디코딩하도록 설계되었다.
- 비동기 I/O 기반 연결
- NonBlocking 기반 소켓 통신
- MongoDB 의 경우 연결 가능한 커넥션 개수 기본값은 65536개이다(maxIncomingConnections).
MongoDB 의 구조는 크기순으로 아래와 같다.
- Column(Field)
- RDBMS의 컬럼과 유사
- 다양한 데이터 타입을 지원 (String, Number, Date, Array, Object, Binary, etc)
- 중첩된 구조(객체, 배열) 지원
- Document
- RDBMS의 레코드와 유사
- 16MB 크기까지 가능
- BSON(Binary JSON, 압축 JSON) 형식으로 저장
- Collection
- RDBMS의 테이블과 유사
- 스키마가 없는 구조, Collection 내부 Document 구조가 달라도 무바함
- Database
- Collection 들의 컨테이너
- 한 서버에 여러 Database 가 존재가능
간단한 CRUD 명령어
db.collection.insertOne({ name: "Alice", age: 25 });
db.collection.insertMany([
{ name: "Bob", age: 30 },
{ name: "Charlie", age: 35 }
], { ordered: true });
// ordered: true(default) 도중 실패시 이후 insert 는 실행되지 않음,
// ordered: false 지정시 실패해도 모든 insert 진행
db.collection.find({ name: "Alice" }); // 조건에 맞는 모든 도큐먼트를 조회
db.collection.find({ age: { $gt: 20 } }); // age가 20보다 큰 도큐먼트 조회
db.collection.findOne({ name: "Alice" }); // 조건에 맞는 첫 번째 도큐먼트만 검색
db.collection.countDocuments({ age: { $gte: 30 } }); // 조건에 맞는 도큐먼트 개수 반환
db.collection.updateOne(
{ name: "Alice" }, // 조건
{ $set: { age: 26 } } // 수정 내용
); // 조건에 맞는 첫 번째 도큐먼트 수정.
db.collection.updateMany(
{ age: { $lt: 30 } }, // 조건
{ $set: { status: "young" } } // 수정 내용
); // 조건에 맞는 모든 도큐먼트 수정
db.collection.replaceOne(
{ name: "Alice" }, // 조건
{ name: "Alice", age: 28, city: "New York" } // 새 데이터
); // 조건에 맞는 첫 번째 도큐먼트 교체.
db.collection.deleteOne({ name: "Alice" }); // 조건에 맞는 첫 번째 도큐먼트 삭제
db.collection.deleteMany({ status: "inactive" }); // 조건에 맞는 모든 도큐먼트 삭제
고유 ID 로 ObjectId 를 사용하고 인덱스 처리됨
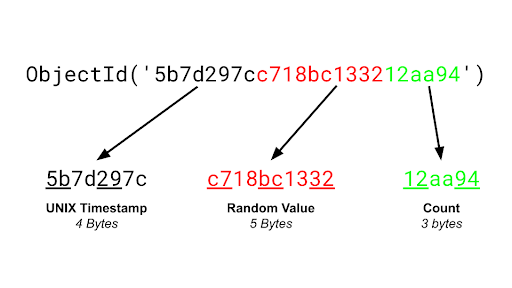
- 머신 고유 프로세스당 생성되는 랜덤 5바이트 값
- 생성기마다 랜덤하게 설정됨
- 프로세스마다 초기화되는 3바이트 카운터
- 생성기는 MongoDB 서버, 클라이언트 모두 사용 가능
- 타임 동기화만 잘 설정하면 클라이언트에서도 중복없느 ObjectId 를 생성 가능
ObjectId를 직접 만들게되면 서버 작업량을 줄이고 배치처리를 통해 네트워크 효율성이 좋아짐.- 대규모 처리작업이 아니고는 대부분의 상황에서 MongoDB 서버에 ObjectId 생성을 위임하는 것을 권장.
인덱스
MongoDB 인덱스 종류
- Single Field Index
- 단일 필드 인덱스, Document 를 빠르게 검색 및 정렬 가능
- Compound Index
- 두개 이상 필드 인덱스
- Multikey Index
- 배열 타입 필드에 인덱스 생성, 요소 개수에 따라 여러 인덱스 항목이 생설됨.
- Unique Index
- 필드값이 중복되지 않도록 강제
- TTL Index
- Time to Live 인덱스, 자동 삭제에 사용됨.
- Hashed Index
- 필드의 해시결과를 사용하여 인덱스 생성, 샤딩에 주로 사용됨.
- Text Index
- 문자열 필드를 인덱싱하여 Full-Text Search 지원, 텍스트 검색 API 구성시 사용.
- Compound Text Index
Text Index와 다른 필드의 인덱스를 결합, 텍스트 검색과 다른 조건을 같이 쿼리할 때 사용됨.
- Partial Index
- 특정 조건을 만족하는 Document 에만 인덱스 생성
- GeoSpatial Index
- 지리공간 데이터(위/경도)에 대한 Geo 쿼리를 지원하는 인덱스 생성.
쿼리플랜
인덱스를 사용하지않으면 컬렉션 스캔(collection scan) 이 발생한다.
인덱스를 사용한 쿼리가 들어오면 쿼리 모양(query shape) 확인하고 매핑된 쿼리 플랜(query plan) 을 사용하여 조회한다.
쿼리 플랜을 결정하기 위해 아래 과정을 거친다.
- 인덱스 5개 중 3개가 쿼리 후보로 식별됨.
- 각 인덱스 후보에 하나씩 총 3개
쿼리 플랜작성 - 각각 인덱스를 사용하는 3개의 병렬 스레드에서
쿼리 플랜실행 - 각 플랜은
시범기간(trial period)동안 경쟁, 승리한 쿼리 플랜을 산출 - 쿼리 모양과 쿼리 플랜을 매핑
- 쿼리 플랜은 캐시에 저장되고 서버가 재시작되거나 컬렉션/인덱스가 변경되면 캐시에서 삭제된다.
{
"_id": ObjectId("585d817db4743f74e2da067c"),
"student_id": 0,
"scores": [...],
"class_id": 127 // 0~500
}
위와 같은 문서가 10만개 존재할 때 아래 2개 인덱스를 생성
# 1: 오름차순, -1: 내림차순
db.students.createIndex({"class_id": 1})
db.students.createIndex({student_id: 1, class_id: 1})
그리고 아래와 같은 조회조건, 정렬조건을 설정해서 조회한다.
> db.students.find({student_id:{$gt:5000}, class_id:54})
.sort({student_id:1})
.explain("executionStats")
당연히 class_id 인덱스를 사용해 조회 후 인메모리에서 student_id 를 정렬하는게 효율적이지만 실제 그렇게 동작하지 않을 수 있다.
find 에 요청한 필드 목록만 봐도 {student_id: 1, class_id: 1} 인덱스를 사용해야 할것 같다.
실제 통계정보가 부족한 경우 해당 인덱스를 사용하여 10만건 가까운 데이터를 읽어야할 수 있다.
트랜잭션
갱신은 전체 도큐먼트를 다시 쓰며, 원자성 갱신은 도큐먼트 단위로 실행된다.
원자성이 필요하다면 한 도큐먼트 안에 여러 엔티티를 관리하면 좋다.
하지만 도큐먼트가 커질수록 쓰기성능이 떨어짐으로 원자성이 필요하다고 무작정 크기를 늘릴 순 없다.
Oplog를 사용하는Replica Set,Sharded Cluster에서만 트랜잭션이 가능하다.- 트랜잭션을 사용하려면 단일노드도
Replica Set으로 구성해야 트랜잭션을 지원한다. - WAL(Write-Ahead Logging) 메커니즘을 사용하여 롤백을 처리한다.
- 트랜잭션은 스냅샷 격리레벨(MVCC) 처럼 동작하여 다른 세션에선 해당 트랜잭션은로 인해 변경된 데이터에 접근할 수 없다.
- 트랜잭션 중 발생한 모든 변경 사항을 먼저 로그에 기록한다.
- 트랜잭션 중 에러가 발생하면 해당 로그를 참조하여 발생한 변경 사항을 취소한다.
- 트랜잭션이 정상종료되면 변경 내용을 데이터베이스에 반영한다.
- 트랜잭션을 사용하려면 단일노드도
- 트랜잭션 실행 시간은 default 60초.
- 모든 클러스터 노드는 완료되지 않은 트랜잭션을 주기적으로 중단하고 정리한다. 주기는 트랜잭션 실행시간보다 짧음
- WAL은 다음과 같은 정보를 담고 있다.
- 트랜잭션 ID (Transaction ID)
- 타임스탬프
- 변경된 데이터 (Modified Records) 어떤 문서의 어떤 필드가 변경되었는지 기록됩니다. 필드와 그에 대한 변경 값이 포함됩니다.
- 데이터의 이전 버전 (Previous Version) MVCC를 위해 이전 버전의 데이터를 함께 기록합니다.
- 트랜잭션 상태 (Transaction State) Prepare 상태인지, Commit인지, Abort 상태인지 기록됩니다.
싱글노드 Replica Set 구성
Oplog 를 사용하는 싱글노드 Replica Set 으로 구성하기 위해 keyfile 생성 및 docker volume 지정.
# keyfile 생성
openssl rand -base64 756 > mongodb-keyfile
docker compose up -d
services:
mongodb:
image: mongo:6.0
container_name: demo-mongo
restart: always
logging: *custom-fluentbit-log # 앵커를 참조
environment:
MONGO_INITDB_ROOT_USERNAME: ${MONGO_INITDB_ROOT_USERNAME}
MONGO_INITDB_ROOT_PASSWORD: ${MONGO_INITDB_ROOT_PASSWORD}
MONGO_INITDB_DATABASE: ${MONGO_INITDB_DATABASE}
ports:
- "27017:27017"
volumes:
- ./etc/mongo/mongodb-keyfile:/data/keyfile:ro # keyFile 추가
- ./volume/mongodb_data:/data/db
command: mongod --replSet rs0 --bind_ip_all --keyFile /data/keyfile
init-mongo:
image: mongo:6.0
container_name: init-mongo
environment:
MONGO_INITDB_ROOT_USERNAME: ${MONGO_INITDB_ROOT_USERNAME}
MONGO_INITDB_ROOT_PASSWORD: ${MONGO_INITDB_ROOT_PASSWORD}
MONGO_INITDB_DATABASE: ${MONGO_INITDB_DATABASE}
MONGODB_HOST: ${MONGODB_HOST}
MONGODB_USERNAME: ${MONGODB_USERNAME}
MONGODB_PASSWORD: ${MONGODB_PASSWORD}
MONGODB_DATABASE: ${MONGODB_DATABASE}
volumes:
- ./etc/mongo/mongodb-keyfile:/data/keyfile # keyFile 추가
- ./etc/mongo/init-mongo.js:/init/init-mongo.js
entrypoint: >
/bin/bash -c "
chmod 400 /data/keyfile;
chown 999:999 /data/keyfile;
sleep 10;
mongosh --host mongodb:27017 -u ${MONGO_INITDB_ROOT_USERNAME} -p ${MONGO_INITDB_ROOT_PASSWORD} /init/init-mongo.js ${MONGODB_HOST} ${MONGODB_USERNAME} ${MONGODB_PASSWORD} ${MONGODB_DATABASE};
exit 0;"
depends_on:
- mongodb
// init-mongo.js
const hostname = process.argv[9];
const username = process.argv[10];
const password = process.argv[11];
const database = process.argv[12];
// Replica Set 초기화
rs.initiate({
_id: "rs0",
members: [
{ _id: 0, host: `${hostname}:27017` } // 필요에 따라 호스트 및 포트를 수정하세요. 외부에서 바라볼 수 있는 url 이어야 함.
]
});
// Primary 노드 선출 및 write 가능 여부 대기
function waitForWritablePrimary() {
while (true) {
let status = rs.status();
// primary node (1) status 인지 확인 및 writeable 가능한지 확인
if (status.myState === 1 && db.runCommand({ hello: 1 }).isWritablePrimary) {
print("Replica Set initialized and Primary node is writable. Proceeding...");
break;
} else {
print("Waiting for Primary to be writable...");
sleep(1000); // 1초 대기
}
}
}
waitForWritablePrimary();
// `testdb` 데이터베이스 선택
print("Start creating the database...");
db = db.getSiblingDB(database);
// 사용자 생성
db.createUser({
user: username,
pwd: password,
roles: [
{ role: "readWrite", db: database } // db에 readWrite 권한 부여
]
});
print("User 'testuser' created successfully.");
// 초기 데이터 삽입 (옵션)
db.testCollection.insertOne({
message: "Replica Set initialized successfully!"
});
print("Initial document inserted into 'testCollection'.");
트랜잭션과 매핑될 논리세션 시작을 명시하여 트랜잭션을 시작한다.
RDB 의 start_transaction, commit_transaction 형태와 유사하다.
// 세션 시작
try (ClientSession session = mongoClient.startSession()) {
// 트랜잭션 본문 정의
TransactionBody<String> txnBody = () -> {
// 첫 번째 컬렉션에 문서 삽입
InsertOneResult result1 = collection1.insertOne(session, new Document("name", "Alice").append("age", 25));
System.out.println("Inserted document ID in collection1: " + result1.getInsertedId());
// 두 번째 컬렉션에 문서 삽입
InsertOneResult result2 = collection2.insertOne(session, new Document("name", "Bob").append("age", 30));
System.out.println("Inserted document ID in collection2: " + result2.getInsertedId());
return "Transaction successfully completed!";
};
// 트랜잭션 실행
try {
String result = session.withTransaction(txnBody);
System.out.println(result);
} catch (RuntimeException e) {
System.out.println("Transaction aborted due to an error: " + e.getMessage());
}
}
스키마 설계
다형성 패턴(Polymorphic)
모든 도큐먼트가 유사하지만 동일하지 않은 구조를 가질 때 적합
애플리케이션에서 실행가능한 공통 필드를 식별하는 것이 포함
아래와 같은 notifications 컬렉션에서 다양한 형태의 도큐먼트가 저장가능함.
type, user_id 필드만 고정이고 나머지 필드는 달라질 수 있음.
// 메시지 알림
{
"_id": ObjectId("60d5dbf87f3e6e3b2f4b2b3a"),
"type": "message",
"user_id": 1,
"message": "You have a new message from Alice",
"timestamp": "2023-08-01T10:00:00Z",
"sender_id": 2
}
// 친구 요청 알림
{
"_id": ObjectId("60d5dbf87f3e6e3b2f4b2b3b"),
"type": "friend_request",
"user_id": 1,
"message": "Bob sent you a friend request",
"timestamp": "2023-08-01T10:05:00Z",
"requester_id": 3
}
// 이벤트 초대 알림
{
"_id": ObjectId("60d5dbf87f3e6e3b2f4b2b3c"),
"type": "event_invite",
"user_id": 1,
"message": "You are invited to Sarah's birthday party",
"timestamp": "2023-08-01T10:10:00Z",
"event_id": 5,
"location": "123 Main St"
}
상속구조를 흉내낼 수 있다.
모든 문서가 공통으로 가지는 필드는 부모 클래스에 해당하고, 각 유형별로 고유한 필드는 자식 클래스에 해당한다.
{
"_id": "3",
"type": "media",
"mediaType": "book", // 상위 클래스 필드
"title": "1984",
"author": "George Orwell",
"pages": 328
}
속성 패턴
도큐먼트에 필드의 서브셋이 있는 경우
정렬, 쿼리할 필드가 서브셋에 있는 경우
{
"product_id": 123,
"name": "Smartphone",
"brand": "TechCorp",
"attributes": [
{ "key": "color", "value": "Black" },
{ "key": "storage", "value": "128GB" },
{ "key": "camera", "value": "12MP" }
]
}
db.products.createIndex({ "attributes.key": 1, "attributes.value": 1 });
새로운 속성이 추가되거나 기존 속성이 변경될 때에도 스키마를 변경하지 않고 쉽게 확장할 수 있다.
배열 요소가 추가될때마다 index 도 하나씩 늘어나기 때문에 인덱스 크기와 성능이 영향을 끼친다.
아래와 같이 key: color 인 속성에 대해서만 인덱스 생성처리를 할 수 있다.
db.products.createIndex(
{ "attributes.value": 1 },
{ partialFilterExpression: { "attributes.key": "color" } }
);
버킷 패턴
https://mongo.comcloud.xyz/ko-kr/docs/v6.0/tutorial/model-iot-data/
일정 기간 동안 스트림으로 유입되는 시계열 데이터에 적합한 패턴.
예로 센서가 초당 1개의 데이터를 생성한다고 가정할 때 한시간 동안의 데이터를 단일 도큐먼트 내 배열에 배치한다.
// 버킷 패턴 적용: 한시간 데이터를 하나의 문서로 묶어서 저장
{
"date": "2024-08-12",
"sensorId": "sensor1",
"readings": [
{"time": "10:00:00", "value": 23.5},
{"time": "10:01:00", "value": 23.8},
{"time": "10:02:00", "value": 24.1},
// ...한시간치 데이터
]
}
redis 나 메세지 큐를 저장공간 삼아서 버킷으로 저장하기 좋다.
MongoDB 5.0 부터 time-series 데이터구조를 제공함으로 고정된 데이터 형식 저장용도라면 버킷패턴보다 time-series 사용을 권장한다.
서브셋 패턴
단일 도큐먼트가 너무 커지거나 배열이 너무 길어져서 성능에 영향을 미칠 수 있을 때, 일부만을 저장하고 나머지 데이터를 다른 컬렉션에 분리해 저장하는 방법.
최근 댓글 몇 개만 comments 배열에 저장하고, 나머지 댓글은 별도의 컬렉션으로 분리.
// 서브셋 패턴 적용: 최근 댓글만 저장
{
"_id": "user123",
"username": "john_doe",
"recentComments": [
{"commentId": "cmt998", "text": "Recent comment!", "timestamp": "2024-08-01"},
{"commentId": "cmt999", "text": "Another recent comment!", "timestamp": "2024-08-02"}
],
"commentsSubset": true // 추가 댓글이 별도로 존재함을 나타냄
}
// 나머지 댓글을 저장하는 별도 컬렉션
{
"_id": "cmt_batch_1",
"userId": "user123",
"comments": [
{"commentId": "cmt1", "text": "First comment!", "timestamp": "2024-01-01"},
{"commentId": "cmt2", "text": "Another comment!", "timestamp": "2024-01-02"},
// ...
]
}
확장된 참조 패턴(Extended Reference)
역정규화를 통해 자주 사용하는 연관 데이터의 중요한 필드를 중복하여 저장함으로써, 한번의 요청으로 데이터를 가져올 수 있도록 하는 패턴.
// 확장된 참조 패턴 적용
{
"_id": "post123",
"title": "My First Blog Post",
"content": "This is the content...",
"authorId": "user456",
"authorName": "John Doe", // 작성자 이름
"authorEmail": "john.doe@example.com" // 작성자 이메일
}
데이터 중복이 발생하고 데이터 일관성 관리가 힘들어진다.
부가적으로 여러 조건을 걸어 데이터 일관성 문제를 처리할 수 있다.
델타 패턴
확장된 참조 패턴과 같이 데이터 변경으로 인한 일관성을 해결하기 위한 패턴.
async function updateNickname(userId, newNickname) {
// 먼저 사용자의 현재 데이터를 가져옵니다.
const user = await User.findById(userId);
if (!user) {
throw new Error('User not found');
}
// 닉네임이 변경되었는지 확인
if (user.nickname !== newNickname) {
// 델타 패턴으로 변경 사항 기록
user.deltas.push({
field: 'nickname',
oldValue: user.nickname,
newValue: newNickname
});
// 닉네임 업데이트
user.nickname = newNickname;
// 변경 사항을 저장
await user.save();
console.log(`Nickname updated to ${newNickname} with delta recorded.`);
} else {
console.log('Nickname is the same, no update needed.');
}
}
결국 참조하는 도큐먼트에 접근해야 함으로 쿼리개수를 줄이지 못하지만 아래와 같은 장점이 있다.
- 실시간으로 데이터 변경을 확인해야 하는 경우
- 지연 업데이트를 지원하기에 한번에 업데이트 빈도가 분산된다
- 부분 조인 기능이 부가적으로 딸려온다
실시간성이 덜 필요한 UI/UX 의 경우에는 업데이트 관련 코드를 제거하고 기존 확장된 참조 패턴 으로 계속 사용하면 된다.
캐시와 같은 시스템을 사용하면 DB 가 조회역할을 수행하지 않아도 된다.
트리 패턴
https://mongo.comcloud.xyz/ko-kr/docs/v6.0/tutorial/model-tree-structures-with-parent-references/
Books > Programming > Databases > MongoDB
Books > Programming > Databases > MySQL
Books > Programming > Databases > dbm
Books > Programming > Languages > Java
위와같이 구조적으로 주로 계층적인 데이터가 있을 때 적용
상위 참조 형태로 데이터 구성
db.categories.insertMany( [
{ _id: "MongoDB", parent: "Databases" },
{ _id: "dbm", parent: "Databases" },
{ _id: "Databases", parent: "Programming" },
{ _id: "Languages", parent: "Programming" },
{ _id: "Programming", parent: "Books" },
{ _id: "Books", parent: null }
] )
db.categories.createIndex( { parent: 1 } )
// 직계 하위 노드를 찾기
db.categories.find( { parent: "Databases" } )
하위 참조 형태로 데이터 구성
db.categories.insertMany( [
{ _id: "MongoDB", children: [] },
{ _id: "dbm", children: [] },
{ _id: "Databases", children: [ "MongoDB", "dbm" ] },
{ _id: "Languages", children: [] },
{ _id: "Programming", children: [ "Databases", "Languages" ] },
{ _id: "Books", children: [ "Programming" ] }
] )
db.categories.findOne( { _id: "Databases" } ).children
db.categories.createIndex( { children: 1 } )
// 직계 상위 노드를 찾기
db.categories.find( { children: "MongoDB" } )
구체화된 경로 형태로 데이터 구성
db.categories.insertMany( [
{ _id: "Books", path: null },
{ _id: "Programming", path: ",Books," },
{ _id: "Databases", path: ",Books,Programming," },
{ _id: "Languages", path: ",Books,Programming," },
{ _id: "MongoDB", path: ",Books,Programming,Databases," },
{ _id: "dbm", path: ",Books,Programming,Databases," }
] )
db.categories.createIndex( { path: 1 } )
// 정규식 사용 하위항목들 검색
db.categories.find( { path: /,Programming,/ } )
db.categories.find( { path: /^,Books,/ } )
$graphLookup
스키마 버전 관리 패턴(Schema Versioning)
https://mongo.comcloud.xyz/ko-kr/docs/v6.0/tutorial/model-data-for-schema-versioning/
동일 컬랙션에서 다양한 형태로 데이터를 운영하고, 점진적으로 스키마를 업데이트할 수 있다.
{
"_id": "<ObjectId>",
"galactic_id": 123,
"name": "Anakin Skywalker",
"phone": "503-555-0000",
}
{
"_id": "<ObjectId>",
"galactic_id": 123,
"name": "Darth Vader",
"contact_method": {
"work": "503-555-0210",
"home": "503-555-0220",
"twitter": "@realdarthvader",
"skype": "AlwaysWithYou"
},
"schema_version": "2"
}
schema_version 필드를 통해 핸들러 함수를 추가하는 방식으로 동일한 컬렉션에 다양한 버저닝 데이터를 관리할 수 있다.
MongoDB 복제
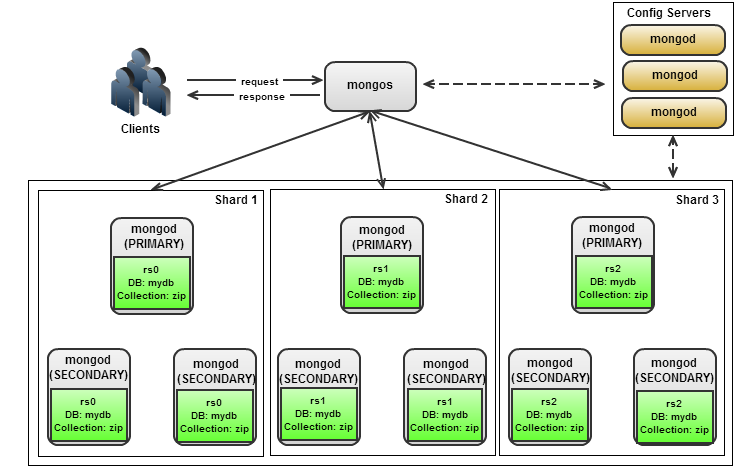
- config 복제, 샤딩을 위한 메타 데이터, 라우팅 테이블을 저장한다.
- mongos
config서버의 메타 데이터를 이용해 각 mongod 에 데이터 라우팅 - mongod
MongoDB의 데이터 서버
클라이언트의 요청을 처리하는 프라이머리, 복사본을 갖는 세컨더리 여러대를 합쳐 복제 셋 으로 부른다.
MongoDB 는 단일 쓰기를 지원하며 프라이머리 failover 를 위한 elect를 제공한다.
클라이언트는 연결할 드라이버를 위한 시드목록(seed list)을 사용한다.
추가적인 복원력을 위해 아래와 같이 DNS Seed list 연결 형식을 권장한다.
mongodb://server-1:27017,server-2:27017,server-3:27017
기본적으로 드라이버는 모든 읽기 쓰기 요청을 프라이머리로 라우팅한다.
읽기요청모드는 아래와 같다.
- primary(default)
프라이머리로 읽기요청 고정, 장애로 인해 연결되지 않을경우 기본적으로 드라이버는 모든 요청을 처리하지 않는다. - primaryPreferred
프라이머리 장애시 세컨더리로 읽기요청 전송 - secondary
세컨더리로 읽기요청 고정 - secondaryPreferred
모든 세컨더리 장애시 프라이머리로 읽기요청 전송 - nearest
가장 응답 지연율이 낮은 멤버에게 읽기요청 전송
읽기 요쳥의 부하분산을 위해 세컨더리 멤버에 읽기 요청을 보내는것은 권장하지 않는다.
해당 방식으로 부하를 복제셋의 모든 멤버가 처리하고 있다면 멤버의 failover 발생시, 데이터의 동기화에서 과부하가 발생하여 복제셋 전체 장애로 전파될 수 있다.
추천하는 읽기모드는 [primary, primaryPreferred, mearest] 이다.
부하분산을 원한다면 복제셋의 읽기요청을 분리하는것 보다 샤딩 사용을 권장한다.
동기화
세컨더리 인스턴스가 첫 생성될 때 초기동기화를 수행한다.
복제 대상으로 삼은 멤버의 각 컬렉션을 모두 스캔 및 삽입한다.
초기동기화가 종료되면 oplog 를 통해 실시간으로 데이터 복제를 수행한다.
프라이머리가 수행한 write 작업은 oplog 로 보관된다, 세컨더리는 oplog 의 동기화를 통해 복제를 수행한다.
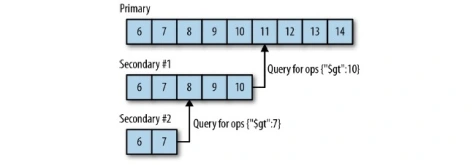
oplog 의 동기화 작업은 멱등하지만 만약 oplog 와의 충돌이 발생하면 세컨더리 서버는 종료된다.
oplog 크기 기본값은 990MB ~ 디스크 여유 공간의 5%(최대 50GB) 으로 쌓이는 log 속도에 따라 유동적이다.
삭제나 다중갱신처럼 여러 도큐먼트에 영향을 미치는 연산은 여러 개의 oplog 항목으로 분해된다, oplog 크기가 빠르게 증가하기에 사용량이 많아 50GB 가 부족하다면 더 늘릴 수 있다, 어플리케이션 사용 특성에 맞춰 oplog 크기를 설정하면 된다.
복제사슬
MongoDB 에선 자동복제사슬(automatic replication chaining) 을 사용한다, 세컨더리 노드들은 ping 시간을 기준으로 동기화할 대상을 결정한다.
멤버는 가장 가깝고 자신보다 앞서있는 멤버를 찾아 동기화 대상으로 선정하기에 복제 순환이 발생하지 않는다.
복제사슬의 depth 가 길어질수록 복제셋의 동기화 완료되는데 시간이 오래걸린다.
명령어로 복제대상을 수동으로 지정할 수 있다.
chainingAllowed: false 설정으로 프라이머리로부터의 복제를 강제할수 있다.
failover
Raft 합의 프로토콜을 기반으로하는 복제 프로토콜 v1 사용하여 프라이머리 failover 를 지원한다.
정족수를 요구하는 합의 알고리즘 특성상 홀수개 인스턴스 지원을 권장한다.
Raft 합의 프로토콜로 리더선출하기 전, 프라이머리 failover 를 지원하기 위해 여러가지 기믹을 사용한다.
- priority 값
0 ~ 100사이의 값으로 기본값은 1priority: 0으로 설정된 인스턴스는passive member라 부르며 프라이머리가 될 수 없다.- priority 값이 높은 멤버는 언제나 프라이머리로 선출된다. 만약 선출되지 않았다면 동기화가 완료된 후 다시 선출되도록 요청한다.
- hidden member
priority: 0으로 설정되며 read 요청을 받지 않고 복제서버(백업용)로만 동작한다.- 다른 세컨더리는 hidden member 를 복제 대상으로 삼지 않는다.
- 아비터 선출
- 복제서버를 리소스 부족으로 짝수개 구성해야할 때 사용
- 아비터 인스턴스는 프라이머리 선출에만 참여하며 데이터 복제는 수행하지 않는다.
- 아비터 인스턴스는 짝수에서 홀수로 가기위해 하나만 사용하는것을 권장하다.
각 멤버는 복제셋 내부 모든 멤버에게 heartbeat 요청을 보낸다.
자신을 포함하여 복제셋 내부 멤버들을 바라볼때 아래와 같은 상태값을 가진다.
- PRIMARY, SECONDARY
- 정상동작중인 쓰기 읽기 가능한 멤버 상태
- STARTUP
- 멤버를 처음 시작할 때의 상태
- STARTUP2
- 구성 정보가 로드된 상태, 초기동기화 과정 전반에 걸쳐 지속
- RECOVERING
- 동기화 완료후 세컨더리가 되기 전 거쳐가는 단계, 프로세스 준비중이라 읽기 작업은 수행할 수 없는 상태
- ARBITER
- 아비터 모드로 동작중인 멤버상태
- DOWN
- 네트워크 서버 등 각종 문제로 접근할 수 없는 상태
- UNKNOWN
- 한번도 연결되어본적이 없는 상태
- REMOVED
- 복제셋에서 제거된 상태
- ROLLBACK
- 롤백 진행중인 상태
롤백
Raft 에선 key-value 의 커밋과정(과반수 쓰기 성공), 로그 인덱스의 최신화 여부를 체크하고 투표하기 때문에 항상 최신의 노드가 리더로 선출된다.
하지만 MongoDB 에선 oplog 의 커밋과정이 따로 없기 때문에 구식 oplog 를 가진 멤버가 프라이머리 멤버로 과반수 투표를 받을 수 있다.
이 경우 최신 oplog 를 가졌었던 멤버가 다시 복구되었을 때 충돌이 발생함으로 롤백을 수행하고 다시 동기화를 수행해야한다.
롤백이 발생하면 특수한 롤백 파일에 기록된다, 복구할 수 있지만 수동 개입이 필요하 다.
만약 롤백이 발생하며 안되는, 복제보증이 필요한 쓰기 요청의 경우 애플리케이션에서 writeConcern(majority) 을 사용하여 과반수 멤버에 쓰기가 완료되는것을 강제할 수 있다.
config서버의 메타데이터 쓰기작업이majority로 되어있다.
try {
db.products.insertOne(
{ "_id": 10, "item": "envelopes", "qty": 100, type: "Self-Sealing" },
{ writeConcern: { "w" : "majority", "wtimeout" : 100 } }
);
} catch (e) {
print (e);
}
프라이머리는 쓰기 작업이 과반수에 복제될 때까지 응답하지 않는다.
쓰기 작업이 wtimeout 이내에 완료되지 않으면 에러메세지를 응답할 수 있으며 쓰기 작업이 실제로 완료되었지만 클라이언트 측에서 타임아웃 오류가 발생할 수 있다.
타임아웃 발생하더라도 재시도 시 멱등성 있는 동작을 하도록 구성하거나 실패에 대한 예외처리 방안을 구성해야한다.
MongoDB 샤딩
MongoDB 에선 구조를 추상화하고 시스템 관리를 간단하게 하는 자동샤딩(auto sharding) 을 지원한다.
샤드키, 컬렉션, 샤드를 호스팅하는 복제셋, 라우팅 테이블 등 샤딩 클러스터 운영에 필요한 데이터는 config 서버에 저장된다.
클라이언트는 데이터베이스 접근시 mongos 로만 통신한다, 아래와 같은 구조적 특징이 있음.
mongos는config서버를 통해 샤드가 몇개로 데이터가 분리되어 있건, 라우팅 프로세스를 사용해 샤드 클러스터가 하나의 서버로 보이게 지원한다.mongos는 최대한 다양한 샤드노드에 가까운 공간에 위치해야 한다.mongos는 쿼리 수행시 샤드키를 사용해 특정 샤드에서 데이터를 수집하고, 샤드키를 사용하지 않는 쿼리는 모든 샤드로 분산한 다음 결과를 수집한다.
클라이언트는 mongos 로 인해 클러스터에서 분리되어 아래 소개할 청크분할, 밸런서 과정을 알지 못하고, 해당 과정에서 발생하는 오버헤드로 인해 delay 만 발생할 뿐 오류가 발생하진 않는다.
MongoDB 4.2 이후부터 샤딩 클러스터 환경에서 분산 트랜잭션을 지원한다.
특정 샤드 멤버를 Coordinator 로 선정하고 2PC 기법을 통해 분산 트랜잭션을 진행한다.
샤딩키, 청크 분할
컬렉션을 샤딩할 때 인덱스가 설정된 필드를 기준으로 샤드키를 설정한다.
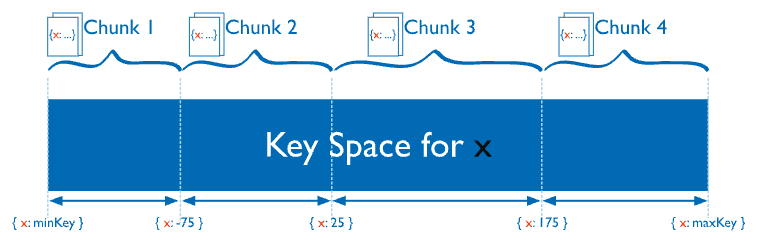
역기서 minKey 와 maxKey 는 음의무한대, 양의무한대라 볼 수 있다.
샤딩 설정된 프라이머리 노드들은 분할 임계치를 관리하여 샤딩키가 설정된 도큐먼트를 청크 단위로 분할한다.
config 서버에선 청크와 샤드가 매핑된 테이블을 관리하며 모든 config 서버가 동작중일 때 분할이 이루어진다.
config 서버가 정상동작 하지 않으면 분할 임계치를 넘어서고 계속 config 서버에 분할을 요청하는 분할소동(split storm)
- 오름차순 샤드키
- date, objectid 등 꾸준히 증가하는 타입
- 마지막의 추가되는 오름차준 샤드키 특정상 최대 청크(
$maxKey가 있는 마지막 청크)만 커진다. - 최대 청크의 분할과 마이그레이션이 지속적으로 일어날 수 있다.
- 무작위 분산 샤드키(randomly distributed shard key)
- 해시 샤딩키를 사용
- 해시 범위를 청크로 나누고 데이터를 분산 배치한다.
- 모든 청크가 고르게 커진다.
- 샤드키 범위 조회시 모드 워크로드의 흩어져있는 데이터를 모으는 과정에서 많은 데이터를 필요로한다.
- 위치기반 샤드키
- IP, 위경도, 주소
- 국가별 IP 위치정보를 기반으로 샤딩, 글로벌 서비스 제공시 사용하면 좋다.
샤드키로 사용할 필드는 자주 사용하는 인덱스, 카디널리티가 넓은(시간, 이메일) 필드를 사용하는것을 권장한다.
밸런서, 청크 마이그레이션
프라이머리 멤버의 백그라운드 프로세스로 청크 개수가 특정 마이그레이션 임계치에 이를 때 실행된다.
구성서버가 각 샤드의 청크 수를 모니터링한다 청크수가 마이그레이션 임계치 를 넘어가면 청크 마이그레이션을 위해 부하 샤드 멤버의 밸런서 를 실행시킨다.
청크개수가 많은 샤드에서 개수가 작은 샤드로 청크를 옮기기 시작한다. 그리고 config 서버에 메타데이터를 업데이트한다.
해당 과정 긴 시간동안 수행되며, 그사이에 mongos 가 이전 청크위치 요청 수행시 retry 처리 될 수 있다.
클러스터에서 트랜잭션
2PC 통해 트랜잭션의 일관성과 원자성을 보장
- Prepare Phase
- 트랜잭션이 관련 모든 샤드에 변경 사항을 예비 저장합니다. WAL에 기록.
- 각 샤드는 해당 작업을 수행할 준비가 되었음을 OK로 응답합니다.
- Commit Phase
- 모든 샤드에서 준비가 완료되면, mongos 가 각 샤드에 커밋 명령을 보냅니다.
- 각 샤드는 변경 사항을 최종 커밋하고, 응답합니다.
- 한 샤드라도 실패하면 트랜잭션은 Abort(롤백)됩니다.
여러 샤드에 걸친 트랜잭션은 네트워크 및 성능 오버헤드가 발생 트랜잭션 시간(default 60s)동안 Lost Update 발생 가능성