DynamoDB!
DynamoDB
Intro DynamoDB
https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/Introduction.html
AWS 에서 제공하는 완전관리형 Leaderless NoSQL
DynamoDB 는 테이블을 파티션단위로 쪼개 서버에 분리 저장하여 스케일 아웃을 지원한다.
10GB 용량을 넘거가거나 초당사용량이 1K WCU, 3K RCU 을 넘어가면 파티션이 지속적으로 늘어난다.
파티션은 3개의 AZ 로 자동 복제되기 때문에 가용성에 대해 걱정할 필요 없다.
파티션의 처리량은 고정되어 있기 때문에 접근량을 여러개의 파티션으로 분류해야 부하분산이 된다 할 수 있다.
기본키를 통해 데이터를 1개 읽어오는 서비스에서 효과적으로 사용할 수 있는 DB 이다.
요금
온디맨드, 프로비저닝 요금제가 존재하며 24 시간마다 변경 가능하다.
온디맨드
온디맨드는 트래픽 예측이 불가능할 경우, 용량 계획 없이 많은 요청을 처리해야 할 경우 유용한 요금제이다.
초당 수천개의 요청을 한자리수 밀리초 지연시간을 제공하며 실제 데이터를 읽고 쓴 만큼 요금을 지불한다.
프로비저닝(기본값)
어플리케이션별로 초당 읽기/쓰기 횟수를 지정하여 사용하는 방식, 물론 Auto Scaling을 사용하여 트래픽 변경에 따라 테이블의 프로비저닝된 용량을 자동으로 조정할 수 있음
애플리케이션 트래픽이 예측 가능한 경우 사용한다. 용량에 대해 상한, 하한을 지정할 수 있으며 사용량을 선결제(예약) 하는등의 작업이 가능하다.
처리량 제한이 있으며 이를 초과하게될 경우 바로 500 에러를 반환하기에 철저한 성능 계산후 결정해야 한다.
온디멘드의 경우 1회요청당, 프로비저닝 의 경우 1초당 금액을 청구한다.
- WCU(Write Capacity Unit) 1KB 쓰기(1회/1초)
- RRU(Read Capacity Unit) 4KB 읽기(1회/1초)
최종적 일관된 읽기 의 경우 4KB, 강력한 일관된 읽기 의 경우 2KB, 쓰기의 경우 1KB 를 1회로 지정한다.
프리티어로 월 25GB 용량은 무료제공되며 추가 GB 당
0.25$, 백만건당WCR(1.3$), RCU(0.3$)정도의 금액이 청구된다.
https://aws.amazon.com/ko/dynamodb/pricing/provisioned/
온디멘드 요청시 기본단위 미만 소비할 경우 올림처리되어 계산된다.
그리고 write 요청을 수행할 경우 속성 하나만 변경되어도 전체 item(row) 변경으로 취급하기에 item 은 작게 구성하는 것을 권장한다.
핵심 구성 요소
DynamoDB 구성요소로 테이블, 항목, 속성이 있다.
항목과 속성을 RDB 로 아래와 같이 표현할 수 있다.
- 항목은 레코드 혹은 튜플
- 속성은 필드 혹은 열
또한 속성이 가질수 있는 타입으로는 스칼라(숫자, 문자열, 이진수, 부울 및 Null)와 중첩된 속성(객채형식) 이 있으며 최대 32 개 깊이까지 중첩 가능하다.
DynamoDB Standard 테이블과 DynamoDB Standard-IA(Infrequent Access) 테이블이 존재하는데
DynamoDB Standard 이 기본값이며 일반적인 데이터를 처리하는데 사용되며 IA 의 경우 로그 및 과거 성과 데이터 등 자주 엑세스 하지 않는 데이터를 저장하는데 사용된다.
DynamoDB 의 특이한점은 보통의 데이터베이스처럼 사용하는 포트가 따로 있는것이 아닌 HTTP 프로토콜을 사용한다는 것
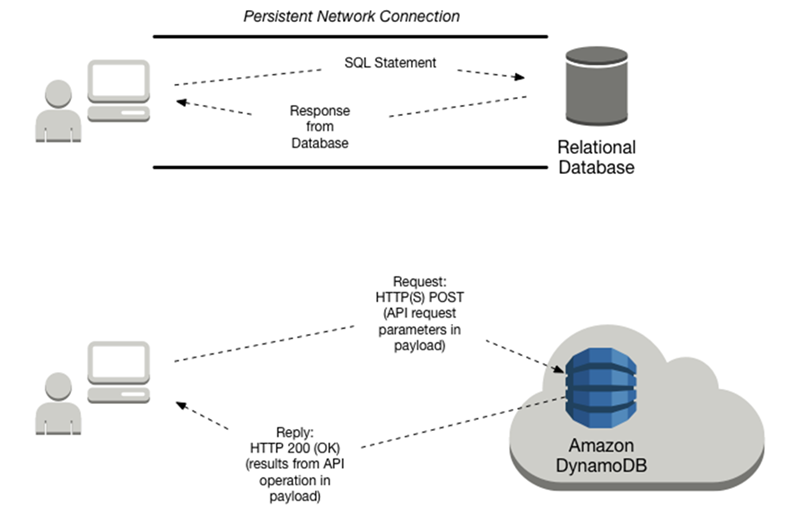
HTTP 에서 사용하는 인증방식, HTTP Status 에 결과 수신 등을 그대로 DynamoDB 에서 사용한다.
기본 키(Primary Key)
NoSQL 인만큼 기본키 외에는 별도의 스키마가 존재하지 않는다.
테이블 생성시 고유 식별자 를 가져야 하는데 2종류로 나뉜다.
1. 파티션 키
DB에서 일반적으로 생각하는 단순 기본 키 를 가리키며 해시 함수 출력에 따라 항목을 저장할 물리적 파티션(SSD 스토리지)이 결정된다.
2. 복합 키
복합키로 부르는 이 형식은 파티션 키와 정렬 키(PK & SK) 로 구성된다.
해시 함수에 대한 입력으로 파티션 키 값을 기준으로 파티션을 나누고, 파티션 키 값이 동일한 모든 항목은 정렬 키 값을 기준으로 정렬되어 함께 저장된다.
여러 항목이 중복된 파티션 키 값을 가질수 있지만 동일한 파티션 내에서 다양한 정렬 키값을 가져야 한다.
파티션키를 해시속성 혹은 해시키, 정렬키를 범위속성 이라고 부르기도 함
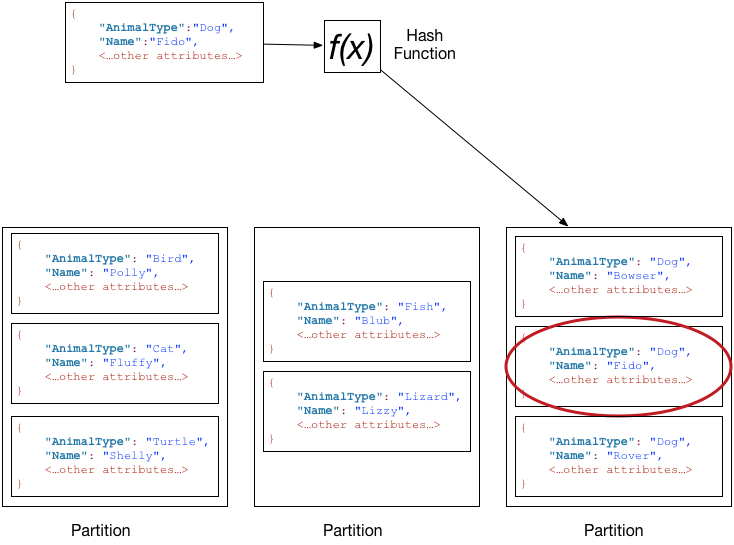
위 그림처럼 기본키를 AnimalType(파티션 키)와 Name(정렬 키)으로 구성된 복합 키로 가질 경우
파티션 키로 파티션을 찾고 정렬 키로 데이터 위치를 찾는다.
각 기본 키 속성은 스칼라여야 하며 문자열, 숫자 또는 이진수 가 포함된다.
기본 키를 통해서만 쿼리가 가능하기에 테이블 설계시 가장 중요한 요소이다.
기본 키를 통해 조회하지 않을경우 테이블 풀 쿼리가 발생하는데 상용 서비스에서는 사용할 수 없는 구조이다.
참고로 DynamoDB 에서 파티션 키를 자동으로 해시화하여 파티션을 지정해주기 때문에 해시형태의 ID 로 key 를 설정할 필요가 없다.
- 간단한
파티션 키- 조회 아이템을 파티션 키 하나로 CRUD 모두 가능한 경우
정렬속성조합하기- 보통 정렬을 위한 칼럼은 하나만 설정 가능한데 여러개 칼럼 정렬처리 하고 싶을 경우
{Status}#{생성시간:LocalDateTime}형태로복합키구성을 위한정렬속성를 구성하면 2개 칼럼을 정렬시킬 수 있다.
- 보통 정렬을 위한 칼럼은 하나만 설정 가능한데 여러개 칼럼 정렬처리 하고 싶을 경우
보조 인덱스 (Secondary Index)
DynamoDB의 경우 아예 인덱스를 사용하여 저장공간을 차별화 한다.
이때문에 보조 인덱스 생성시 반드시 기본 키 를 포함시킨다.

예로 위 Music 테이블은 복합 키를 사용하는 테이블로, {Aritst: 파티션 키, SongTitle: 정렬 키} 로 사용하는 테이블이다.
Music 테이블로부터 오른쪽의 GenreAlbumTitle 라는 {Genre: 파티션 키, AlbumTitle: 정렬 키} 형태의 보조 인덱스를 생성하였고 추가적으로 Music 의 복합 키를 가져왔다(프로젝션).
모든
보조 인덱스는 원본 테이블로부터 생성되며, 이 원본 테이블을 기본테이블 이라 한다.
테이블에는 여러개의보조 인덱스를 생성할 수 있다.
이제 Genre 와 AlbumTitle 속성을 가지고도 Music 테이블 데이터를 쿼리할 수 있게 되었다.
모든 Country 중 AlbumTitle 이 H로 시작하는 조건을 지정할 수 도 있다.
물론 보조 인덱스 를 사용하면 별도의 저장공간에 데이터를 저장하기에 실제 쓰는 데이터 용량보다 높은 비용이 발생할 수 있다.
기본테이블에 항목을 추가, 변경하면 DynamoDB는 테이블의 모든 인덱스에서 해당 항목을 추가, 업데이트 또는 삭제된다.
인덱스의 생성 방식을 토대로 2종류로 나누는데 아래와 같다.
-
GSI(Global Secondary Index) 기본테이블에서 사용하는
파티션 키및정렬 키가 다른 인덱스 생성시 사용.
최대 20개 까지 생성 가능 -
LSI(Local Secondary Index) 기본테이블의
파티션 키는 인데스의파티션 키와 동일하지만정렬 키가 다른 경우
테이블을 생성할 때에만 설정가능하며 생성 이후에는 추가, 삭제할 수 없음(일반적 상황에서 사용을 권장하지 않는다)
최대 5개 까지 생성 가능
아래는 PartiQL 를 사용하여 인덱스와 함께 테이블을 조회하는 쿼리이다.
# GSI 생성
CREATE INDEX GenreAndPriceIndex
ON Music (genre, price);
# 인덱스 사용 조회
SELECT *
FROM Music.GenreAndPriceIndex
WHERE Genre = 'Rock'
싱글 테이블 디자인
DynamoDB 의 경우 하나의 큰 테이블을 사용하는 싱글 테이블 디자인 사용을 권장한다.
테이블에 대한 모니터링, 관리비용, 가용성 을 쉽게 처리할 수 있다.
아래와 같이 3개 엔티티(customer, product, warehouse) 에 대해 싱글 테이블 디자인을 통해 테이블을 구성할 수 있다.
{
"PK": "C#12345", // customer
"SK": "C#12345",
"entityType": "customer",
"detail": {
"email": "kouzie@test.com",
"name": "kouzie"
}
}, {
"PK": "P#12345", // product
"SK": "P#12345",
"entityType": "product",
"detail": {
"price": 100
}
}, {
"PK": "W#12345", // warehouse
"SK": "W#12345",
"entityType": "warehouse",
"detail": {
"address": "seoul"
}
}
싱글 테이블 디자인 을 사용할 때에는 정렬 기능이 필요 없다 하더라도 정렬속성을 구성해서 복합키 형태로 기본키를 구성하는 것을 권장한다.
현재 3개 entity 의 경우 정렬기능이 필요없더라도 언제 어떤 추가 엔티티가 정렬속성이 필요해질지 모른다.
또한 PK 는 범위질의가 되지 않는점을 사전에 알고 설계해야한다.
RDB 에선 조인이 가능하기에 데이터 량을 줄이기 위해 정규화를 진행하여 엔티티의 데이터 구조를 미리 지정하고 테이블 설계를 들어가지만,
DynamoDB 에선 데이터를 우선 집어넣고 데이터 형태로 구조 의미를 부여할 수 있다.
{
"PK": "P#12345", // warehouse product quantity
"SK": "W#12345",
"entityType": "warehoutSetItem",
"detail": {
"quantity": 50
}
},
{
"PK": "O#12345", // order
"SK": "C#12345",
"entityType": "order",
"detail": {
"quantity": 50
}
}, {
"PK": "O#12345", // order item
"SK": "P#12345",
"entityType": "orderItem",
"detail": {
"price": 100,
"quantity": 2
}
}, {
"PK": "O#12345", // order item
"SK": "P#12346",
"entityType": "orderItem",
"detail": {
"price": 50,
"quantity": 1
}
}
{P#12345, W#12345}객체의 경우 특정warehouse에 위치하는 물품의 개수를 표현한 엔티티.{O#12345, C#12345}객체의 경우 사용자의 구매 엔티티.{O#12345, P#12345} {O#12345, P#12346}객체의 경우 구매의 구매목록 엔티티.
SK 를 정렬을 위한 CREATE_TIME, INDEX 등의 데이터를 설정할 수도 있지만
위와같이 다른 도메인의 개인키를 SK 로 사용하여 조인과 같은 기능을 구현할 수 도 있다.
이렇듯 키 디자인을 통해 설계한 PK, SK 를 사용하여 객체에 의미를 부여하고 계속해서 새로운 형태의 객체를 추가해나갈 수 있다.
주의사항
싱글 테이블 디자인에서 가장 주의해야할 점은 키 디자인이다.
기본 검색 수단이 PK, SK 밖에 없기 때문에 데이터의 그룹, 분리 정책을 키 디자인으로 잘 풀어내야 한다.
싱글 테이블 디자인에선 개발해야할 API 를 기준으로 키 디자인을 구성하는 것을 권장한다.
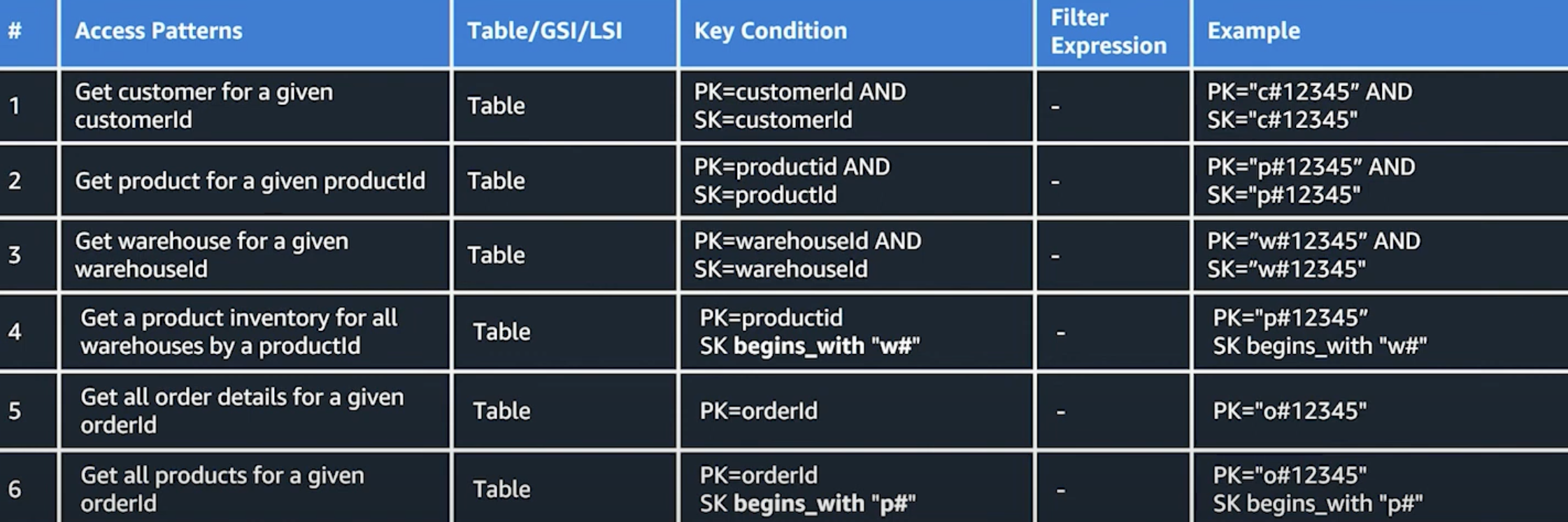
- 고객의 정보를 확인하기 위해선 {PK=CustomerId, SK=CustomerId}
- 고객의 구매목록을 확인하기 위해선 {PK=CustomerId, SK begins_with O#}
잘 사용하면 GSI 추가 없이 PK, SK 만으로 다양한 유스케이스 작성이 가능하다.
- Leaderless 특성을 가지고 있는 DB 특성상 정교한 일관성을 구현하는 것은 불가능하다. 본인이 개발하려는 서비스가 DynamoDB 특성과 잘 맞는지 확인해야한다.
PK, SK로 해결되지 않는 API 는 GSI 생성을 필요로 하고, 이는 곧 비용의 상승과 직결된다. 개발하는 도메인이 싱글 테이블 디자인과 잘 맞는지 먼저 확인해야한다.
모든게 적합하다면 DynamoDB 와 싱글 테이블 디자인 사용을 추천한다.
API
DynamoDB 에선 데이터를 읽을때 RestAPI 를 사용하며 아래 3가지 종류가 있다.
- GetItem
파티션 키를 사용하여 1개 이하 조회
- Query
보조 인덱스를 사용하여 여러개 조회,
- Scan
- 조건 필터링, 테이블 풀 스캔이 발생험, 데이터 마이그레이션 할 때에나 사용됨.
Query & Scan 의 경우 응답 메세지가 1MB 를 넘어가게 될 경우 자동으로 패이징이 발생하며
LastEvaluationKey 를 이용해 페이징처리를 해줘야 한다.
write 요청을 수행하는 3개 API
- PutItem
- UpdateItem
- DeleteItem
많은 양의 읽기/쓰기 처리를 해야한다면 Batch API 를 사용할 수 있다.
- BatchGetItem
- 단일 호출 최대 10개/16MB 반환 가능
- BatchWriteItem
- 단일 호출 최대 25개 PutItem & DeleteItem/16MB 쓰기 가능
여러개의 명령을 하나의 트랜잭션으로 수행해야할 경우(BEGIN … END 개념)
단 비용이 기존 읽기/쓰기 의 2배
- TransacGetItems
- TransacWriteItems
PartiQL
DynamoDB 에 저장된 데이터, 그중 테이블의 데이터 영역을 조회하기 위해 여러가지 방법이 있는데
클래식 CRUD API 를 호출하거나 PartiQL 언어를 사용해 데이터 영역을 CRUD 한다.
클래식 CRUD API 의 경우 REST API 형식과 유사하고
PartiQL 의 경우 RDBMS 에서 사용하면 SQL 언어와 유사하다.
또한 DynamoDB 는 트랜잭션 기능을 지원하는데 이때문에 아래 2가지 읽기 방식이 존재한다.
최종적 일관된 읽기(Eventually Consistent Read)
최근 완료된 쓰기 작업의 결과가 반영되지 않을 수 있다. 특히 GSI 의 경우 Async 로 운영되기에 데이터가 정확히 동기화 되지 않을 수 있다.
강력한 일관된 읽기(Strongly Consistent Read)
모든 쓰기 작업이 완료된 가장 최신 데이터를 포함하여 응답한다.
단 네트워크 지연 또는 중단이 발생할 경우 HTTP 500 에러가 반환되거나 속도가 지연될 수 있다.
또한 GSI 에서는 강력히 일관된 읽기가 지원되지 않는다.
PartiQL - Amazon DynamoDB용 SQL 호환 쿼리 언어 https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/ql-reference.html
RDB 에서 Music 테이블에 데이터를 넣으려면 아래 같은 SQL 문을 사용한다.
INSERT INTO Music
(Artist, SongTitle, AlbumTitle,
Year, Price, Genre,
Tags)
VALUES(
'No One You Know', 'Call Me Today', 'Somewhat Famous',
2015, 2.14, 'Country',
'{"Composers": ["Smith", "Jones", "Davis"],"LengthInSeconds": 214}'
);
DynamoDB 의 경우 정형화된 스키마가 없다보니 앞의 속성 관련 내용은 삭제되고 객체형태의 데이터를 바로 입력한다.
INSERT into Music value {
'Artist': 'No One You Know',
'SongTitle': 'Call Me Today',
'AlbumTitle': 'Somewhat Famous',
'Year' : '2015,
'Genre' : 'Acme'
}