DB 복제!
복제
https://www.yes24.com/Product/Goods/59566585
https://www.brianstorti.com/replication
이번 포스팅에선 RDB, NoSQL 에서 가용성을 위한 DB 복제 방법을 알아본다.
고부하가 발생하여 확장이 필요하다면 CPU, Memory 를 늘리는 수직확장이 가장 간단하지만 갈수록 비용이 비싸진다.
수직확장으로 성능을 무한히 끌어올릴 수 없고, 무한한 비용을 지불할 수 없기에 수평확장을 해야한다.
CPU core 가 메모리, 디스크를 공유하기에 수직확장을
공유 메모리 아키텍처(shared-memory architecture), 수평확장을비공유 아키텍처(shared-nothing)라 부르기도 함.
수평확장은 특별한 하드웨어를 필요로 하지 않아 가격대비 성능이 가장 좋은 시스템을 사용할 수 있다.
DB 에서 수평확장으로 분산하는 방법은 아래 두가지.
- 복제: 데이터의 복사본을 여러 노드에 유지, 일부 노드가 불가능 상태일 때 복구기능을 가지고 있음.
- 파티셔닝(샤딩): 데이터를 쪼개 각기 다른 노드에 할당.
수평확장시 데이터의 복제, 다중 노드에서 트랜잭션에 대해 고민해야할 부분이 생긴다.
DB ACID 원칙을 지키기 위해 write 요청이 모든 replica(복제서버)에 전달되어야 한는데, 가장 일반적인 해결책은 leader-based replication 이다.
leader와read replica는 여러가지 이름으로 불림.
leader:active, master
read replica:passive, slave, secondary, read replica, hot standb
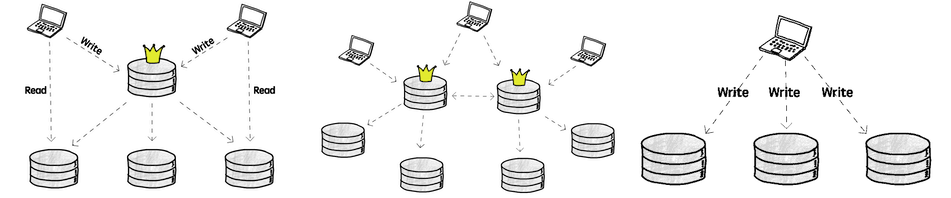
leader 와 동기화 되는 read replica 를 운영하는 방법은 아래 3가지,
leader 개수 순서대로 [single-leader, multi-leader, leaderless] 아키텍처 구성이 가능하다.
각 아키텍처별로 쓰기 충돌 이 발생했을 때 복구를 위한 충돌 회피 시나리오가 있다.
복제 환경은 모든 네트워크, 시스템이 분리되어 있어 부분장애가 언제든 일어날 수 있고 성공과 실패 여부도 정확히 알 수 없어 비결정적이다.
해당 환경에서 빠르게 결함있는 노드를 감지하고 일시적 네트워크 지연 장애인지, 장기적 결함인지 판단하고 기존 시스템이 정상 운영될 수 있도록 자동 복구되어야 한다.
single-leader
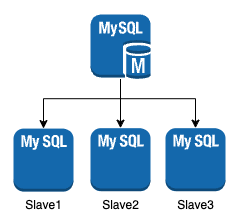
대부분 RDB 에선 single-leader 아키텍처를 사용. Master/Slave 구조라 부르기도 함.
leader 에서 write 요청을 처리할 때 마다 replication log(change stream) 을 read replica 에게 전달한다.
이때 해당 replication 를 논리적 로그(logical log) 라 부른다.
log와row는 1:1 매핑되어 연결되어 있다.- 다수의
row를 수정하는 트랜잭션은 다수의log를 생성 후 커밋됐음을 레코드 에 표시한다. log기반 복제는log를 파싱해 ETL 구축도 쉽게 연동할 수 있다.- MySQL 의 경우
log비교를 위해binlog coordinate(이진로그) 기법을 사용한다.
아래 그림이 logical log 가 read replica 에전달되는 과정.
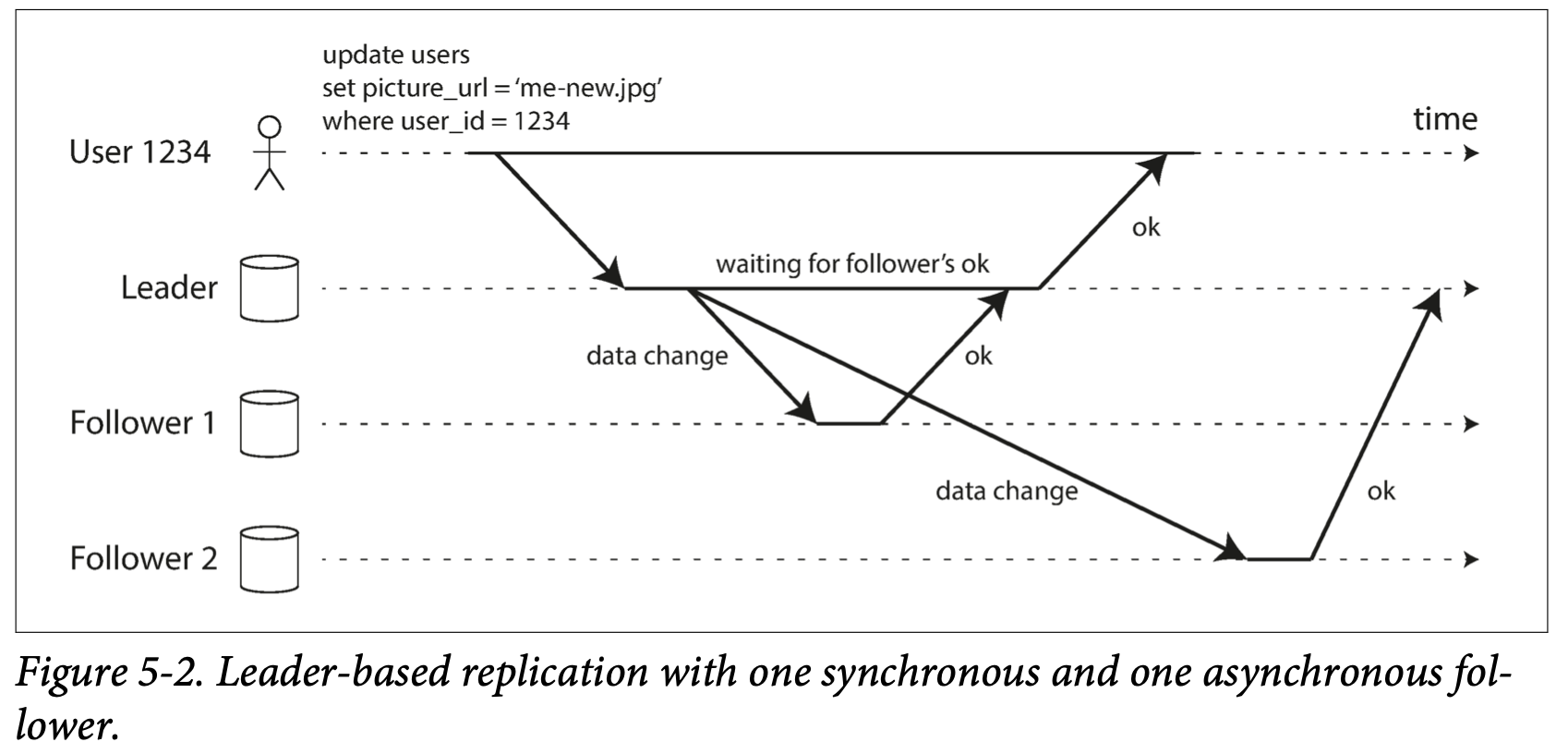
follower1은동기식 복제follower2는비동기식 복제
동기식 복제 는 시스템,네트워크 문제가 있을 수 있기 때문에 반환시간이 얼마나 걸릴지는 보장할 수 없다.
비동기식 복제 는 복제 적용 여부를 확인하지 않기 때문에 여러 충돌 시나리오에 휘말린다.
비즈니스 로직에서 replica 들의 철저한 동기과정이 필요할 경우 동기식 복제를 사용.
두 방법 모두 장단점이 있지만 복제 지연 문제로 인해 비동기식 복제를 주로 사용한다.
비동기식 복제 를 사용하면 read replica 에 문제가 발생해도 시스템은 정상동작한다.
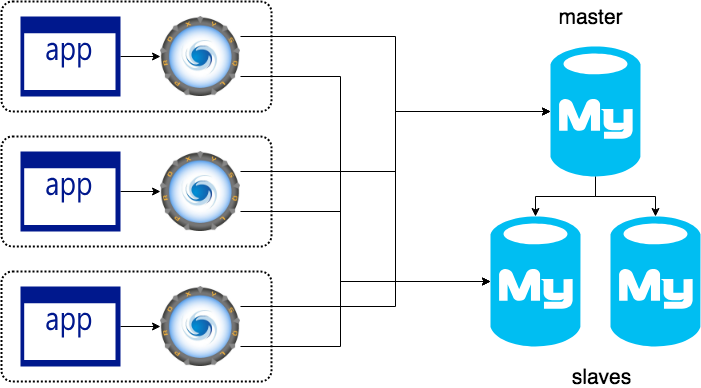
대부분 아래와 같은 Master/Slave 구조이지만,
잘 사용하진 않지만 읽기 조인 쿼리를 위해 아래와 같은 MSR(Multi-Source Replication) 를 사용하기도 한다.
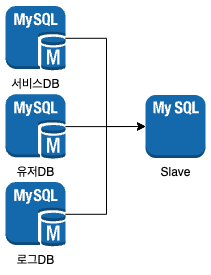
사진 출처: https://devocean.sk.com/blog/techBoardDetail.do?ID=166825
규모가 크지 않은 MSA 서비스에서 사용하는 것을 권장하고, 시간이 지남에 따라 read replica 서버의 성능 모니터링이 필요하다.
규모가 커지기 전, HBase 와 같은 고성능 NoSQL 로 이동하기 전에 사용하는 아키텍처라 생각됨(뇌피셜).
failover
read replica failover 는 leader 스냅숏 과 그 이후의 모든 데이터 미처리분인 backlog 를 가져와 read replica 와 비교 한뒤 적용하여 복구를 마친다.
backlog 작성시간까지 leader 와 동기화 되었다 할 수 있다.
leader failover 또한 스냅숏과 backlog 를 사용하지만 추가로 고려해야할 상황이 많다.
reader replica 중 하나를 leader 로 승격하는 leader 선출 과정에서 replica 들의 실행이 변경되어야 한다.
leader 선출 과정에서 이상의 노드가 자신을 leader 로 생각하는 스플릿 브레인(split brain) 문제가 발생할 수 있다.
leader 에서 비동기식 복제 사용시 동기화 되지 못한 write 요청 이 유실될수 있다.
MySQL 의 경우 leader 의 failover 는 사람이 수동으로 복구를 하는 편이다.
24시간 실행되어야 하는 어플리케이션의 경우 하나이상의 read replica 에서 복제완료 응답을 받는, 동기/비동기식을 혼합해서 사용하는 반동기식(semi-synchronous) failover 방법도 많이 사용한다.
하지만 Hadoop 과 같은 대규모 분산 클러스터에선 수동복구는 쉽지 않아 자동 leader 선출 을 위한 합의 알고리즘 을 사용한다.
MongoDB 의 경우에도 복제환경에서 하나의 프라이머리 멤버를 가지는 single-leader 방식이며 leader 선출 을 위해 합의 알고리즘 을 사용한다.
LoadBalancer
leader failover 가 발생하면 어플리케이션은 새로 승격된 write replica 의 주소로 요청을 보내도록 업데이트 되어야 한다.
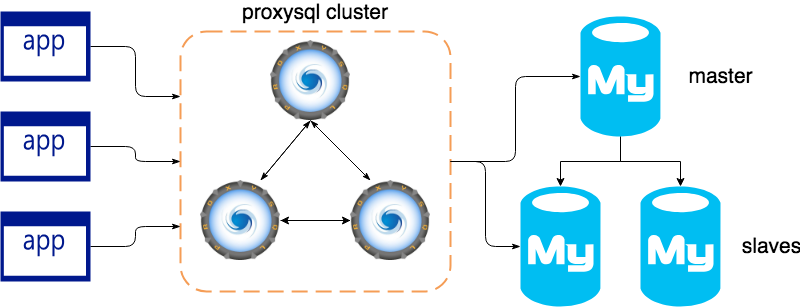
대부분의 경우 어플리케이션이 접근하는 write replica 주소를 업데이트하진 않고 중간에 proxy layer 를 두어 자동 failover 처리되도록 한다.
[HAProxy, PgPool, MaxScale, ProxySQL] 등 여러가지 솔루션이 있으며 MySQL 진영에선 ProxySQL 이 가장 많이 사용된다.
아래 그림처럼 어플리케이션 은 ProxySQL 을 통해 MySQL DB 에 접근하고 leader failover 에 대해선 신경쓰지 않아도 된다.
복제 지연
비동기식 복제 방식을 사용하면 read replica 를 많이 만들어도 영향이 적고 높은 read-scaling 을 얻을 수 있다,
하지만 모든 read replica 들이 동일한 데이터를 가지고 있는지는 보장하지 못한다.
비동기식 복제 에서 복제 지연이 길어지면 아래와 같이 자기가 작성한 내용도 보지 못하는 쓰기 후 읽기 일관성(read after write consistnecy) 문제가 발생한다.
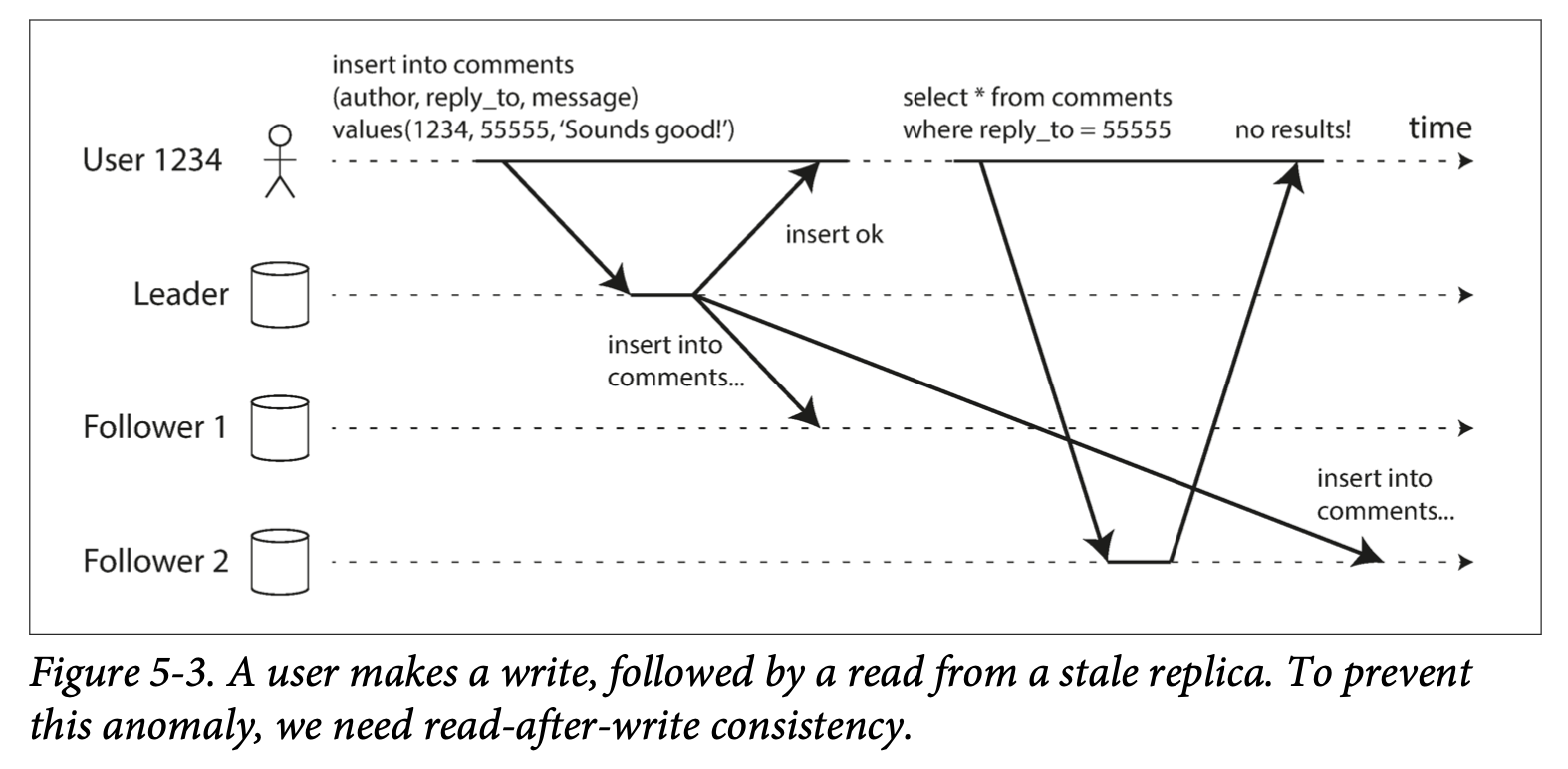
read replica 가 많아질수록 데이터의 불일치성은 심해진다.
잘 사용하지 않지만 복제 지연 해결을 위해 어플리케이션 레이어에서 할 수 있는 몇가지 조치방법이 있다.
- 동기화가 중요한 로직에선
leader에서만read/write 요청진행. - 읽어온 데이터의 마지막 갱신시간이 1분 미만이라면 이후
read 요청도leader에서 진행, 1분 이후 부턴read replica에서도read 요창진행.
어플리케이션에서 DB 접근을 변경하는건 까다롭기 때문에 거의 사용하지 않는다.
multi-leader
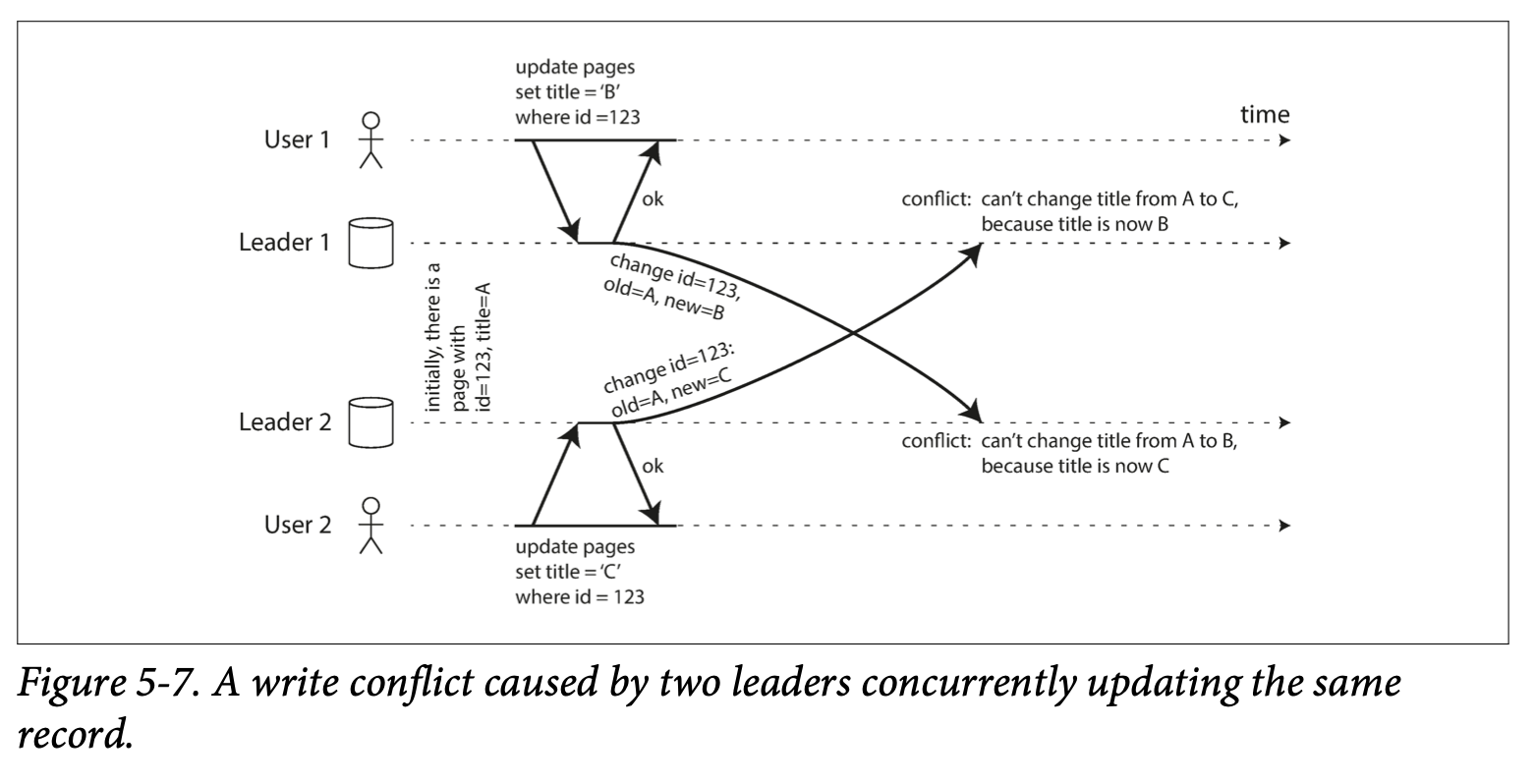
multi-leader 복제는 leader 간 복제에서 쓰기 충돌 이 발생할 수 있다.
아래 그림은 multi-leader 에서 거의 동시 write 요청 을 비동기식 복제 로 처리시 발생하는 쓰기 충돌 시나리오 이다.
동기식 복제사용시쓰기 충돌을 해소할수 있지만sigle-leader를 사용하는 것이 성능상 더 낫다.
만약 한개 row 에 대해서만 충돌 회피 를 구현하려면 아래와 같은 사전 규약을 몇개 만들면 가능하다.
- 특정 레코드
write 요청은 특정leader에서만 처리. last write wins(LWW)방법 사용고유 ID(timestamp, uuid, hash)를 부여하고 우선순위를 적용.leader에 우선순위를 적용.
versioning을 사용,write 요청에 대한 결과를 반환.
leaderless
leaderless 복제는 는 aws Dynamo 시스템에서 사용한 후 다시 유행했다.
카산드라, 볼드모트등이leaderless복제 기반 DB 가 있음.
복제서버에 병렬로 write/read 요청을 전송한다.
n개 복제서버에서w개 노드에서write 요청성공하면 성공으로 간주.n개 복제서버에서r개 노드에서read 요청성공하면 성공으로 간주.- 노드 수에 따른 설정
w = r = (n + 1) / 2
아래 그림은 n=3, w=2, r=2 인 경우
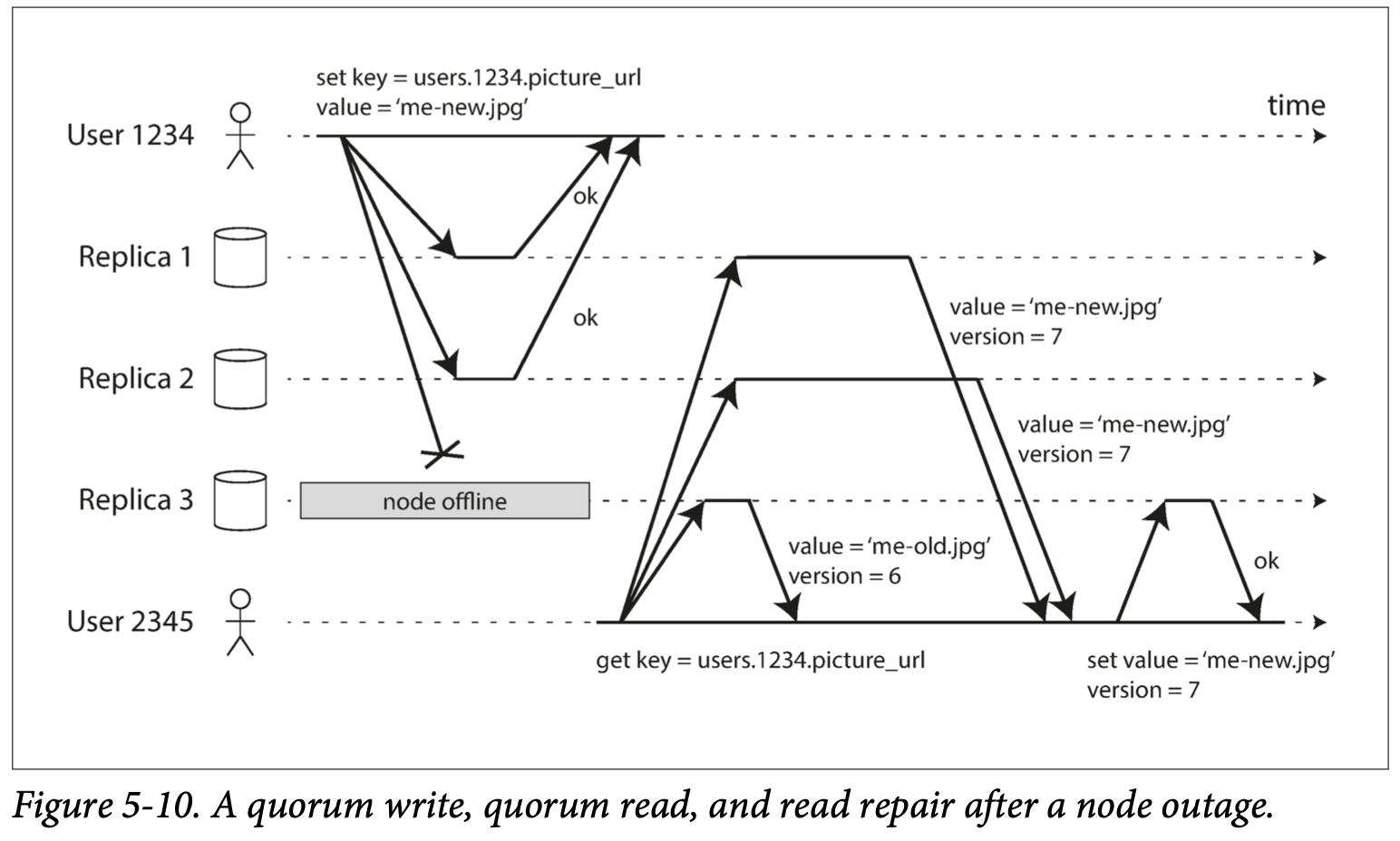
실패한 write 요청 를 처리하기 위해 2가지 방법을 사용.
- 읽기 복구: 위 그림처럼 read 요청 반환값을 사용.
- 안티 엔트로피: 백그라운드 프로세스가 복제서버간 차이를 지속적으로 찾음.
가십 프로토콜
노드의 장애는 정전, 네트워크 장애, 자연재해 등 여러 이유로 발생할 수 있다.
분산형 장애 감지(failure detection) 솔루션으로 가십 프로토콜(gossip protocol) 를 사용하여 장애 노드를 감지할 수 있다.
각 노드는 heartbeat counter 주기적으로 무작위로 선정된 노드들에게 보내면서 자신이 살아있음을 지속적으로 알린다.
특정 시점을 기준으로 heartbeat 가 업데이트되지 않은 노드가 발견되면 장애 상태로 간주하고 동기화 과정에서 제외된다.
선형성(Linearizable)
살아 있지만 틀린 게 나은가, 올바르지만 죽은 게 나은가? 제이 크렙스, 카프카와 젭슨에 대한 몇 가지 기록1 (2013)
- 강한 일관성(strong consistency)
모든 읽기 연상은 가장 최근에 갱신된 결과를 반환. - 약한 일관성 보장(weak consistency)
읽기연산은 가장 최근에 갱신된 결과를 반환하지 못할 수 있음. - 최종적 일관성(eventual consistency)
약한 일관성 중 하나, 쓰기를 멈추고 기다리면 갱신 결과가 언젠간 동기화 되는 모델.
복제 환경에서 가장 단순한 일관성 보장 방법은 최종적 일관성 이다.
좀더 강력한 방법으로 일관성을 보장하는 선형성(Linearizable) 에 대해 알아본다.
선형성은 강한 일관성 을 포함하는 개념으로 최신성 보장(recency guarantee) 라 불리기도 한다.
다음 그림처럼 클라이언트A,B 는 read(x) 값을 읽을때 0과 1이 번갈아 출력될 수 있으며 이는 선형성이라 부를 수 없다.
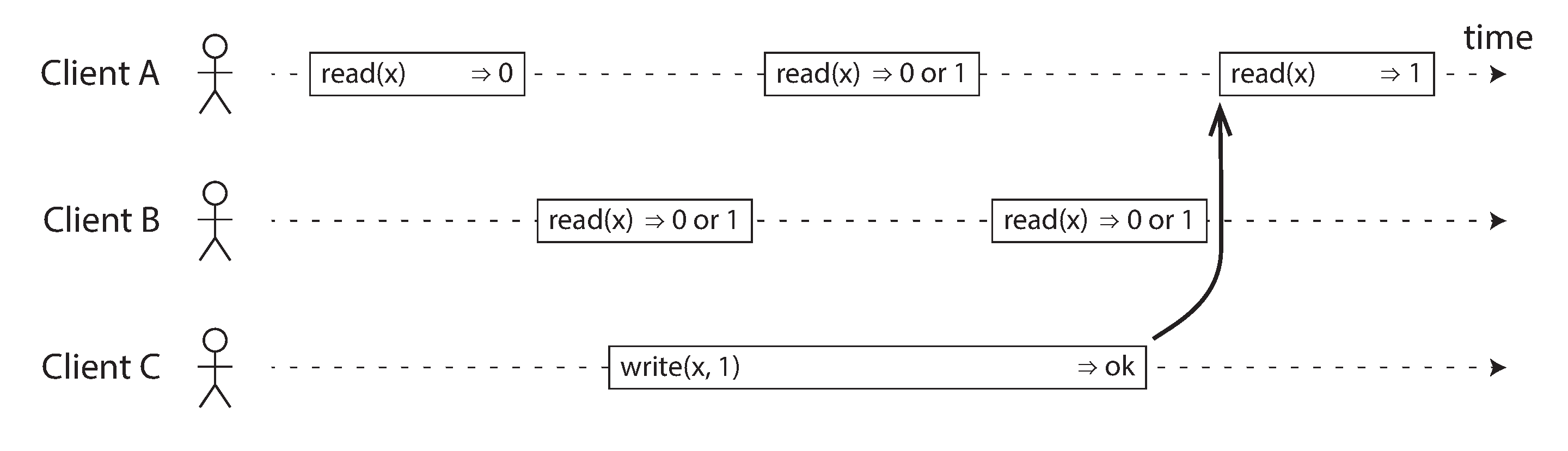
특정시점에서 반환값이 최신값으로 결정되었다면, 해당 시점 이후로는 모든 클라이언트에서 최신화된 값을 받아야 한다.
선형성이 구현되었다면 아래 그림과 같이 ClientA 가 read(x)=>1 를 수신한 순간부터 ClientB 에서도 동일한 결과값을 받도록 결정되어야 한다.
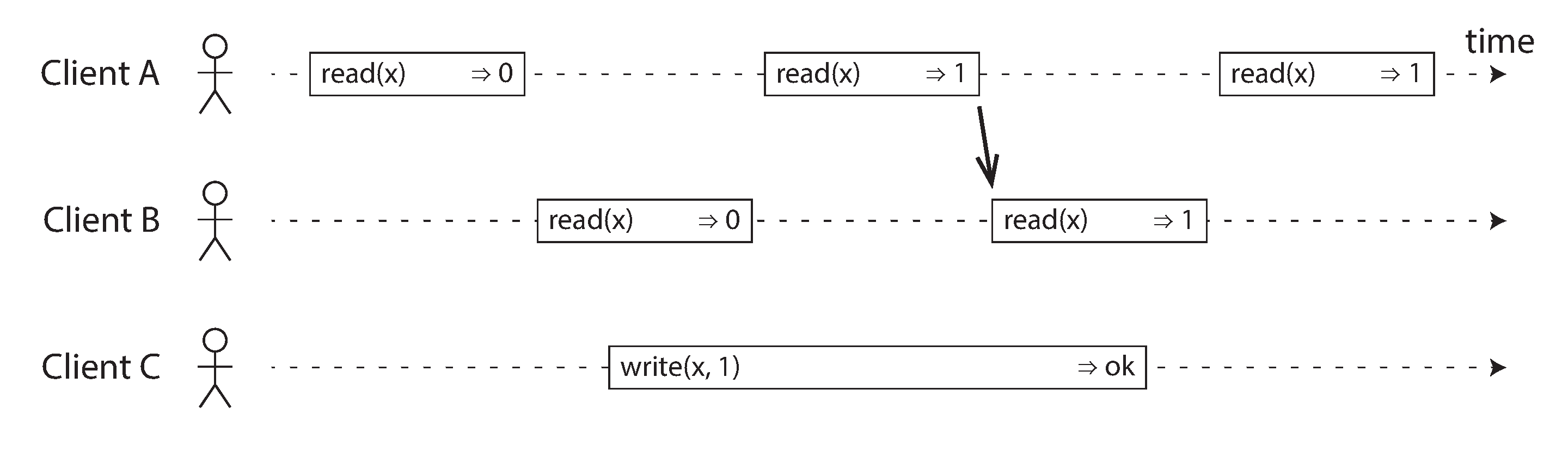
선형성은 데이터의 일관성 있는 read & write 에서도 사용되지만 서비스에서 구현해야할 [잠금장치, 제약조건(unique)] 을 구성하는데에도 중요하게 사용된다.
복제환경에서 선형성을 구현하기는 쉽지 않다.
선형성을 구현하는 일반적인 방법은 모든 사본에 현재 쓰기 연산의 결과 가 반영될 때까지 해당 데이터에 대한 읽기/쓰기를 금지하는 것이다.
single-leader 에서 분산락 혹은 동기식 복제(2PC) 를 사용해야 겨우 선형성 을 비슷하게 구현할 수 있다.
CAP 정리
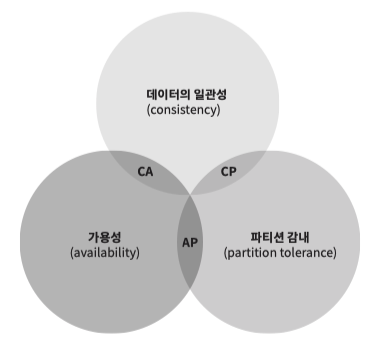
CAP 정리 는 파티션 감내(Partition tolerance) 이 발생했을 때 일관성(Consistency) 과 가용성(Availability) 을 모두 만족하는 시스템은 구현할 수 없다는 이론이다.
항상 가용성 과 일관성을 저울질하며 어떤것을 우선시할지 결정해야한다.
파티션 감내(Partition tolerance) 은 복제 노드가 죽거나, 네트워크가 차단된 상황에서 데이터의 복구를 뜻한다.
실세계에 완벽한 CA 시스템은 존재하지 않는다.
복제 환경에서 선현성(완벽한 Consistency)을 구현하는건 불가능하다, 네트워크 지연으로 미처 업데이트하지 못한 replica 의 과거 데이터를 클라이언트가 read 하는 것을 막을 순 없다.
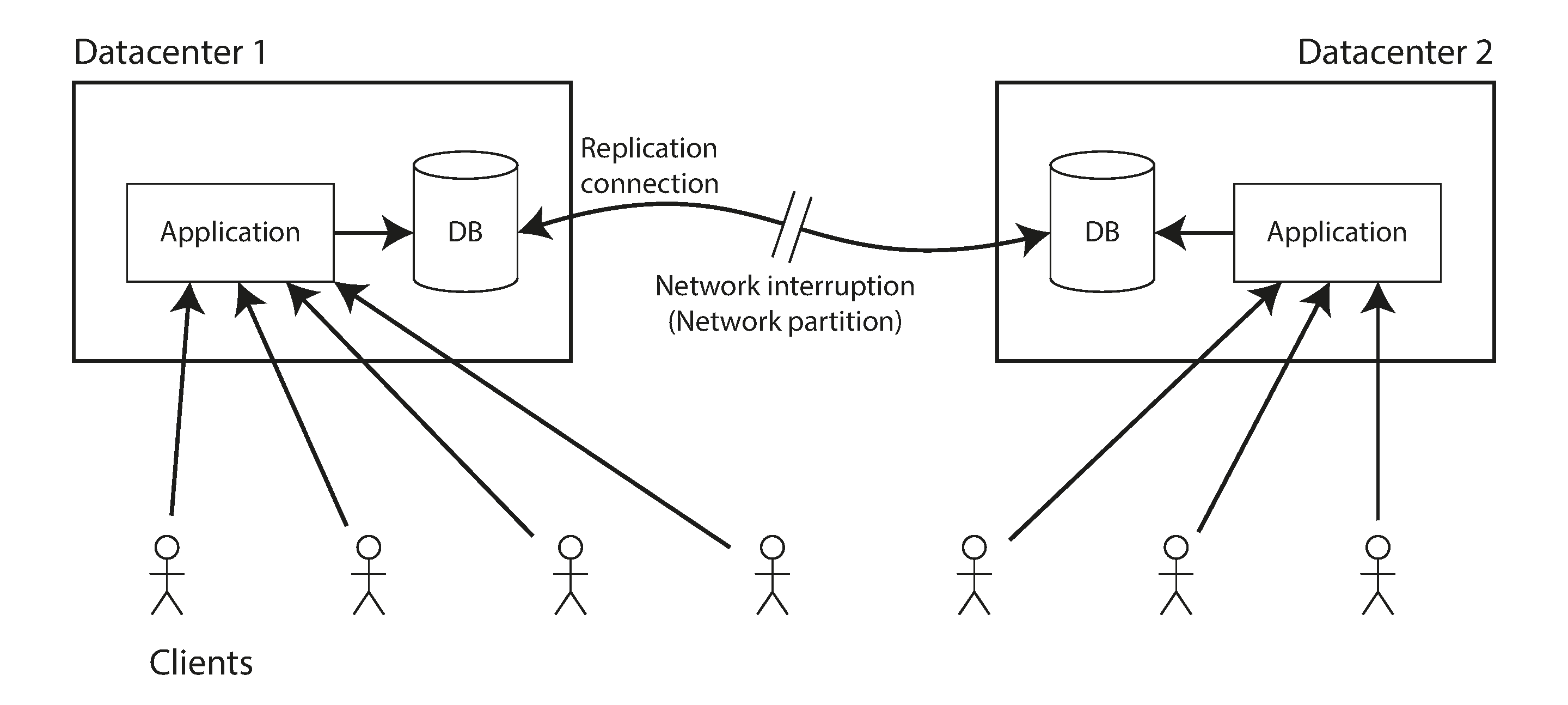
위와 같이 Datacenter1(leader), Datacenter2(replica) 로 구성될 때, 둘 사이 연결이 끊기면 Datacenter2 가 leader 로 승격하면서, 데이터 동기화가 깨짐과 동시에 일관성도 깨진다.
위와 같은 상황에서 일관성 을 구현하려면 연결이 끊긴 replica 는 복구될 때까지 시스템 중단되어야 한다.
대부분의 경우에서 선형성을 위해 가용성을 전부 포기하지 않는다. 완화된 일관성 을 지향하고 선형성이 필요한 상황을 회피하는 방법을 사용하는것이 일반적이다.
인과적 의존성(causally consistent)
복제 환경에서 가장 간단한 충돌 회피 방법은 LWW 이지만 아래 그림처럼 일부 write 요청 이 유실될 가능성이 있다.
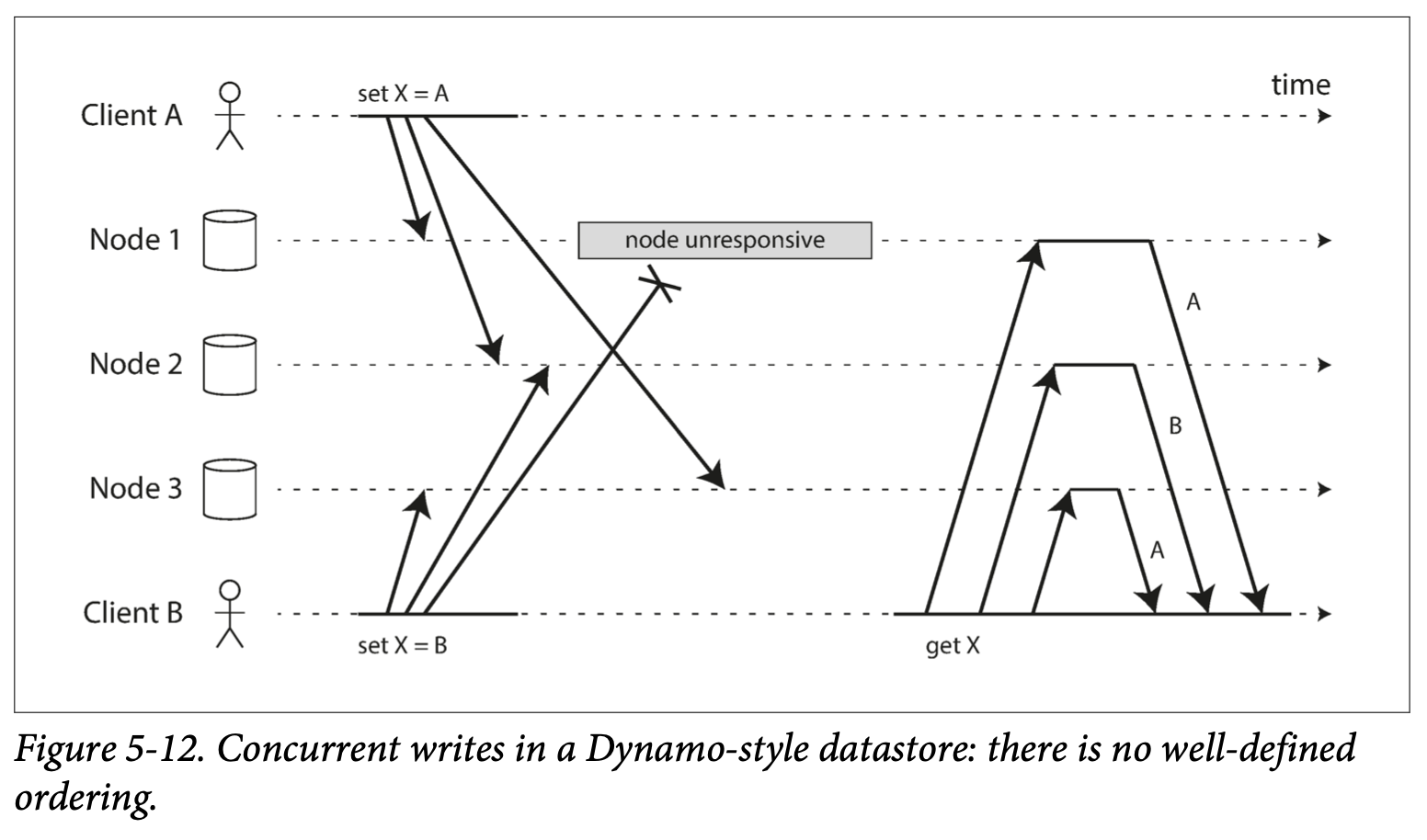
ClientB 에서 요청한 set X=B 연산은 병합되는 과정에서 없었던 일이 되어버린다.
그림과 같이 여러개의 writer replica 환경에서 발생하는 충돌 회피 방법 중, 인과적인 관계를 사용하여 충돌을 회피하는 방법이 있다.
- Version Vector
- Vector Clock
- Lamport Timestamp
두 이벤트에 인과적인 관계 가 있으면 이들은 순서가 있다는 뜻이고, 어떤 연산이 먼저 실행됐는지 인과성을 유지할 수 있게된다.
인과적 의존성 을 사용하면 완화된 일관성을 사용하면서도 선형성이 필요한 비즈니스에 대안으로 사용할 수 있다.
인과적 의존성 을 사용한 충돌 회피 방법은 모든 요청에 version, timestamp 을 관리하여 값을 덮어 씌우는 방식이기 때문에 write 요청 유실없이 충돌 회피 가능하다.
유실이 없는 대신 데이터의 추가적인 병합 과정이 필요하다.
Version Vector
아래는 2개의 클라이언트가 [milk, eggs, flour, milk, ham, eggs, bacon] 을 같은 장바구니에 동시에 삽입하는 예제이다.
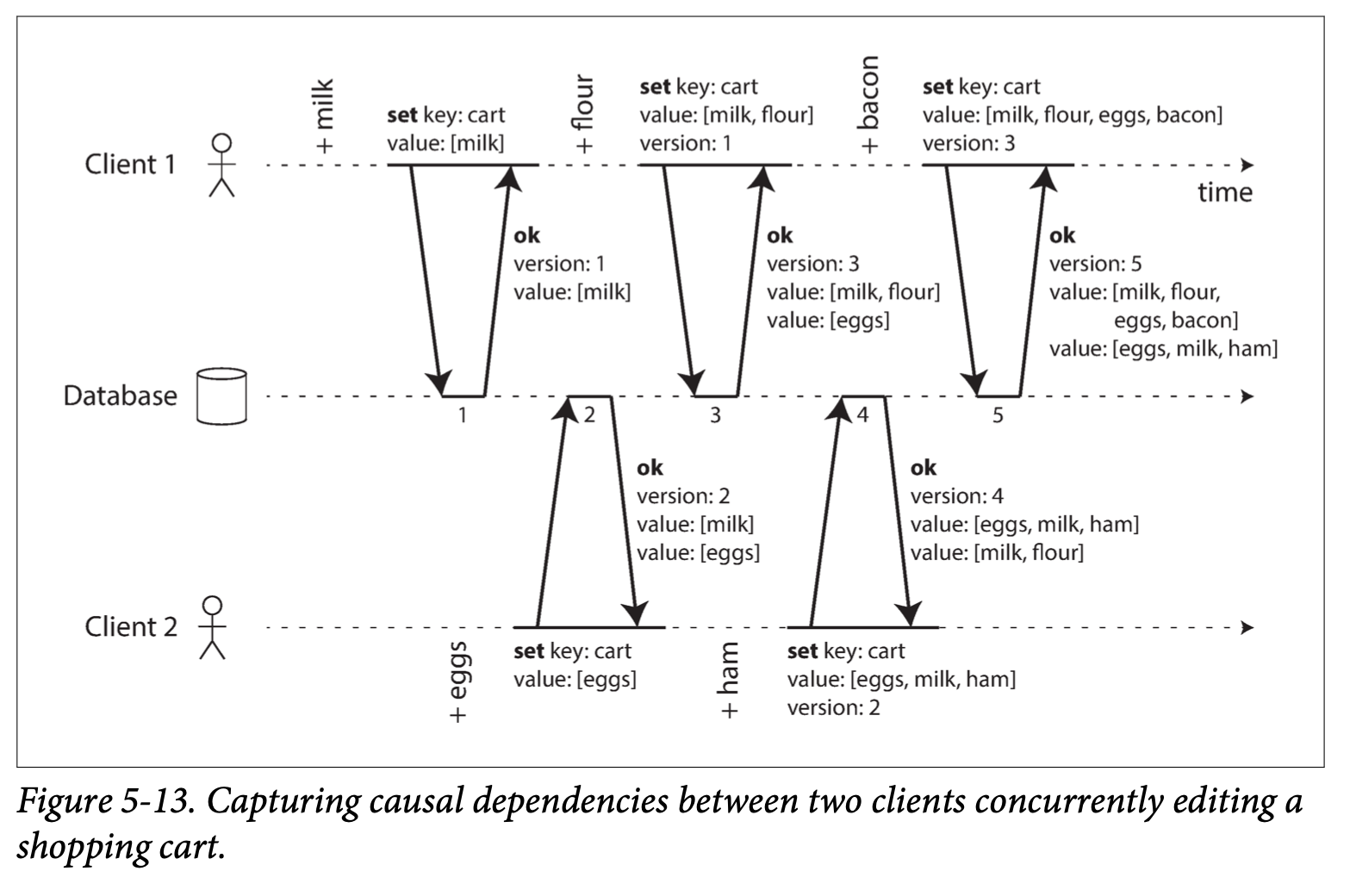
[milk, eggs] 의 경우 모든 version 에 들어가게 되면서 중복되는데, leaderless DB 에서 자체적으로 병합을 처리해준다.
위 그림은 단일 DB 에 대해서 설명하지만 다중 replica 라 하더라도 [노드, 버전]의 순서쌍을 키값으로 사용하면 모든 write 요청 에 대한 유일한 versioning 인 버전 벡터(version vector) 를 생성할 수 있다.
노드(replica)별로 버전(카운터)를 관리하고, 질의시 [노드, 버전]를 모두 알고 있어야 접근 가능하다.
모든 연산과정에 버전 벡터 을 사용한다면 모든 연산에 대해 인과적 의존성 을 알 수 있고 최종적 일관성 을 지킬 수 있다.
Lamport Timestamp
일종의 Logical clock 알고리즘
동기화 때 받은 clock 이 자신의 clock 보다 클 경우 1을 더해 clock 을 업데이트한다.
항상 낮은 clock 에서 높은 clock 으로 업데이트한다.
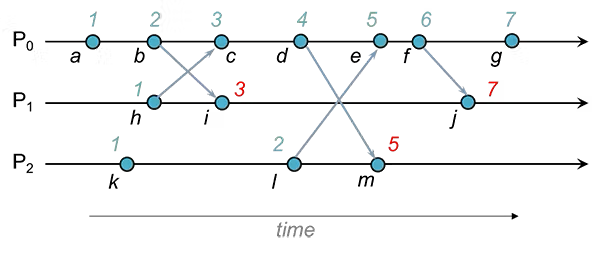
Version Vector 와 다르게 실행의 선형성만을 기반으로 데이터를 업데이트 하기에 이전 행동의 인과적 의존성 에 의한 일관성 유지 방법과는 다르다.
Lamport Timestamp 을 DB replica 에 적용하면 아래 그림과 같이 사용할 수 있다.
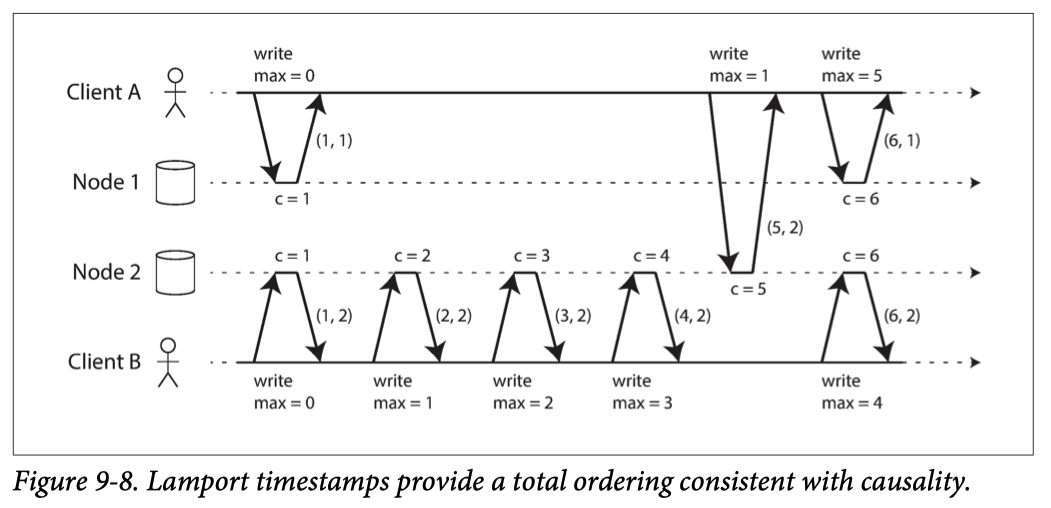
그림처럼 ID 값으로 [Logical Clock, 노드번호] 를 사용하여 유일 key 값으로 사용하고,
항상 최신값으로 유지되는 Logical Clock 을 사용해 이전버전이 덮어씌어지는 충돌을 회피한다.
multi-leader, leaderless 환경에서 사용하는 카운터 기법으로 Lamport Timestamp 를 사용할 수 있다.
Vector Clock
git 의 branch 병합 과정과 유사한 기법.
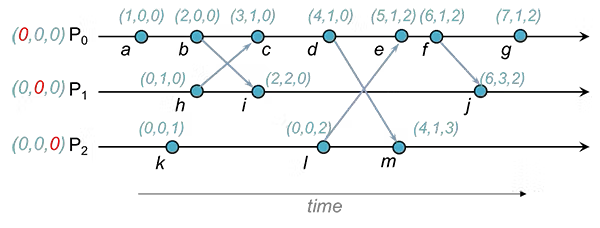
동일한 데이터를 3개의 프로세스가 업데이트 하는 그림, 프로세스별로 관리하는 clock 을 모두가 공유한다.
모든 프로세스의 clock(version) 을 공유하기 때문에 인과적 의존성 파악이 가능하다.
단 프로세스간 별도 운영하던 데이터가 합쳐지는 과정에서 병합 과정을 거쳐야 한다.
2PC(Two-Phase Commit: 2단계 커밋)
복제환경에서 하나의 논리적 트랜잭션을 원자적으로 처리하기 위한 방법 중 하나.
이전 발생 같은 방식으로 인과적 의존성 구현 시 write 요청 의 정확한 결과는 병합과정 이후에나 알 수 있다.
계정 중복체크와 같은 제약조건과 동시성이 중요한 로직에선 write 요청 의 결과를 확인해야 한다.
2PC 에서 트랜잭션을 조율하는 조정자(Coordinator), 참여자(participant) 가 존재하며, 모든 DB 에게 준비→확인→커밋→확인 형식으로 일관성을 유지한다.
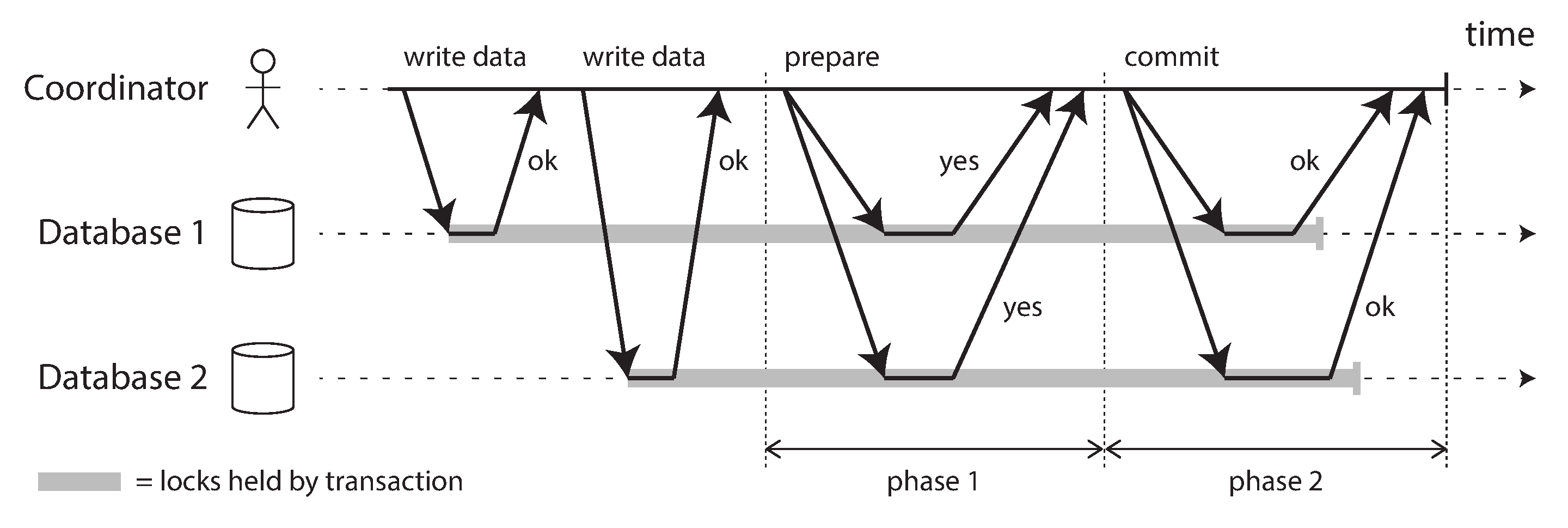
phase1(prepare) 단계는 phase2(commit) 을 치루기 전 마지막 보루 같은 개념이다.
phase1 과정에서 모든 노드에게 yes 사인이 떨어지면 해당 트랜잭션은 반드시 커밋된다.
phase2 과정 도중 특정 노드가 죽더라도 나중에 복구될것이라 믿고 정상 노드들은 commit 요청 을 강행한다.
반대로 phase1 과정에서 no 사인이 떨어지면 모든 참가자에게 phase2 과정에서 abort 요청 을 전송하게 된다.
2PC 는 원자성을 보장하지만 데드락 상황에 빠지기 매우 쉬운 구조이다.
만약 phase2 가 실패할 경우 모든 노드가 복구될때 까지 조정자는 영원히 phase2 를 재시도하게된다.
또한 조정자 장애 발생시 참여자들은 무한 대기상태로 멈춘다.
참여자 노드가 늘어날수록 단일 DB 에 비해 성능차이가 심하게 일어나며, 조정자가 단일장애지점(SPoF)으로 동작하기에 굉장히 제한적인 상황에서 사용한다.
조정자는
트랜잭션 관리자라고도 함
조정자는 일반적으로write 요청하는 어플리케이션 프로세스에서 라이브러리 형태로 구현된다.
XA 트랜잭션
XA 트랜잭션 은 메세지 브로커와 DB같이 이종 서비스간 혹은 샤딩과 같이 물리적으로 분리된 데이터노드의 동작을 하나의 트랜잭션으로 묶어 데이터의 일관성을 보장한다.
표준화된 XA 트랜잭션(eXtended Architecture) 프로토콜 기반으로 동작하는 2PC 방식으로 동작하는 분산 트랜잭션이다.
DB 레이어에서 지원하며 MySQL 의 경우 아래와 같은 XA 트랜잭션 용 명령어를 지원한다.
XA {START|BEGIN} xid [JOIN|RESUME]
XA END xid [SUSPEND [FOR MIGRATE]]
XA PREPARE xid
XA COMMIT xid [ONE PHASE]
XA ROLLBACK xid
XA RECOVER [CONVERT XID]
즉 2개의 별개의 시스템을 2PC 처럼 묶어서 결과적으로 정확히 한번(effectively exactly once) 동작하도록 할 수 있다.
지원하는 브로커와 DB 는 아래와 같다.
- 메세지 브로커
- ActiveMQ
- IBM MQ
- DB
- Oracle
- MySQL
- PostgreSQL
JTA(Java Transaction API), JMS(브로커용 드라이버) 를 사용하여 XA 트랜잭션을 구현할 수 있다.
// ActiveMQ 연결 설정
ConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory("tcp://localhost:61616");
// MySQL XA 데이터 소스 생성
MysqlXADataSource mysqlXADataSource = new MysqlXADataSource();
mysqlXADataSource.setUrl("jdbc:mysql://localhost:3306/test");
mysqlXADataSource.setUser("username");
mysqlXADataSource.setPassword("password");
// ActiveMQ와 MySQL에 대한 XA 연결 생성
// javax.jms.XAConnection
XAConnection activeMQConnection = ((ActiveMQConnectionFactory) activeMQConnectionFactory).createXAConnection();
// javax.sql.XAConnection
XAConnection mysqlXAConnection = mysqlXADataSource.getXAConnection();
...
public void startXaTransaction() {
// ActiveMQ와 MySQL에서 XAResource 가져오기
XAResource activeMQXAResource = activeMQConnection.createXASession().getXAResource();
XAResource mysqlXAResource = mysqlXAConnection.getXAResource();
// XID 생성
byte[] gid = new byte[]{0x01};
byte[] bid = new byte[]{0x02};
Xid xid = new XidImpl(0x1234, gid, bid);
// 트랜잭션 시작
activeMQXAResource.start(xid, XAResource.TMNOFLAGS);
mysqlXAResource.start(xid, XAResource.TMNOFLAGS);
// ActiveMQ에 메시지 전송
Session activeMQSession = activeMQConnection.createSession(true, Session.SESSION_TRANSACTED);
Queue queue = activeMQSession.createQueue("exampleQueue");
MessageProducer producer = activeMQSession.createProducer(queue);
TextMessage message = activeMQSession.createTextMessage("Hello, ActiveMQ!");
producer.send(message);
// MySQL에 데이터 삽입
Connection mysqlConnection = mysqlXAConnection.getConnection();
PreparedStatement preparedStatement = mysqlConnection.prepareStatement("INSERT INTO test_table VALUES (?)");
preparedStatement.setString(1, "Hello, MySQL!");
preparedStatement.executeUpdate();
// 트랜잭션 커밋
activeMQXAResource.prepare(xid);
mysqlXAResource.prepare(xid);
activeMQXAResource.commit(xid, false);
mysqlXAResource.commit(xid, false);
// 리소스 정리
preparedStatement.close();
mysqlConnection.close();
producer.close();
activeMQSession.close();
mysqlXAConnection.close();
activeMQConnection.close();
}
XA 트랜잭션이 유지되는 동안 잠금을 유지하기에 이종 시스템간의 일관성을 유지시킨다.
일관성이 강력한 대신 커밋과정 까지 잠금상태가 유지되어 성능 저하가 발생한다.
Atomikos
https://www.atomikos.com/Main/WebHome
https://www.baeldung.com/java-atomikos
위와같이 java.sql, java.jms 에서 기본적으로 제공하는 트랜잭션 라이브러리를 사용하는것도 좋지만 XA 트랜잭션을 지원하는 오픈소스도 많다.
아래 2개 오픈소스 프로젝트가 XA 트랜잭션을 지원하는것으로 유명하다.
- Atomikos
- Narayana
Automatic Transaction
2PC 방식 기반으로 동작하는 로컬 트랜잭션 을 기반으로 하는 분산 트랜잭션.
여기서
로컬 트랜잭션은 RDB 의 원자적 트랜잭션을 뜻한다.
XA 트랜잭션은 DB 에서 지원해야 하지만 Automatic Transaction 는 Apache Seata 와 같은 분산 트랜잭션 프레임워크가 조정자 역할을 수행한다.
DB 의존성을 벗어나 분산 트랜잭션 을 지원하기 위해 Undo Log 를 사용해 롤백을 수행한다.
- 각 데이터베이스가
로컬 트랜잭션을 수행 - 각
로컬 트랜잭션을 관리하여 전체적으로분산 트랜잭션을 처리 - 트랜잭션이 실패할 경우 (Undo Log)를 사용하여 롤백 작업을 처리하여 데이터의 일관성을 유지
어플리케이션(Apache Seata)에서 전체적인 트랜잭션을 관리할 수 있기 떄문에 다양한 상황에서 원자적으로 동작하는 트랜잭션 수행이 가능하다.
- 하나의 서비스가 여러개의 트랜잭션에 관여
- 여러개의 서비스가 하나의 트랜잭션에 관여
Apache Seata
Seata(Simple Extensible Autonomous Transaction Architecture)
https://seata.apache.org/
https://github.com/apache/incubator-seata
Apache Seata 는 아래 그림과 같이 중재자 서버가 별도로 존재하고 RM(Resource Manager), TM(Transcation Manage) 를 통해 AT 트랜잭션(Begin/Commit/Rollback) 스타일의 트랜잭션을 지원하여 데이터를 관리한다.
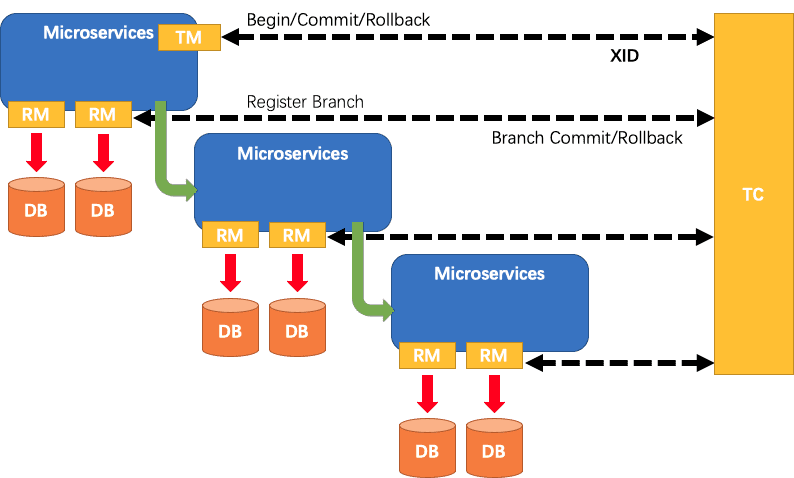
Apache Seata 는 분산 서비스 트랜잭션, 분산 DB 트랜잭션 뿐 아니라 TCC 라는 도메인 데이터의 논리적인 트랜잭션 기능도 지원한다.
TCC(Try-Confirm-Cancel) 는 애플리케이션 레벨에서 트랜잭션을 세분화하여 관리하는 논리적 트랜잭션으로 항공권 예약 시스템과 비슷한하다.
- Try: 좌석을 확보할 수 있는지 확인, 이를 일시적으로 예약(잠금).
- Comfirm: 좌석을 확정되면서 해당 좌석은 최종적으로 구매자가 사용.
- Cancel: 좌석예약이 취소되면 다른 사용자에게 예약될 수 있도록 해제.
해시링
DynamoDB, Cassandra 등의 DB 에서 사용되는 기법
Consistent Hashing 을 구현하기 위한 알고리즘
해시맵 같은 데이터모델에선 moduler 연산을 통해 해시 버킷에 데이터를 저장하는 방식을 사용한다.
서버 인스턴스가 3개일 때 해시와 Moduler Hahsing 을 사용하면 아래와 같이 출력된다.
hash(1) % 3 = 0
hash(2) % 3 = 1
hash(3) % 3 = 2
인스턴스가 4개로 변경되는 순간 모든 값은 뒤섞이게 되고 샤딩값으로 사용하였다면 전체 리벨런싱을 수행해야한다.
해시링은 인스턴스 수가 변경되어도 일부만 리벨런싱 하는방식의 Consistent Hashing 알고리즘이다.
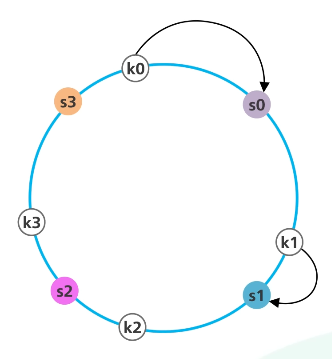
해시링에선 moduler 연산을 사용하지 않고 데이터의 배치를 해시값을 통해 수행하고 링에 배치된 서버를 탐색하는 방식을 사용한다.
- 서버와 키를 균등 분포 해시 함수를 사용해 해시 링에 배치한다.
- 시계 방향으로 탐색하다 만나는 최초의 서버가 키가 저장될 서버다.
서버가 추가/삭제 되는 과정에서 서버의 균등한 위치는 깨진다.
이를 해결하기 위해 한대의 서버의 파티션을 여러개로 쪼개 해시링에 배치하는 가상노드 기법을 사용한다.
가상노드 기법을 복제 기법이라 부르기도함
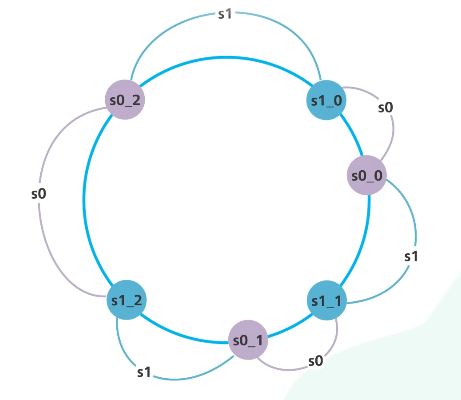
서버의 replica(가상노드) 들을 설치할 때 최대한 해시링에 균등하게 배치되도록 파티션을 쪼개 가상노드들로 구성한다.
데이터 일관성
각 노드에 배치된 데이터들은 내부 네트워크를 통해 적절히 동기화된다.
어플리케이션이 Read, Write 를 진행할 때 해당 데이터가 일관성이 있는지 판단하기 위해 정족수 합의(Quorum Consensus) 프로토콜 을 사용한다.
정족수: 합의에 필요한 최소 인원수
N=노드 개수 W=쓰기 정족수 R=읽기 정족수
일반적으로 N=3 정도를 주로 사용하며 W, R 의 개수에 따라 쓰기속도, 읽기속도, 일관성정도 를 조절할 수 있다.
R=1, W=N: 빠른 읽기W=1, R=N: 빠른 쓰기W + R > N: 강한 일관성(W=R=2)
N=3 일 때, 2개 이상의 노드로부터 쓰기, 읽기 요청을 검증함으로 최신데이터를 항상 확인할 수 있다.W + R < N: 약한 일관성
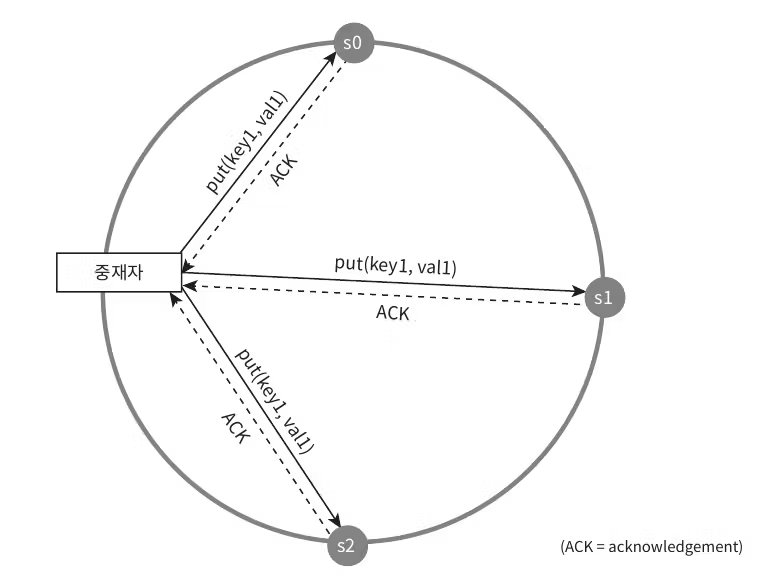
모든 요청은 중재자를 통해 이루어지며 정족수에 따라 쓰기속도, 읽기속도가 달라지지만, 최종적으로는 모든 노드가 동기화를 통해 동일한 데이터를 가지게 된다.
머클트리
https://medium.com/coinmonks/merkle-trees-concepts-and-use-cases-5da873702318
반-엔트로피(anti-entropy) 프로토콜 기법을 사용하여 노드간 데이터의 동기화를 진행한다.
해시 함수를 사용하는 머클 트리(Merkle Tree) 를 사용해 두 노드간 데이터 동기화가 되어있는지 확인할 수 있다.
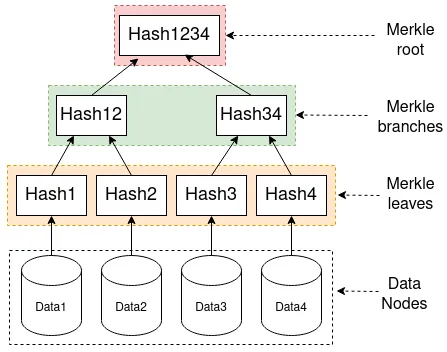
해시 트리(hash tree) 라 불리기도 함.
각 노드의 머클 트리 의 루트를 비교해 데이터의 동기화 여부를 확인할 수 있다.
일반적으로 Merkle leaves(버킷) 가 관리하는 데이터 개수는 1000개 정도,
100만개의 해시값으로 10억개의 데이터를 관리하게 된다.
Redis & DB 일관성 유지
데이터의 빠른 반환 및 DB 의 부하를 줄이기 위해 DB 에서 읽은 데이터를 일정시간동안 Redis 에 저장해두었다 반환하는 역할을 수행한다.
읽기의 경우 항상 Redis 에서 읽고 없으면 DB 에서 읽은 후 업데이트하는 구조로 운영된다.
문제는 INSERT, UPDATE 같은 쓰기작업을 수행했을 때 Redis 와 DB 의 업데이트를 원자적으로 처리할 수 있어야 하는데, 둘중 하나가 실패할 경우 일관성 문제가 발생한다.
Redis 와 DB 에 데이터를 쓰는 방식은 대략 아래 3가지
- Cache-Aside 패턴
- DB 저장 후 Redis 저장
- Write-Through 캐시
- Redis 저장 후 DB 저장
- Write-Behine 캐시
- Redis 저장 후 비동기적으로 DB 저장
- 스케줄링 혹은 Pub/Sub 사용하여 DB 저장
Redis 에 장애가 발생해도 데이터 유실이 없거나 정상동작 가능한 Cache-Aside 패턴을 주로 사용한다.
Cache-Aside 패턴의 경우 Redis 에 데이터가 한번 이상 저장된 이후에는 Redis의 최신성을 보장하지 않는다.
대부분 수행하는 요청이 읽기 요청이고 Redis 의 최신성을 유지해야할 경우 Redis 에 데이터를 먼저 저장하는 Write-Through 캐시 를 사용하고, 일관성을 위해 2PC 을 사용할 수 있다.
- Redis 에 데이터를 임시속성과 함께 저장
- DB 에 데이터 저장
- DB 저장 성공시 Redis 의 임시속성을 제거
읽기요청시 임시속성을 확인하고 2PC 가 완료되었는지 최신화 여부를 확인할 수 있다.
쓰기요청시 2PC 과정을 거치기에 부하가 발생하지만 읽기요청이 많은 서비스의 경우 효과적이다.