합의알고리즘!
합의 알고리즘
다양한 합의 알고리즘(Consensus Algorithm) 을 사용해 사용자의 선형성 원자적 연산 구현하고, 노드간 원자적 연산(compare and set) 을 지원한다.
합의알고리즘은 데이터 복제, 상태 동기화 를 필요로하는 서비스들이 사용한다.
Zookeeper, etcd 모두 분산 시스템 환경에서 중요한 역할을 하는 분산 key-value 저장소이다.
일반적인 key-value 저장소가 아닌 분산 시스템에서 요구로 하는 구성 관리, 서비스 디스커버리, 분산 잠금, 리더 선출등에 사용되는 중요한 데이터를 다루는 저장소이다.
합의 알고리즘 을 통해 값의 안정성과 일관성을 관리한다.
Hadoop, HBase, Kafka, Kubernetes 등 분산 데이터 처리 시스템의 코디네이션에 위와같은 서비스가 사용되는 이유가 합의 알고리즘 때문이다.
대표적인 합의 알고리즘 은 아래와 같다.
- Zab 합의 알고리즘
- Raft 합의 알고리즘
Raft
Raft: 뗏목, 로그를 묶어놓는다는 의미에서 유래
https://raft.github.io/
https://raft.github.io/raft.pdf
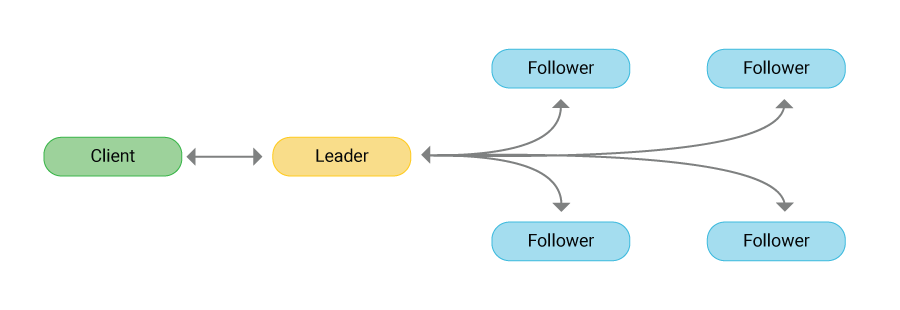
Raft 클러스터에서 모든 노드는 아래의 세 가지 중 하나의 상태를 가진다.
- 리더: 유일하게 클라이언트와 1:1 통신, 명령 처리 및 전파를 수행한다. heartbeat를 주기적으로 팔로워들에게 송신.
- 팔로워: 리더를 제외한 나머지 노드, 리더로부터 전달받은 명령을 처리한다.
- 후보자: heartbeat를 일정 주기로 받지 못한 팔로워는 리더가 존재하지 않는다고 판단하고 후보자가 된다.
Raft 클러스터에서 명령 수행과정은 아래와 같다.
명령은 log 포맷으로 전파된다.
- 로그추가: 리더는 수신받은 명령을 log 로 생성한다.
- 로그복제: 리더는
AppendEntries명령을 통해 log 를 모든 팔로워에게 전달한다. - 응답처리: 팔로워는 log 에 대한 처리 및 응답, 팔로워의 응답이 과반수를 넘었을 때 log 는 성공했다 커밋 후 클라이언트에게 명령의 수행결과를 응답한다.
- 일관성보장: log 를 정상적으로 처리하지 못한 팔로워에게 지속적으로 복제한다.
AppendEntries 의 의사코드는 아래와 같다.
AppendEntries(term,leaderId,prevLogIndex,prevLogTerm,entries[],leaderCommit)
// term 현재 Term 번호
// leaderId 리더의 ID
// prevLogIndex 이전 로그 항목의 인덱스
// prevLogTerm 이전 로그 항목의 Term
// entries 복제할 로그 항목들
// leaderCommit 리더가 커밋한 마지막 로그 항목의 인덱스
Term 은 Raft 클러스터에서 리더 선출과 로그 복제를 위한 주기적인 시간 단위,
리더가 선출되어 활동하는 기간, 새로운 리더가 선출될 때마다 Term 이 증가한다.
Raft 리더선출
Raft 클러스터에서 리더선출(Leader Election) 과정은 아래와 같다.
- 후보자 전환: 리더 노드의 타임아웃이 발생한 팔로워 노드는 자신을 후보자로 전환.
- 투표요청: 후보자는
Term값을 증가시키고 자신에게 투표한 후RequestVote를 브로드캐스트. - 투표결정:
RequestVote를 받은 팔로워는 후보자의 최신화 여부를 확인하고 먼저 보낸 후보자에게 투표.- 후보자의 마지막 로그 항목의
Term이 팔로워의 마지막 로그 항목의Term보다 크거나 동일할 경우 투표. - 후보의 마지막 로그 항목의 인덱스가 더 크면 투표.
- 후보자의 마지막 로그 항목의
- 리더선출: 과반수의 팔로워로부터 투표를 받은 후보자가 리더로 승격.
- 리더선출 과정에서 각 노드는
T_v라는 타임아웃 시간을 가지며 이 타임아웃이 만료되면 노드는 후보 상태로 전환.T_v는 노드마다 랜덤하게 설정됨. - 과반수를 얻지 못하고 시간초과될 경우
Term을 증가시키고 재선거 진행.
- 리더선출 과정에서 각 노드는
RequestVote(term,candidateId,lastLogIndex,lastLogTerm)
// term 후보자의 Term 번호
// candidateId 후보자의 ID
// lastLogIndex 후보자의 마지막 로그 인덱스
// lastLogTerm 후보자의 마지막 로그 Term 번호
Zab
원자적 브로드캐스트를 지원하는 Zab(ZooKeeper Atomic Broadcast) 합의 알고리즘에 대해 알아본다.
원자적 브로드캐스트는
전체순서 브로드케스트(total order broadcast)라 부르기도 함
원자적 브로드캐스트는 일반적인 브로드캐스트 개념에서 아래와 같은 추가사항을 요구한다.
- 신뢰성 있는 전달
- 모든 노드에 메세지가 전달되어야 함.
- 네트워크 지연이 발생해도 모든 노드에 메세지가 전달되기 위한 재시도 방법.
- 전체 순서가 정해진 전달
- 모든 메세지는 모든 노드에 같은 순서로 전달된다.
- 전달받은 메세지의 수신과 정확한 순서를 확인하는 방법.
- 원자적 커밋
- 부분적인 전달을 허용하지 않음.
- 모든 노드가 메시지를 받고 성공하거나 모든 노드가 실패하는 것을 보장합니다.
Zab 을 사용하는 Zookeeper 클러스터는 아래와 같은 구조로 구성되며 주키퍼 앙상블(Zookeeper Ensemble) 구조라 부른다.
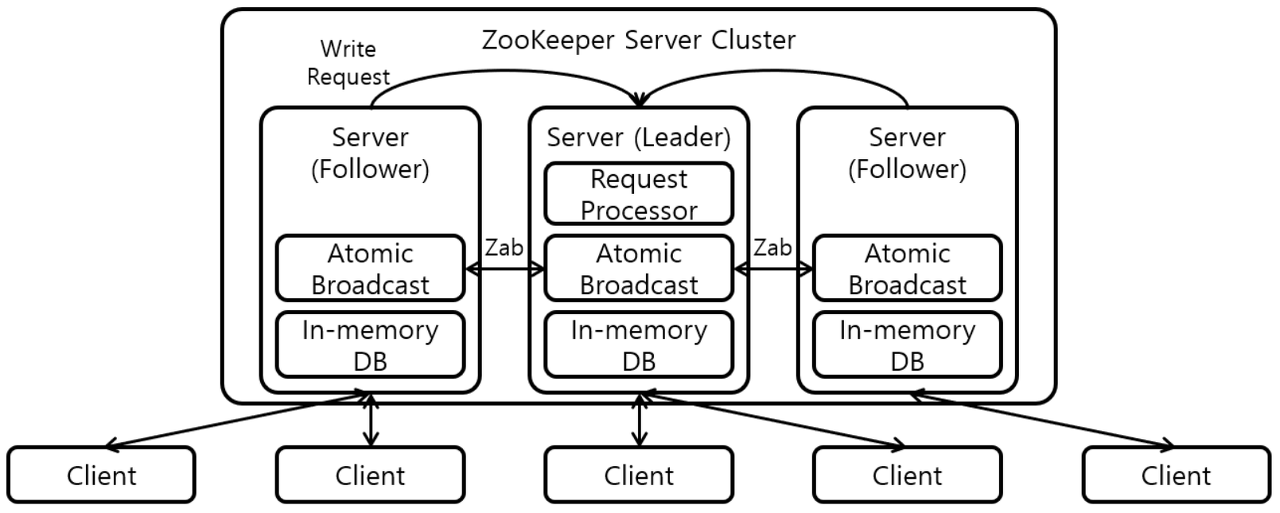
아래 3가지 상태를 통해 클러스터가 운영된다.
- LEADING: 리더 상태
- FOLLOWING: 팔로우 상태
- LOOKING: 후보자 상태
Zab 에서 지원하는 원자적 브로드캐스트 과정은 아래 3가지 단계로 구성된다.
- Leader-Propose
- 클라이언트로부터 요청을
proposal로 변환, 팔로워 노드들에게 브로드캐스트합니다.
- 클라이언트로부터 요청을
- Follower-Accept
- 팔로워 노드들은
proposal을 accept 및 ACK 메시지를 반환.
- 팔로워 노드들은
- Leader-Commit
- 리더는 팔로워로부터 과반수 이상의 ACK를 받으면 해당
proposal을 커밋. - 커밋
proposal을 모든 팔로워에게 브로드캐스트하여 일관성을 유지. - 커밋
proposal은 변경할 수 없다.
- 리더는 팔로워로부터 과반수 이상의 ACK를 받으면 해당
proposal 은 아래와 같은 구조로 이루어진다.
Proposal {
zxid: 0x2000000010, // 64-bit ZXID (Epoch 2, Transaction 16)
session_id: 0x1234567890ABC, // Session ID (Client Session)
type: "CREATE", // Proposal Type (CREATE Node)
data: "/path/to/znode", // Proposal Data (Znode Path)
}
- zxid (Zookeeper Transaction ID)
- proposal의 고유 식별자, 64비트 순서있는 숫자값.
- 상위 32비트는 특정 리더의 임기 라운드(epoch).
- 하위 32비트는 트랜잭션 번호로 순차증가 인덱스.
- Transaction Type
- 트랜잭션 타입
- Transaction Data
- 요청에 대한 실제 작업 데이터
- 노드의 생성, 삭제, 데이터 변경 요청
- Session ID (세션 ID)
- 클라이언트와의 세션을 식별하는 고유한 ID
Zab 리더선출
리더와 팔로워는 주기적으로 heartbeat 메세지를 주고 받으며 타임아웃 기반으로 장애를 탐지한다.
리더의 장애를 탐지한 팔로워들은 LOOKING 상태로 전환하여 리더선출을 시작한다.
- 초기상태
- 최조 서버시작, 리더의 장애 발생으로 인해 리더를 선출하기 위한 상태
- 모든 노드가 팔로잉 상태
- 선거단계
- 리더 장애 탐지 후 LOOKING 상태로 전환
- 다른 노드들에게 리더선출 proposal 을 전달
- proposal 에는 가작 마지만 zxid 를 전달함
- 투표집계
- 각 노드들은 리더선출 proposal 을 수신받은 뒤 가장 최신의 zxid 를 가진 노드에게 투표
- zxid 가 동일하다면 서버 ID 를 기준으로 우선시함
- 리더선출
- 과반수 투표를 흭득한 노드가 리더로 선출됨
- 동기화
- 새로운 리더는 다른 노드들에게 자신의 리더 상태를 알리고 동기화 시작
- 팔로워들의 로그값을 비교 후 동기화되도록 로그를 재전송
- 동기화가 종료되면 클라이언트와 다시 연결되어 작업을 시작함