단위 테스트!
단위 테스트
단순 Test Framework, Mocking Library 사용법을 배우는 것도 중요하지만
테스트 코드와 제품코드간의 적절한 비율을 통해 최대한의 이득을 꾀하는 것이 중요하다.
테스트 코드는 적을수록 좋으며 대부분 테스트 코드와 제품코드의 비율을 1:1 ~ 1:3 정도 수준이다.
잘못된 테스트 코드를 작성하면 오히러 제품 코드에 진척에 악영향을 끼치고 최종에 가선 삭제된다.
고품질 테스트 코드, 가치있는 테스트 코드로 Test suit 를 만드는 방법을 알아야 한다.
단위 테스트를 작성하면서 목표해야할 3가지 조건은 아래와 같다.
- 테스트를 개발주기에 통합
- 제품코드의 가장 중요한 부분만을 테스트 대상으로
- 최소한의 테스트 코드로 최대의 가치
고전파 런던파
단위 테스트는 아래 3가지 의미로 나눌 수 있다.
- 코드조각(단위)를 검증
- 빠르게 수행
- 격리된 방식으로 처리
테스트할 대상을 SUT(System Under Test) 라 부르고 SUT 가 의존하는 의존객체들을 협력자라 부른다.
대부분의 SUT 클래스는 다른 객체를 의존성 주입받거나 상속하는 경우가 많아 대부분 한개 이상의 협력자를 가진다.
테스트간 영향을 끼치는 협력자를 격리하는 방식에 따라 고전파와 런던파로 나뉜다.
고전파, 런던파 모두 SUT 간 영향을 끼치지 않도록 격리시키는것에 중점을 가한다.
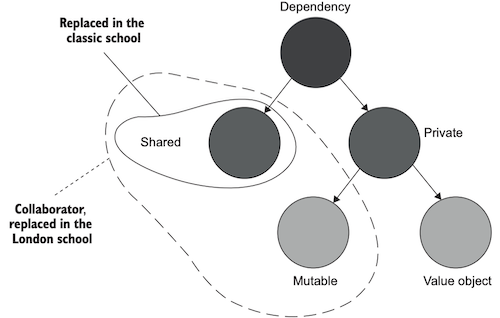
공유 의존성(shared dependency)
[외부 API, Database, FileSystem, Environment]등을 사용하는 의존객체,
대표적인 협력자가 공유 의존성 객체들임.
고전파는 공유 의존성에 대해 mock(대역)객체를 사용 하고 그 외의 다른 협력자들은 직접 준비한다.
런던파는 공유 의존성을 포함한 모든 협력자에 대해 mock 객체를 사용한다.
고전파 중에서도 일부 안정적인 속도와 일관된 값을 반환하는 공유 의존성은 그대로 사용하기도 함,
런던파는 좀 과한면이 있어 mock 추종자라는 말로 불리기도 함.
TDD 관점에서 고전파와 런던파를 바라보면 개발하는 방식도 다르다.
런던파는 시스템의 출력을 설정하는 상위 레벨 테스트부터 제품코드와 테스트코드가 만들어지는 하향식 TDD.
고전파는 실제 협력자를 구현해야 하기에 하위 레벨 테스트부터 제품코드와 테스트코드가 만들어지는 상향식 TDD.
복잡한 클래스 구성도의 경우 협럭자를 모두 구현해야 하는 고전파 테스트코드가 더 복잡하기에 런던파가 더 발전된 방법으로 느껴질 수 있으나
복잡한 클래스 구성 자체가 객체지향 설계미스임으로 두 분파중 어떤 테스트 방식이 더 우월한지 우위를 겨룰순 없다.
대부분의 테스트 코드들은 고전파 방식으로 개발되고 있다.
협력자 클래스의 구성과 객체화를 최대한 간단하게 설계하고, 테스트에서 쉽게 생성, 구현될 수 있도록한다.
공유 의존성만 대체해도 테스트의 빠른 속도를 유지하고 어느정도 리펙터링 내성도 가질 수 있다.
의존성
테스트시 SUT 제품코드의 협력자들을 사용해야할 때, 협력자들 간의 침범으로 테스트간 격리가 실패할 수 있다.
테스트 단계에서 협력자들이 어떤 의존성을 가지는지 파악하고, 테스트간 격리조건을 세우는 전략이 필요하다.
공유 의존성(shared dependency)
테스트간 공유되어 테스트간 결과에 영향을 미칠수 있는 의존객체. static field 가 대표적이다.
사실상 공유 의존성이 가장 포괄적인 용어로 아래에서 설명한 모든 의존성(dependency) 을 포함한다.
프로세스 외부 의존성(out of process dependency)
테스트 프로세스 외부에서 state 값을 가지는 의존성
[외부 API, Database, FileSystem, Environment] 가 대표적인 예
비공개 의존성(private dependency)
의존객체이지만 다른 객체들과 공유하지 않을경우, 제품코드에선 싱글턴으로 동작하지만 테스트 단계에선 새로운 인스턴스가 생성되는 의존성.
휘발성 의존성(volatile dependency)
비결정적 동작(난수, 날짜)를 발생시키는 의존성을 뜻한다.
테스트시 컨테이너로 운영되는 DB 또한 테스트 실행마다 반환값이 달라질 수 있음으로 휘발성 의존성에 속한다.
AAA 패턴
단위테스트는 아래 3가지 단계로 나눌 수 있다.
- 준비과정 Arrange
- 실행과정 Act
- 검증과정 Assert
Test suit 의 일관된 패턴 사용함으로서 유지보수가 편해진다.
@Test
void Test() {
// 준비
double first = 10l;
double second = 20l;
Calculator calculator = new Calculator();
// 실행
double result = calculator.sum(first, second);
// 검증
assertEquals(30, result);
}
준비과정: SUT 와 협력자 준비 과정
AAA 패턴에서 준비과정이 가장 많은 코드라인을 차지한다.
테스트용 협력자를 준비하는 과정의 코드 재사용성을 높이기 위해 Test Fixture[Object Mother, Test Data Builder] 를 테스트 클래스 내부에 준비해두는 것을 권장한다.
Test Fixture란 SUT 로 전달되는 고정된 인수값이다.
DB, 파일시스템 내부의 데이터일 수 있고 각 테스트 실행전에 고정된 값을 유지하고 있어야 한다.
독립된 Test Fixture 가 있으면 준비과정을 좀더 짧게 설정 가능하다.
@Test
void purchase_succeed_when_enough_inventory() {
// 준비
Store store = createStoreWithInventory(Product.Shampoo, 10);
Customer sut = createCustomer();
// 실행
boolean result = sut.purchase(store, Product.Shampoo, 5);
// 검증
assertTrue(result); // 결과
assertEquals(5, store.getInventory(Product.Shampoo)); // 협력자
}
@Test
void purchase_failed_when_not_enough_inventory() {
// 준비
Store store = createStoreWithInventory(Product.Shampoo, 10);
Customer sut = createCustomer();
// 실행
boolean result = sut.purchase(store, Product.Shampoo, 15);
// 검증
assertFalse(result); // 결과
assertEquals(10, store.getInventory(Product.Shampoo)); // 협력자
}
private Store createStoreWithInventory(Product product, int quantity) {
Store store = new Store();
store.addInventory(product, quantity);
return store;
}
private Customer createCustomer() {
return new Customer();
}
실행과정: SUT 메서드 호출 과정
테스트할 SUT 를 생성, 협력자 전달 및 메서드를 호출한다.
실행과정의 코드가 한줄보다 많다면 SUT 설계에 문제가 있다는 신호이다.
제품코드의 캡슐화, 은닉성 구조에 문제가 있는 것이니 고쳐야한다.
검증과정: SUT 의 협력자 상태, 출력값을 검증하는 과정
검증과정 또한 코드 수가 작을수록 좋다.
만약 SUT 의 많은 속성을 검증해야 한다면 동등멤버(equality member) 를 정의하고 검증하는 것이 좋다.
테스트 정밀도
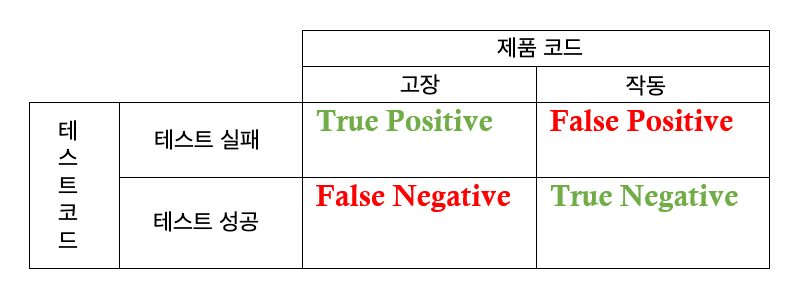
- True Positive: 테스트 코드, 제품코드 모두 오류
- False Negative: 테스트 코드는 정상, 제품코드는 오류
- False Positive: 테스트 코드는 오류, 제품코드는 정상
- True Negative: 테스트 코드, 제품코드 모두 정상
여기서 우리가 허용할 수 있는건 [True Positive, True Negative] 뿐이다.
그 외의 [False Negative, False Positive] 상황이 발생하면 좋은 단위 테스트가 아니라 할 수 있다.
특히 False Negative 는 실제 운용에 오류를 발생시킬 수 있음으로 False Positive 보다 훨씬 중요한다.
테스트는 실패했는데 운영코드가 작동하면 테스트 신뢰성이 떨어지고,
테스트는 성공했는데 운영코드가 실패하면 서비스 운영장애로 이어질 수 있다.
그런 의미에서 정밀도(Precision) 공식을 사용하여 Test Suit 를 작성해 나가야 한다.
테스트 명명법
간단한 영어 제목으로 언더바를 함께 사용하는것을 권장한다.
@Test
void sum_of_two_number() {
// 준비
double first = 10l;
double second = 20l;
Calculator calculator = new Calculator();
// 실행
double result = calculator.sum(first, second);
// 검증
assertEquals(30, result);
}
Parameterized Tests
위의 customer(SUT) 테스트는 2가지의 비슷한 역할을 수행하는 테스트 코드이다.
매개변수로 값을 조금만 설정하면 하나로 합칠 수 있을 것 같다.
Parameterized Tests 로 하나로 합칠 수 있다.
@ParameterizedTest
@CsvSource(value = {
"5,true,5",
"15,false,10"
})
void purchase_detect_enough_inventory(int quantity, boolean expected, int expectedQuantity) {
// 준비
Store store = createStoreWithInventory(Product.Shampoo, 10);
Customer sut = createCustomer();
// 실행
boolean result = sut.purchase(store, Product.Shampoo, quantity);
// 검증
assertEquals(expected, result);
assertEquals(expectedQuantity, store.getInventory(Product.Shampoo));
}
Parameterized Tests 는 테스트코드를 압축하지만 압축된 만큼 테스트 코드의 직관성이 떨어진다.
매개변수로 삽입할 값을 관리하는 것도 비용으로 취급된다.
테스트용 파라미터가 객체타입이라면 아래와 같이 ArgumentsProvider 사용
public static class DeliveryArguments implements ArgumentsProvider {
@Override
public Stream<? extends Arguments> provideArguments(ExtensionContext context) throws Exception {
return Stream.of(
Arguments.of(LocalDateTime.now().plusDays(-1), false),
Arguments.of(LocalDateTime.now(), false),
Arguments.of(LocalDateTime.now().plusDays(1), false),
Arguments.of(LocalDateTime.now().plusDays(2), true)
Arguments.of(LocalDateTime.now().plusDays(3), true)
);
}
}
@ParameterizedTest
@ArgumentsSource(DeliveryArguments.class)
void can_detect_an_invalid_delivery_date(LocalDateTime deliveryDate, boolean expected) {
DeliveryService sut = new DeliveryService();
Delivery delivery = new Delivery(deliveryDate);
boolean isValid = sut.isDeliveryValid(delivery); // delivery 가 2일 후이면 true
assertEquals(expected, isValid);
}
좋은 단위 테스트의 4대 요소
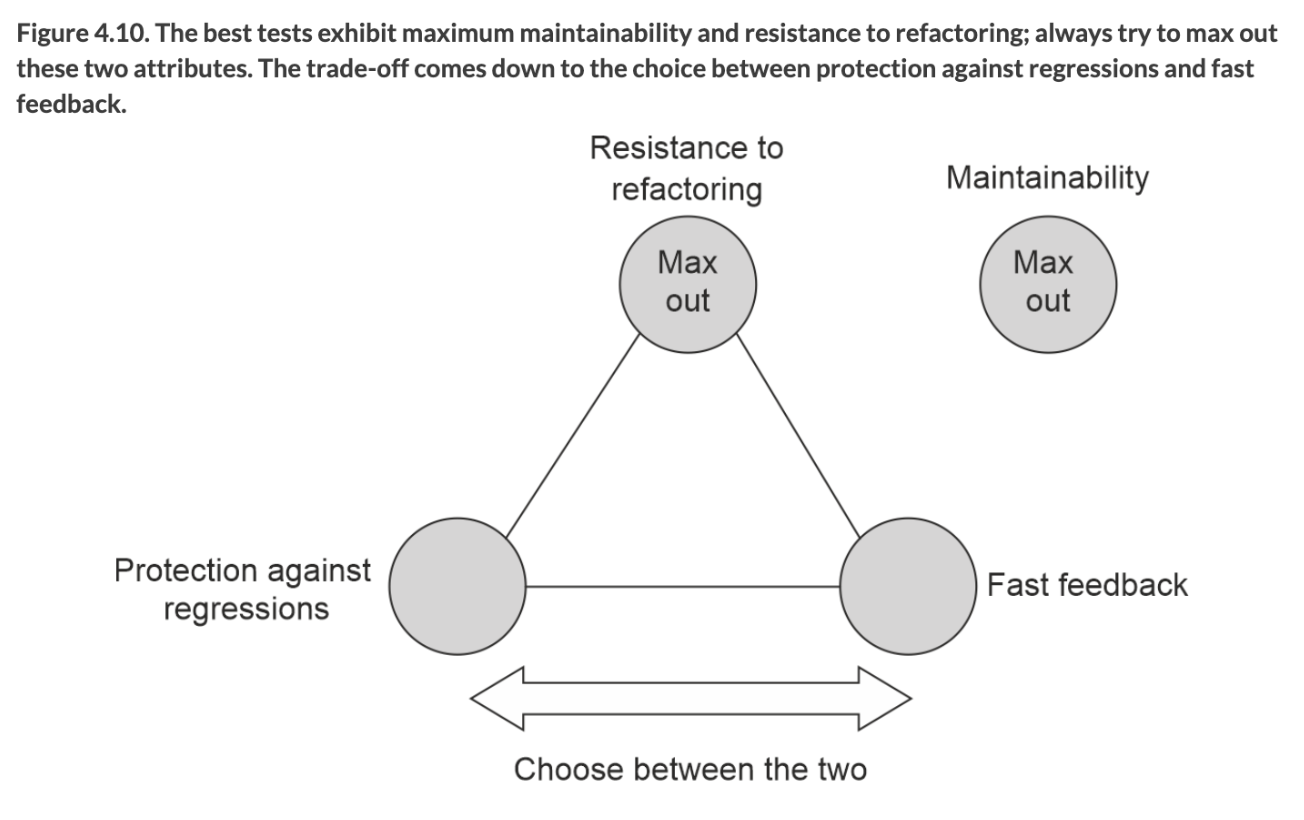
- 회귀방지(protection against regression)
- 리팩터링 내성(resistance to refactoring)
- 빠른 피드백(fast feedback)
- 유지보수성(maintainability)
위 4가지 요소를 모두 만족하는 이상적인 테스트를 만들 수 있으면 좋겠지만
유지보수성을 제외한 각 요소는 서로 베타적인 관계로 어느 한쪽을 포기해야 나머지를 취득할 수 있는 구조이다.
회귀방지(False Negative)
여기서서 회귀 는 이전에 정상 작동하던 코드가 특정 사건 후에 의도한 대로 작동하지 않는 경우를 뜻한다.
테스트에서 회귀 는 테스트 코드는 정상동작 하더라도 제품코드가 비정상인
False Negative상황을 뜻한다.
코드가 지속적으로 수정되고 늘어나면서 기능이 의도대로 작동하지 않는, 많은 회귀상황이 발생할 수 있다.
회귀방지 를 잘 하라면 테스트 코드에서 검증하는 제품코드의 코드라인 수가 많아야 한다.
본인이 작성한 코드 외에 외부 라이브러리의 동작 또한 면밀히 검토해야 한다.
실제 테스트 코드를 실행시키지 않는 (mock + 캡슐화) 가 회귀 를 발생할 수 있다.
리펙터링 내성(False Positive)
제품코드 리팩터링 후 테스트 코드에 에러가 발생할 수 있다, 그렇다 하더라도 제품코드는 정상동작할 수 있는 False Positive 상황이 발생할 수 있다.
False Positive 은 테스트 코드의 타당성, 신뢰성을 저하시키고 테스트를 포기하고 운영환경에 진입하게 만든다.
처음부터 False Positive 가 발생하지 않는 리펙터링 내성이 강한 테스트 코드를 작성하는 것이 중요하다.
구현 세부사항과 테스트 코드를 분리하여 결합도를 낮추면 리펙터링 내성을 키울 수 있다.
아래 좌측 그림과 같이 모든 SUT 의 과정를 검사하지 않고 마지막 결과만을 검사하는 등의 방식을 사용할 수 있다.
공개API(public) 과 비공개API(private) 을 철저하게 나눠 테스트 코드에 제품 코드가 강결합되는 것을 피하는 것이 좋다.
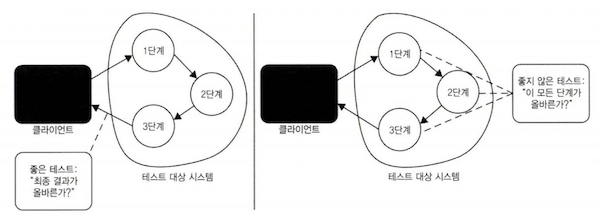
좌측 그림처럼 SUT 의 공개API(큰원)의 입출력값만 검증하고, 내부의 비공개API(작은원) 은 검증하지 않는다.
어뎁터 패턴같이 추상화를 사용하면 자연스럽게 내부 상세 구현에 대해서 은닉됨으로 리팩터링 내성을 키울 수 있다.
리펙터링 내성은 초기에는 회귀방지 보단 중요하지 않지만
제품코드의 코드베이스가 증가하면서 리펙터링은 자주 발생하기 때문에 리펙터링 내성 중요도 또한 Test suite 에서 증가한다.
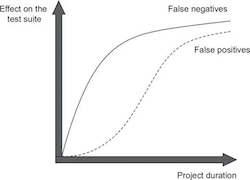
단위테스트는 직접 검증할 코드를 실행시키다 보니 리펙터링 내성이 떨어진다.
반면 통합테스트는 높은 리펙터링 내성을 갖는다.
어쨋든 단위테스트, 통합테스트 모두 높은 리펙터링 내성을 갖도록 코드의 캡슐화 은닉성을 설계하는 것이 제일 중요하다.
빠른 피드백
수행하는 시간이 오래걸리는 테스트는 코드의 오류수정 비용에 그만큼의 시간을 추가시킨다 보면 된다.
또한 높은 비용때문에 개발자에게 많은 부담을 느끼게 한다.
공유 의존성을 모두 Mock 객체로 돌리고 테스트에서 실행하는 제품코드의 코드라인 수를 줄여서 빠른 피드백을 얻을 수 있다.
또한 Mock 객체를 사용하는 점에서 리펙터링 내성과 높은 친밀도를 가진다.
결론
모든 조건을 만족하는 테스트를 작성할 순 없다.
캡슐화가 되어있을 수록 Mock 객체를 사용하게 되고, 실행시키는 제품코드수가 줄어들기에 회귀방지와 리펙터링 내성은 적대적 관계이다.
회귀방지는 캡슐화가 안되있을 수록 테스트에서 좋은 결과를 출력하고,
리펙터링 내성은 캡술화가 되있을 수록 테스트에서 좋은 결과를 출력한다.
하지만 객체지향 특성상 캡슐화를 포기하는건 말이 안되는 일.
리펙터링 내성은 항상 최대로 가져가고 회귀방지와 빠른 피드백을 조절하여 테스트의 비교대상에 넣는다.
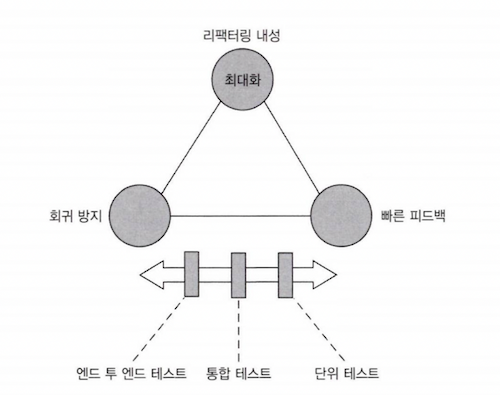
회귀방지 에 기준을 둔다면 협력자를 Mock 객체로 대체하지 않고 실제 제품코드가 모두 동작되도록 준비하면 된다.
대신 실제 돌리는 코드 라인 수가 많다보니 빠른 피드백 은 포기해야한다.
빠른 피드백 위해선 공유 의존성을 Mock 객체로 대체하고 실제 동작시키는 코드라인 수를 줄어야 한다.
최대한 많은 코드를 실행시켜야 하는 회귀 방지는 포기해야 한다.
둘중 어느한쪽을 고를 순 없다보니 협력자의 개수에 따라 테스트의 종류를 나눠 각각 테스트하는 경우가 많다.
회귀방지: 통합 테스트, 협력자가 많다면 통합테스트빠른 피드백: 단위 테스트, 협력자가 몇개 안된다면 단위테스트
단위테스트 3가지 스타일
- 출력기반 테스트(output based testing)
- 상태기반 테스트(state based testing)
- 통신기반 테스트(communication based testing)
출력기반 테스트
SUT 에 입력을 넣으면 생성되는 출력을 테스트
SUT 가 변하지 않고 반환값만 검증하면 될 때 사용한다.
출력기반 테스트 스타일은 DB에 값을 저장한다던지 등의 사이드 이펙트가 없는 코드를 테스트 할 때 사용하는 스타일로, 함수형 프로그래밍 방식에 뿌리를 두고있다.
함수형 프로그래밍을 사용하면 출력기반 테스트를 사용할 수 있고, 제품코드에서도 간단 명료하게 [입출력값 제어, 에러 헨들링] 이 가능하고 그만큼 테스트 코드 작성도 편해진다.
함수형 프로그래밍의 장점은 Mock 객체가 필요 없고 입력값과 출력값만 검증하면 되기 때문에
[회귀방지, 리펙터링 내성, 빠른 피드백] 모든 이점을 갖는다.
함수형 프로그래밍을 사용하려면 공유 의존성을 제거해야 한다.
public class OutputBasedTests {
public static class PriceEngine {
public double calculatingDiscount(Product[] products) {
double discount = products.length * 0.01;
return Math.min(discount, 0.2);
}
}
@Test
void discount_of_two_product() {
Product p1 = new Product("shampoo");
Product p2 = new Product("book");
PriceEngine sut = new PriceEngine();
double discount = sut.calculatingDiscount(new Product[]{p1, p2});
Assertions.assertEquals(0.02, discount);
}
}
하지만 객체지향 특성상 공유 의존성을 없애는것이 쉽지많은 않다.
오히려 함수형 프로그래밍로 개발하면서 더 많은 유지보수가 발생할 수 도 있다.
그리고 객체를 분리하는 과정에서 더 많은 함수호출과 코드가 추가되고 성능하락으로 이어질 수 있다.
상태기반 테스트
상태기반 테스트는 작업이 완료된 후 [SUT, 협력자, DB, 외부API] 등의 상태를 확인한다.
public class StateBasedTests {
@Getter
public static class Order {
private List<Product> products = new ArrayList<>();
public void addProduct(Product productEnum) {
products.add(productEnum);
}
}
@Test
void adding_a_product_to_an_order() {
Product product = new Product("Hand wash");
Order sut = new Order();
sut.addProduct(product);
Assertions.assertEquals(1, sut.getProducts().size());
Assertions.assertEquals(product, sut.getProducts().get(0));
}
}
통신기반 테스트
@ExtendWith(MockitoExtension.class)
public class CommunicationBasedTests {
@Test
void sending_a_greeting_mail() {
IEmailGateway iEmailGateway = Mockito.mock(IEmailGateway.class);
UserService service = Mockito.mock(UserService.class);
Mockito.when(iEmailGateway.sendGreetingEmail("kgy1996@naver.com")).thenReturn(true);
UserController controller = new UserController(service, iEmailGateway);
boolean result = controller.greetUser("kgy1996@naver.com");
Mockito.verify(iEmailGateway, Mockito.times(1))
.sendGreetingEmail("kgy1996@naver.com");
Assertions.assertTrue(true);
}
}
테스트 개선
테스트 개선은 제품코드의 리팩터링으로부터 이루어진다.
리펙터링 방향을 정하려면 코드를 아래 2가지 수치를 이해하고 있어야 한다.
- 복잡도 & 도메인 유의성
복잡도(code complexity): 함수 내 분기점(조건문) 수.도메인 유의성(domain significance): 프로젝트와 도메인의 연관성.
- 협력자 수
협력자 수 는 말 그대로 해당 클래스, 메서드가 가지는 협력자 수이다.
도메인 코드들은 사용자의 목표와 직접적인 연관이 있기 때문에 복잡도 & 도메인 유의성 이 모두 높을 가능성이 많다.
유틸리티 코드들은 이러한 연관성이 없어 복잡도만 높을 가능성이 많다.
두 수치에 따라 4가지 코드 유형으로 분류할 수 있다.
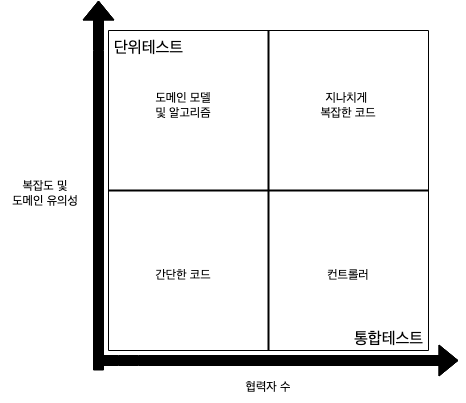
제품코드의 복잡도 가 높다면 테스트할만한 코드이다.
제품코드의 복잡도 & 도메인 유의성 이 높다면 반드시 테스트해야할 코드이다.
협력자 수가 높은 코드는 테스트 하기 어렵지만 해야하는 코드이다.
도메인 모델 및 알고리즘,컨트롤러에 해당하는 코드는 반드시 테스트해야한다.간단한 코드는 테스트할 필요없다.지나치게 복잡한 코드는 코드 설계가 잘못된 것임으로도메인 모델 및 알고리즘,컨트롤러둘중 하나에 포함되도록 수정해야 한다.
도메인 모델 및 알고리즘은 단위테스트로,
컨트롤러는 통합테스트로 테스트 하는것이 정석이다.
도메인 유의성과 의존성 분리
지나치게 복잡한 코드 를 쪼개기 위한 개발 방법론들이 많다.
아래의 개발 방법론들이 모두 모두 도메인 유의성과 의존성(협력자)를 분리하기 위한 패턴들이다.
- 함수형 프로그래밍
- 단일 책임 원칙
- DDD
- MVC 패턴
- 헥사고날 아키텍처
빠른 실패 원칙
최대한 메서드 초기에 오류를 반환, 예외 던지는 코드를 작성해야한다.
예기치 않은 오류가 발생하면 현재 코드에서 더이상 진행하지 않고 바로 중단하는 것을 의미한다.
메서드 후반부에 오류를 반환하면 피드백 루프 단축, 지속성 상태 보호 가 되지 않을 확률이 높다.
- 피드백 루프 단축:
빠른 실패 원칙이 운영단계에서 버그가 발견되는 확률을 줄인다. - 지속성 상태 보호:
빠른 실패 원칙이 데이터(DB) 지속성 상태를 보호한다.
테스트 개선중 의미 없는 테스트 작성을 하지 않는것도 매우 중요하다.
빠른 실패 원칙을 통해 가치없는 테스트 작성을 하지 않도록 유도할 수 있다.
인터페이스와 느슨한 결합
구현체가 하나뿐인 인터페이스는 만들지 않는것이 좋다.
인터페이스를 사용한다고 추상화, OCP 원칙이 지켜지는 것은 아니다.
통합 테스트
프로젝트 규모가 클수록 협력자와 공유 의존성이 많아지기에 통합 테스트 또한 단위 테스트만큼 중요해진다.
아래의 단위 테스트의 목적 3가지를 충족하지 않는 테스트는 모두 통합 테스트이다.
- 테스트를 개발주기에 통합
- 제품코드의 가장 중요한 부분만을 테스트 대상으로
- 최소한의 테스트 코드로 최대의 가치
대부분의 통합 테스트는 공유 의존성을 필요로 한다.
공유 의존성이 포함되어 느리다 보니 단일 동작이 아니라 두개 이상의 동작을 같은 테스트에서 검증헤야 해서 두개 이상의 AAA 패턴 코드가 하나의 테스트 안에 포함될 수 있다.
또한 두개 이상 모듈의 일련의 연결과정을 테스트해야할 수 도 있다.
End-To-End 테스트
통합 테스트중 가장 비용이 높은 테스트라 할 수 있다.
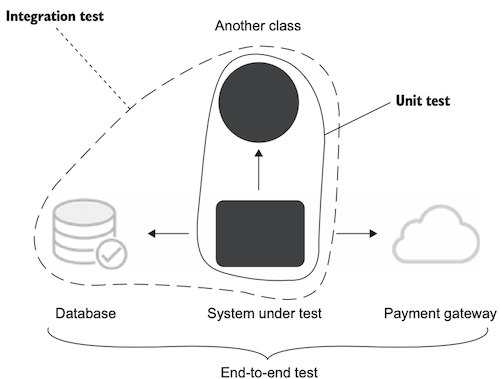
엔드투엔드 테스트 에선 대부분의 공유 의존성을 모두 포함한다.
통합 테스트는 대부분 공유 의존성 하나만 다룸
모든 단위 테스트와 통합 테스트를 모두 통과하고 마지막에 실행하는 것이 정석
테스트 피라미드
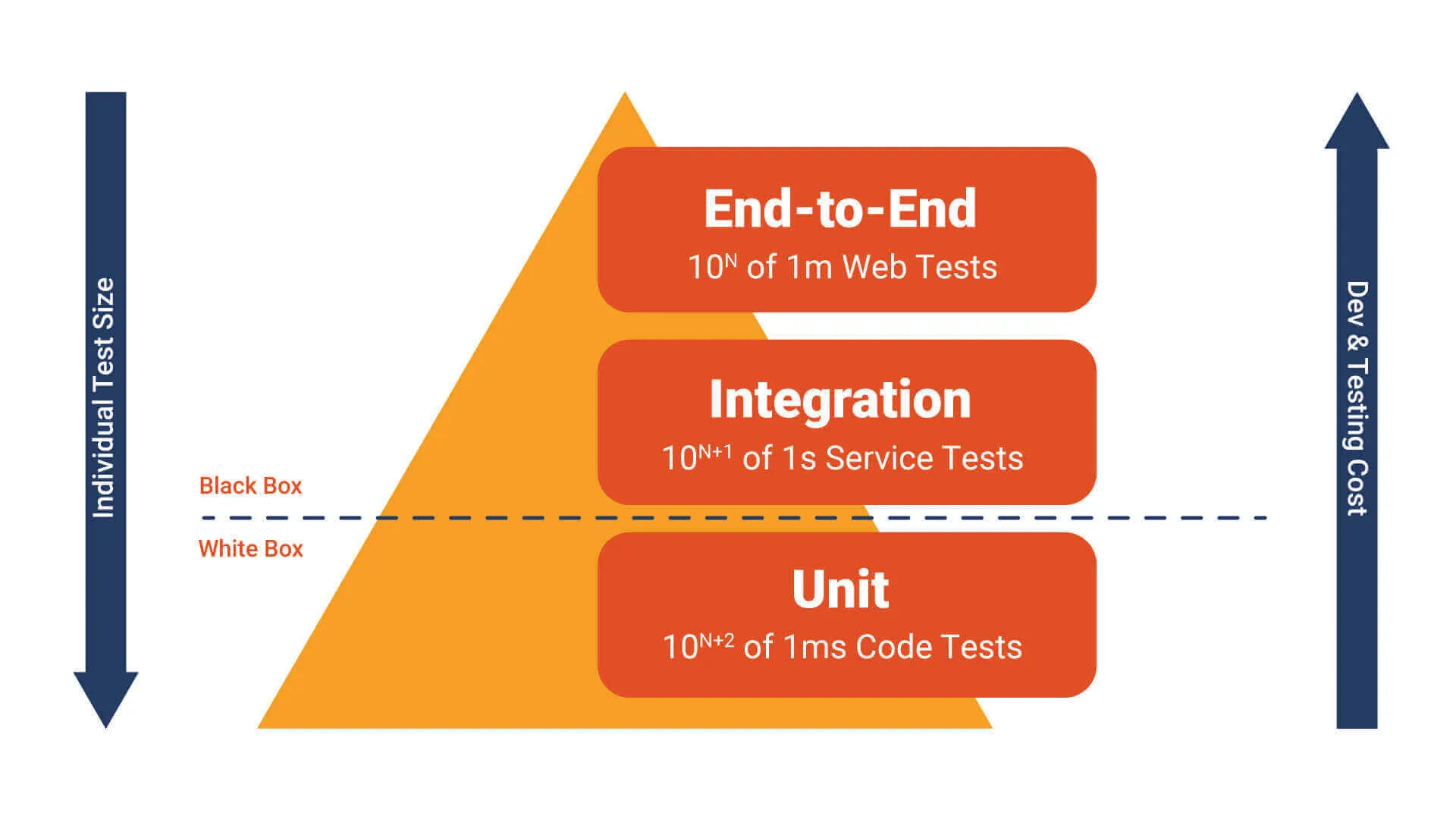
그림처럼 테스트 코드 개수가 많은순, 실행속도가 빠른순으로 줄새우면 아래와 같다.
unit(단위) > integration(통합) > end-to-end
end-to-end 는 입출력값만 검사하면 되기 때문에 회귀방지, 리펙터링 내성 모두 우수한 테스트 방법이지만 느린 테스트 속도와 안좋은 유지보수성으로 인해 가장 적은 수를 차지한다.
복잡도가 없는 CRUD 어플리케이션의 경우 알고리즘을 검사하는 단위테스트 보다 공유 의존성과의 통합이 잘 되어있는지 확인하는 것이 더 중요하다.
그래서 복잡도가 없다면 통합테스트가 단위테스트보다 많을 수 있다.
또한 공유 의존성이 DB 하나밖에 없다면(단일 외부 의존성) 통합테스트 대신 end-to-end 테스트를 사용해도 된다.
단일 외부 의존성의 경우 두 테스트간의 유지비 차이가 크지 않다.
단위테스트로 최대한 많은 비즈니스 시나리오를 검증하고,
통합테스트로 주요흐름과 특수한 예외상황만을 검증하는것이 정석이다.
white box, black box
단위 테스트를 기점으로 [white box, black box] 로 나뉜다.
white box는 내부 코드 실행을 검증하는 테스트 방식.black box는 내부구조를 몰라도 기능을 검증하는 테스트 방식.
명세-요구사항을 검증하는 테스트 방식이다.
코드설계를 생각없이 하면 모든 단위테스트는 white box 테스트가 되버림으로,
단위테스트, 통합테스트 상관없이 모두 black box 테스트 방식으로 운용할 수 있도록 코드설계가 필요하다.
통합 테스트 설계
외부 시스템 통신.
통합 테스트에서 프로세스 외부 의존성 상호작용을 검증하려면 최대한 긴 주요흐름 선택해서 테스트하면 된다.
하나의 긴 주요흐름으로 모든 프로세스 외부 의존성 상호작용 검증이 불가능하다면 통합 테스트 여러개 만들면 된다.
프로세스 외부 의존성 mock 조건.
어떤 프로세스 외부 의존성을 Mock 객체로 사용할지는 두가지 유형으로 선택할 수 있다.
-
관리 의존성: 전체 제어 가능한 외부 의존성.
외부에서 접근 불가능하고 어플리케이션에서만 접근 가능(제어)할 수 있는 의존성.
DB가 대표적인 예.
관리 의존성은 통합테스트에서 실제 인스턴스 사용을 권장한다.
최종 상태확인, 도메인 변경 리펙터링에 쉽게 대응 가능하기 때문이다.
만약 관리 의존성을 실제 인스턴스로 사용하지 못할경우 통합테스트 작성을 포기하고 단위테스트 작성에만 집중하는것을 권장한다. -
비관리 의존성: 외부의 여러 어플리케이션이 상호작용하는 의존성.
SMTP 서버, 메세지 브로커가 대표적인 예.
Mock으로 대체하기 좋다. 쉽게Mock으로 대체할 수 있도록 인터페이스 사용을 권장한다.
입출력값을 식별하기 편하고 대부분 어뎁터로 감쌓놓기에 하위 호환성 유지보수 비용도 적다.
계층 수 줄이기.
일부 어플리케이션은 좌측 그림과 같이 간접 계층(Abstract layer)을 추가해서 코드를 추상화하고 문제를 해결한다.
협력자가 하나 더 추가되며 테스트 환경도 안좋아지고 코드 깊이가 깊어지면서 숨은로직이 많아져 직관성도 떨어진다.
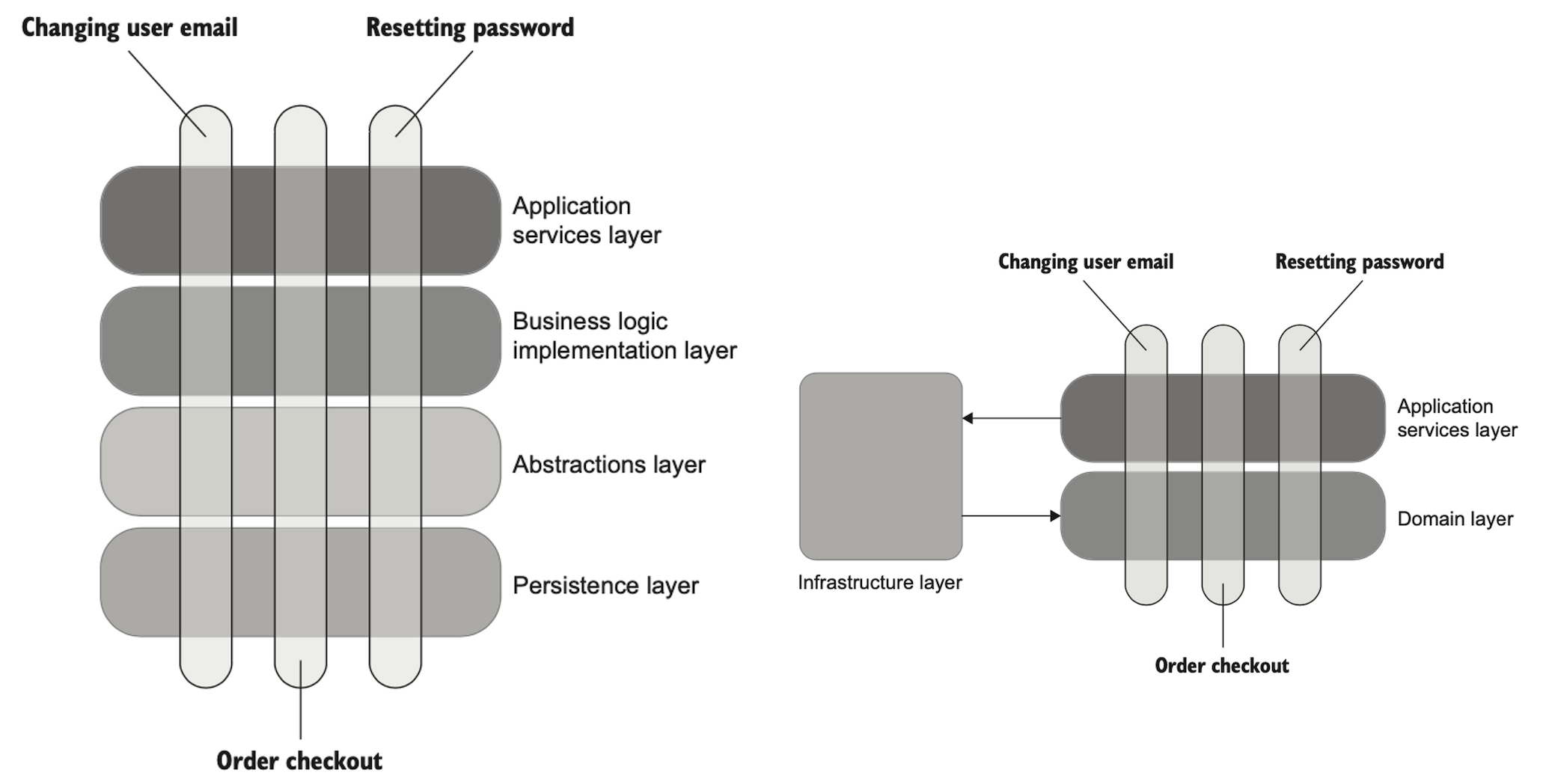
대부분의 백엔드 시스템에선 우측 그림처럼 [Infrastructure, Application, Domain] 3가지 계층만 활용하면 된다.
복잡한 알고리즘과 프로세스 외부 의존성은 Infrastructure 에서 구성하고 최대한 계층 깊이를 줄여야 한다.
Test Doubles(Mock, Stub)
스턴트 대역배우를 Stunt double 이라 부르는 것에 유래해서 테스트를위한 대역객체를 Test Doubles 라 부른다.
단위테스트 에서 Test Doubles 에 사용하는 단어는 [Mock, Stub] 2가지로 나뉜다.
CQS(command query separation), [행위, 상태] 를 기반으로 Mock 을 사용할지, Stub 을 사용할지 결정한다.
Query를 수행하는 의존성은Stub, 정해진 결과를 반환한다, 상태검증한다고 부른다.Command를 수행하는 의존성은Mock, 실제 행해졌는지 확인, 행위검증한다고 부른다.
Mock 의 경우 상태를 검증할 수 없는 외부로 데이터를 송신하는 외부 공유 의존성을 모방할 때 사용하고 행위만 검증한다,
Stub 의 경우 상태를 추측할 수 있는 내부로 데이터를 수신하는 내부 공유 의존성을 모방할 때 사용한다.
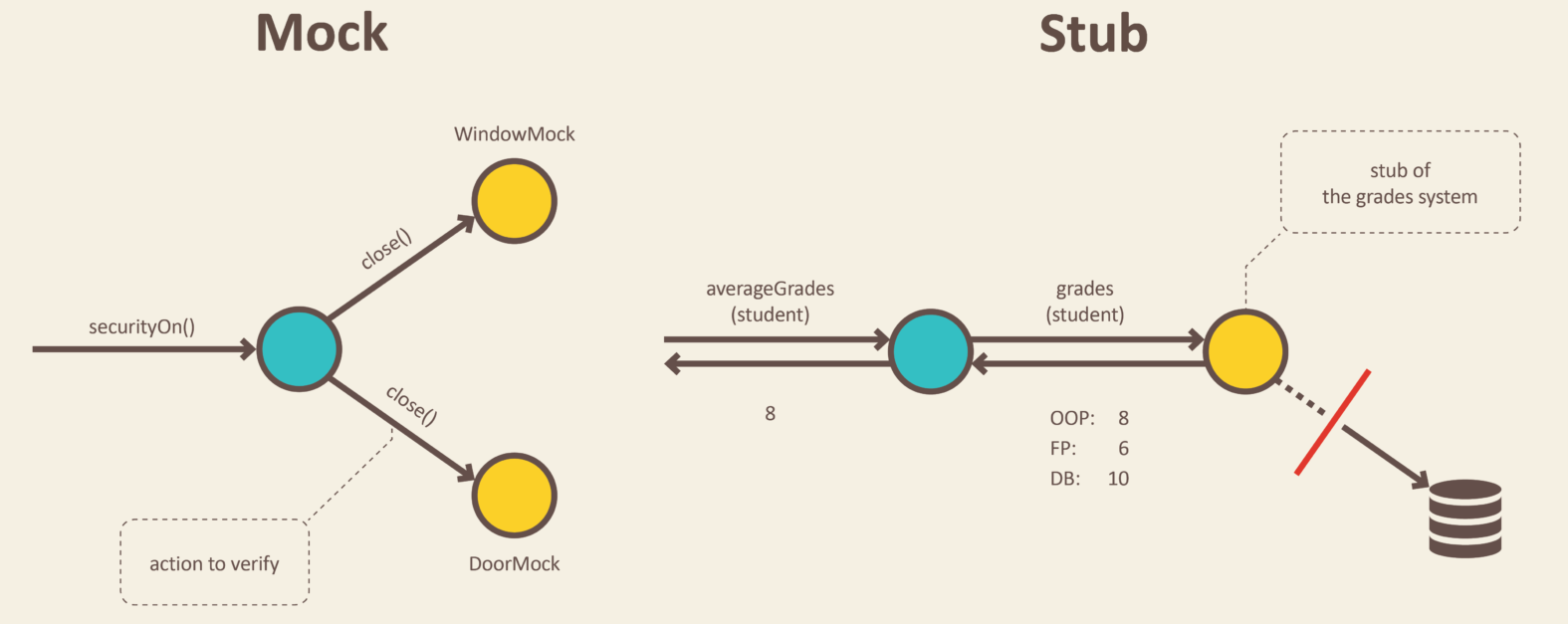
대부분 테스트 프레임워크에선 Mock 키워드로 행위만 검증하는 것이 아니라 상태값도 반환할 수 있도록 설정할 수 있기에
그냥 Mock 키워드로 [Mock, Stub] 테스트 코드를 모두 작성한다.
Spy, Fake
[Mock, Stub] 이 일부 함수만 대체하기 위한 Test Doubles 이었다면,
[Spy, Fake] 는 대체할 객체의 구현체로서 모든 함수를 대체하기 위한 Test Doubles 이다.
java 를 예로 들면, 해당 interface 의 구현체를 Test Doubles 로 사용하는 격이다.
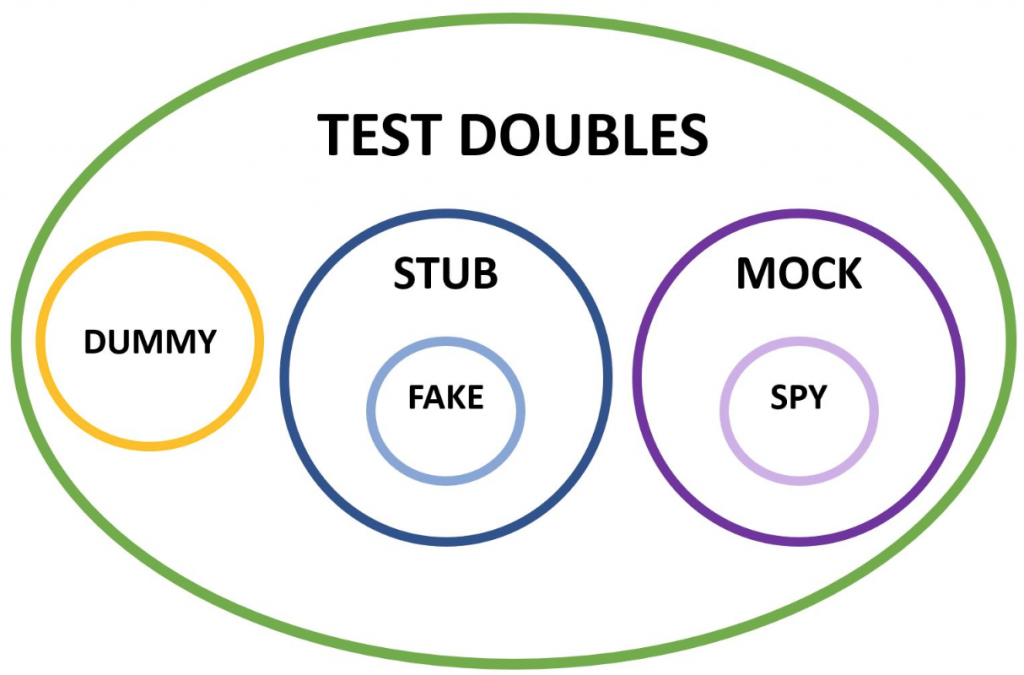
Dummy는void메서드만을 가진 객체를 테스트하기 위한 아무내용없는Test Doubles
Mock 의 가치 극대화하기
비관리 의존성을 최대한 분리하라.
대략 아래와 같이 이메일 호출 함수스택이 구성된다면
IEmailGateway -> EmailGateay -> SMTPClient -> sendEmail!
public interface IEmailGateway {
boolean sendGreetingEmail(String email);
}
@Component
@RequiredArgsConstructor
public class EmailGateway implements IEmailGateway{
private final SMTPClient smtpClient;
@Override
public boolean sendGreetingEmail(String email) {
return smtpClient.sendEmail(email, "hello word");
}
}
@Slf4j
@RestController
@RequiredArgsConstructor
@RequestMapping("/user")
public class UserController {
private final IEmailGateway emailGateway;
@PostMapping("/greet")
public boolean greetUser(String email) {
return emailGateway.sendGreetingEmail(email);
}
}
IEmailGateway 을 Mock 으로 설정하는것이 아닌 SMTPClient 를 Mock 으로 설정해서
최대한 비관리 의존성을 분리하고 Mock 으로 설정하라는 뜻이다.
SMTPClient 를 Mock 으로 설정함으로서 실제 수행되는 코드량이 더 많아짐으로 회귀방지에 강해진다.
Mock 대신 Spy 사용하기.
시스템 끝에 있는 클래스의 경우 Mock 보다 Spy 가 낫다.
대부분 끝단에 있는 비관리 의존성은 모든 메서드에 대해 Mock 으로 구성해야 하기 때문에 Spy 로 구성하는 편이 간결할 수 있다.
위의 SMTPClient 가 끝단의 비관리 의존성이라 할 수 있다.
sendEmail 함수가 늘어날수록 Spy 객체를 정의해두고 대체하는것이 효울적이다.
보유타입만 Mock으로 처리하기.
Spring Boot 에서 SMTP 클라이언트로 JavaMailSender 를 사용하는데
라이브러리에서 제공되는 의존성을 Mock 으로 처리하지 않는것을 권장한다.
항상 서드파티를 감쌓는 래퍼클래스를 정의하고 해당 래퍼클래스를 어댑터로 사용하는 것을 권장한다.
그리고 해당 어뎁터를 보유타입으로 생각하고 Mock 으로 테스트 해야한다.
DB 테스트
- DB 스키마를 코드로 형상관리하라.
참조데이터(사용자 등급, 타입 같은 고정 데이터) 스키마는 INSERT 쿼리까지 관리 - In-Memory DB 는 확실한 DB 테스트 진행이 아님으로 사용하지 않는것을 권장한다.
개발자별로 테스트 DB 인스턴스를 갖고있는 것을 권장한다.
테스트간 간섭, 실행속도 극대화 - 테스트간 트랜잭션은 최소 3 이상
[준비, 실행, 검증]생성하라
AAA패턴 과정중 트랜잭션간 테스트 데이터 간섭을 최소화 하기위해 - 제품코드 트랜잭션은 작업단위로 구성하고 테스트코드 트랜잭션도 작업단위로 생성하라.
- 테스트는 병렬처리보단 순차적으로 진행하라
병렬은 테스트 간섭을 해결하기 위해 너무 많은 노력이 필요함 - repository 테스트는 통합테스트 내에서 진행하도록 하고 별도의 테스트는 생성하지 않는다.
데이터 모션
데이터 모션(Data motion) 이란 DB스키마를 주순하도록 기존 데이터 형태를 변경하는 것.
name 칼럼을 [first_name, last_name] 으로 쪼개서 저장하는 과정을 예로들 수 있다.
스키마 업데이트 방식은 [상태기반DB, 마이그레이션기반DB] 로 나뉜다.
상태기반DB: 운영DB와 개발DB 같의 차이를 비교툴을 사용해 관리, 두 DB의 모든 동기화 작업이 비교툴이 생성한 SQL 을 통해 이루어진다.
마이그레이션기반DB: DB 스키마를 업데이트할 때 SQL 스크립트를 직접 작성해서 관리, SQL을 사용해도 되지만 마이그레이션용 DSL 언어를 사용하기도 한다.
데이터 모션의 경우 단순 스키마 변경이 아닌 데이터의 변경/이동 또한 같이 이루어지는데
마이그레이션기반DB 만이 이를 해결할 수 있다.
테스트 코드 재사용
아래와 같이 생성을 위한 비공개 팩토리 메서드를 사용
오브젝트 마더라는 이름으로 불린다.
private User createUser(String email, UserType type, Company company) {
User user = new User(email, type, "test-user", company);
user = userRepository.save(user);
return user;
}
만약 여러 테스트 클래스에서 해당 비공개 팩토리 메서드가 필요하다면
기초클래스와 상속을 사용하기 보단 별도의 컴포넌트 클래스를 배치하는 것을 권장한다.
기초클래스에는 반드시 실행되어야할 before all 과 같은 메서드만 존재해야한다.
만약 검증문에서 중복코드가 발생한다면 아래와 같은 fluent interface 작성을 해두는 것도 좋다.
public class UserExtensions {
public UserExtensions shouldExist(User user) {
Assertions.assertNotNull(user);
return this;
}
public UserExtensions withType(User user, UserType userType) {
Assertions.assertEquals(userType, user.getType());
return this;
}
public UserExtensions withEmail(User user, String email) {
Assertions.assertEquals(email, user.getEmail());
return this;
}
}
Coverage 지표
테스트 코드 지표로 사용하는 2가지 방법
테스트한 SUT 코드비율을 측정하기 위한 Test Coverage 지표
테스트한 SUT 코드 조건문비율을 측정하기 위한 Branch Coverage 지표
아래와 같은 코드가 있을 때
public static boolean isStringLong(String input) {
if (input.length() > 5)
return true;
return false;
}
@Test
void Test() {
boolean result = isStringLong("abc");
assertEquals(false, result);
}
isStringLong 메서드안의 코드수는 3줄, 그중 if 문 안의 한줄 빼고는 테스트 동작시 모든 코드가 실행된다.
따라서 Test Coverage 는 2/3=66% 이다.
분기중 하나만 테스트했음으로 Branch Coverage 가 50% 라 할 수 있다.
Coverage 오류
Test Coverage 가 높다고 해당 테스트 코드가 좋은 테스트 라곤 할 수 없다.
아래처럼 함수를 조금만 변경하면 Test Coverage 는 100% 가 되기 때문.
public static boolean isStringLong(String input) {
return input.length() > 5;
}
Branch Coverage 는 Test Coverage 보단 효과적이라 할 수 있겠지만 반환값의 분기만을 검증함으로
모든 코드를 검증했다고 볼 순 없다.
또한 복잡한 외부라이브러리 함수호출로 이루어진 코드를 테스트할 경우
라이브러리 안의 코드 모두 검증했다고도 할 수 없다.
따라서 Coverage 지표는 참고만 할 뿐 좋은 테스트의 조건으로 활용하면 안된다.
안티패턴
비공개 메서드는 테스트하지 않는다.
만약 비공개 메서드가 너무 커서 coverage 지표가 좋지않다면 추상화 부족이다.
비공개 메서드 내부 코드를 별도의 추상화 클래스로 분리해서 해당 추상화 클래스를 테스트하라.
테스트코드로 인한 도메인 유출 방지.
아래와 같은 Calculator 도메인이 있을 때
public static class Calculator {
public static double add(double value1, double value2) {
return value1 + value2;
}
}
테스트코드 내부에 해당 도메인 처리하는 도메인 지식이 포함되면 안된다.
도메인 지식을 테스트코드에 작성할 경우 잘못된 코드도 해당 테스트코드에 포함될 경우가 높으며
정확한 추측값을 토대로 테스트를 통과했다고 볼수 없다.
@Test
void Test() {
// 준비
double first = 10l;
double second = 20l;
double expect = first + second; // 도메인 지식이 코드로 유출
// 실행
double result = Calculator.add(first, second);
// 검증
Assertions.assertEquals(expect, result);
}
아래와 같이 하드코드된 예측값 사용을 권장한다.
@ParameterizedTest
@CsvSource(value = {
"10,20,30",
"3,5,8"
})
void Test(double first, double second, double expect) {
// 실행
double result = Calculator.add(first, second);
// 검증
Assertions.assertEquals(expect, result);
}